
Stream processing
In today’s fast-paced digital world, many data sources generate an infinite flow of data—a never-ending river of facts and numbers that are confusing when looked at individually but give deep insights when analyzed collectively. This is where stream processing comes into play. It bridges the gap between streaming data collection and actionable insights.
Stream processing is a continuous method of ingesting, analyzing, and processing data as it is generated. Unlike traditional batch processing, where data is collected and processed in chunks, stream processing works on the data as it is produced in real time. Actionable insights are readily available within seconds or even milliseconds of data generation. Other benefits include improved operational efficiency, user experience, and scalability.
This article explores the practical aspects of stream processing, delving into its fundamental concepts, developer challenges, best practices, and emerging trends.
Summary of key concepts
Stream processing | Stream processing bridges the gap between data collection and actionable insights in real time. |
Event-driven architecture | Design and structure of systems for handling discrete event data in applications, enabling real-time processing and response to events. |
Windowing | Segmenting data into time-based or count-based subsets for efficient analysis and aggregation. |
Messaging semantics | Meaning and interpretation of messages in distributed systems, ensuring clear and consistent communication. |
Exactly-once processing | Processing guarantee in stream processing systems, ensuring that each event or message is processed and applied to the system exactly one time. |
Importance of stream processing
Stream processing allows for invaluable real-time insights that make it important for various domains. Businesses can adjust their strategies, operations, and resources in real-time. It allows organizations to be more proactive regarding market changes, customer preferences, and operational changes leading to cost savings and revenue generation.
This agility in decision-making is a game changer in industries like ecommerce, where the recommendation systems use stream processing to analyze user behavior and provide personalized recommendations instantly. Whether in ecommerce, the service industry, or the media, the ability to quickly respond to customer behavior can lead to higher customer satisfaction and loyalty.
Another example is financial services, where you can use stream processing for fraud detection, identify suspicious transactions as they occur, and take immediate action to prevent potential financial losses.
The Internet of Things (IoT) is also an area where stream processing is indispensable. With the influx of IoT devices, stream processing allows immediate data processing generated by sensors and devices. This is especially helpful in ensuring the efficient use of resources and the swift response to device malfunctions and security breaches.
Fundamental concepts in stream processing
At its core, stream processing embodies an event-driven architecture that processes data as it arrives.
Event-driven architecture
It operates on the principle of responding to events as they occur, such as data arriving from sensors, user interactions, or other sources. Let's observe the diagram below to understand the architecture completely:
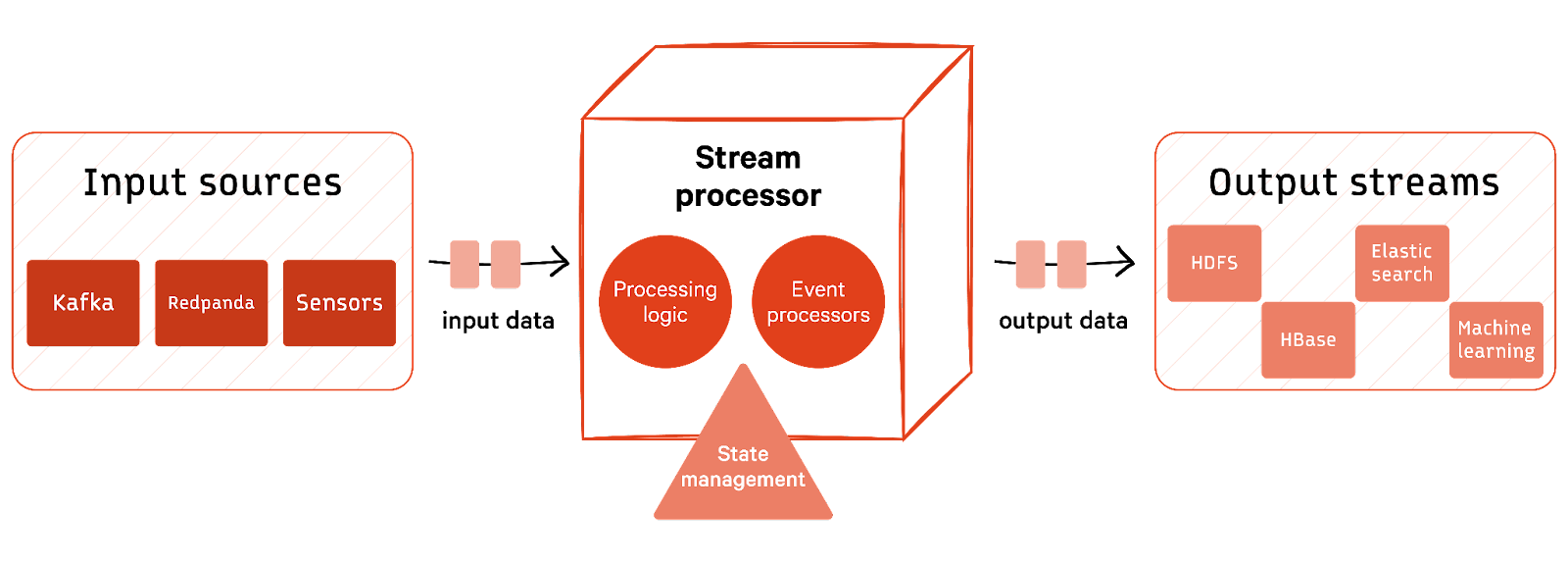
Input sources
Data is read from various input sources like social media platforms and IoT sensors or data ingestion platforms like Redpanda. These sources generate the events that serve as a trigger for the system and are ingested into the event-driven system.
Stream processor
The stream processor is the heart of the system, embodying the event-driven architecture. It efficiently handles continuous data flow, reacting to events in real-time. We will now discuss core concepts and techniques employed by stream processors for smooth data processing.
Processing logic
Stream processor uses processing logic to define rules that occur in response to specific events. It is implemented using programming languages like Java, Python, and Scala. This logic defines event-driven rules, enabling dynamic responses to incoming data. It aids in real-time analysis, conditional actions, and integration with external systems for comprehensive data processing.
State management
Stream processor is also responsible for state management that allows the architecture to keep track of its progress and maintain state information. This is crucial for scenarios like "exactly-once" processing, where it ensures that the same output is generated regardless of how many times the input stream is read. State management helps maintain context and supports complex computations.
Event processors & windowing
Stream processors often utilize event processors as part of their functionality in a crucial technique known as “windowing.” These event processors ensure continuous data flow by routing the events efficiently. They react to the event's time and assume the role of window builders. With each time interval, they create a new window to capture and evaluate the next batch of data. This makes this a key technique for handling real-time data streams.
Picture a real-time financial analysis system where stock prices fluctuate by a second. Event-driven architecture ensures that each stock price update triggers an event, and windowing slices these updates into one-second intervals. This way, the architecture becomes a conductor, directing the data flow for harmonious analysis within the one-second windows. This synchronization empowers real-time calculations, like average prices or trend predictions, and facilitates timely decision-making.
Processing computational model
Before the data reaches the output stream, the data undergoes analysis, transformation, and action, all executed by the processing computational model. It dictates how real-time data is effectively managed within the system. It is pivotal in ensuring stream processing applications efficiently manage data as it flows through the system, responding to events and extracting insights in real-time.
Output streams
Once the data is processed, it is typically written to output streams or storage systems like HDFS, Cassandra, HBase, or other databases. These output streams can be consumed by downstream applications or used for analysis and reporting.
Data consistency layer: messaging semantics
Though messaging semantics is not an inherent part of the stream processing architecture, it is essential to ensure data consistency and integrity. Messaging semantics form the language of communication in stream processing.
These semantics define how messages are sent, received, and processed within the systems while emphasizing the important aspects of ordering, reliability, and delivery. They also ensure that data is handled with precision and accuracy, thus enabling developers to address data consistency and reliability challenges.
In messaging semantics, "exactly once" and "at least once" serve as guiding principles. "Exactly once" processing ensures that each event is processed only once, eliminating duplicates entirely and aligning with messaging semantics' precision and integrity goals. On the other hand, "at least once" processing, while guaranteeing event processing, allows for occasional redundancy. Both of these concepts are explained in detail in the next section.
Stream processing challenges for developers
Developers face a myriad of challenges in stream processing to ensure that the system works just as well as in practice. They have to ensure fault tolerance and data consistency, address privacy and security concerns, and overcome latency issues for real-time processing. They need to consider the following.
Diverse data serialization formats
The input data comes in different serialization formats like JSON, AVRO, Protobuf, or Binary. Developers have to handle data encoded in different formats and deserialize it; otherwise, system failure could occur.
As an example, let’s define a function deserialize_json_data that deserializes JSON data. It tries to parse the JSON data and, if successful, returns the deserialized data. If there's a JSON decoding error, it handles it and returns None.
import json
# Deserialize JSON data
def deserialize_json_data(json_data):
try:
deserialized_data = json.loads(json_data)
return deserialized_data
except json.JSONDecodeError as e:
# Handle JSON decoding error
return None
# Example usage
json_data = '{"name": "John", "age": 30, "city": "New York"}'
deserialized = deserialize_json_data(json_data)
if deserialized:
print("Deserialized Data:", deserialized)
else:
print("Error: Unable to deserialize JSON data")Schema variability
Stream processing developers often grapple with the challenge of handling diverse data schemas from various sources. These schemas can differ in field names and structure, making it necessary to harmonize data for consistent processing. Developers must skillfully map and adapt these varied schemas to ensure the smooth integration and analysis of data from multiple sources. This involves addressing differences in schema definitions and naming conventions, requiring flexibility and attention to detail to navigate the complexities of real-world stream processing. In the code below, we have a very simple Python code that does exactly that:
def map_schema_fields(data, source_schema):
if 'CustomerID' in source_schema:
return data['CustomerID']
elif 'customerId' in source_schema:
return data['customerId']
elif 'CustID' in source_schema:
return data['CustID']Delayed data arrival
Dealing with data that arrives out of order or with delays due to network latency presents another challenge for developers. To address this, developers must ensure that late-arriving data is seamlessly integrated into the processing pipeline, maintaining the integrity of real-time analysis and decision-making.
def handle_late_data(data, processing_time):
event_time = data['event_time']
if event_time > processing_time:
# Store for later processing or update processing time
return event_time
else:
# Process the data immediately
process_data(data)In this above code, we are trying to handle late-arriving data by comparing the event time in the data to the current processing time and either storing it for later processing or immediately processing it based on the comparison. This way, the data is seamlessly integrated into the pipeline.
Ensuring exactly-once processing
Stream processing developers face the challenge of ensuring "Exactly Once Processing," which guarantees that each event or piece of data is processed and recorded just once, eliminating duplicates. This is critical for maintaining data consistency and preventing over-processing of information. Achieving exact-once processing requires careful handling of offsets and checkpoints to track the state of processed data and guarantee its reliability.
processed_data = set() # To store processed data
def process_data(data):
# Check if the data has already been processed
if data not in processed_data:
# Process the data
print("Processing:", data)
# Add the data to the processed set
processed_data.add(data)
# Simulated stream of data
stream_data = [1, 2, 3, 2, 4, 1, 5]
for data_point in stream_data:
process_data(data_point)In the simplified example above, a processed_data set tracks data already processed. The process_data function examines incoming data, processes and prints it if it hasn't been processed before, and records it in the processed_data set. The code operates on a simulated data stream, which might include duplicates, and guarantees that each data point is processed exactly once by filtering out duplicates.
Ensuring at-least once processing
In parallel, achieving "At-Least Once Processing" means ensuring no data is missed, even if there might be some duplication in extreme cases. To attain these processing guarantees, developers employ meticulous techniques, such as managing offsets and checkpoints to track the state of processed data and ensure its reliability.
import time
import random
stream_data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Function to process data with potential errors
def process_data(data):
if random.random() < 0.3:
# Simulate an error condition (30% chance)
print(f"Error processing data: {data}")
return False
else:
# Simulate successful processing
print(f"Processing data: {data}")
return True
# Simulate processing of stream data with retries
for data_point in stream_data:
success = False
while not success:
success = process_data(data_point)
if not success:
print(f"Retrying data: {data_point}")
time.sleep(1) # Simulate processing time
print("Processing complete")In the above code example, we simulate a data stream and introduce a 30% chance of encountering an error during stream processing. When an error occurs, the code simulates a retry until the data is successfully processed, ensuring at-least-once Processing. The random nature of errors and retries mimics real-world scenarios where data requires processing more than once to guarantee it's not lost due to occasional errors.
Other complexities
Developers also face the challenge of adapting stream processing operations to meet dynamic business demands for better outcomes. This includes designing for fault tolerance and efficient resource allocation. The system should handle varying workloads while ensuring stability and reliability.
Developers must also protect sensitive data in production settings where direct access is often limited. This constraint can make it tough to troubleshoot and query data, demanding the implementation of strong security measures and access restrictions.
Stream processing best practices for developers
Developers can achieve optimum performance and reliability in stream processing systems by following a set of best practices. These strategies include:
Strategies for minimizing IO and maximizing performance
One of the primary best practices for stream processing is to minimize IO operations. This entails reducing the amount of data read and written to disk, as disk IO is typically a bottleneck. By implementing techniques like micro-batching and efficient serialization, developers can significantly enhance the performance of their stream-processing applications. This practice ensures data moves swiftly through the system and reduces processing overhead.
# Function to process data in batches
def process_data_batch(data_batch):
# Processing logic for the batch of data
for data_point in data_batch:
process_data(data_point)
stream_data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
batch_size = 3
# Process data in batches
for i in range(0, len(stream_data), batch_size):
data_batch = stream_data[i:i + batch_size]
process_data_batch(data_batch)This code snippet illustrates the best practice of microbatching to minimize IO. It processes data in small-size batches, reducing the number of IO operations and improving system performance. By incorporating such practices, developers can enhance the efficiency and responsiveness of their stream processing applications.
Data distribution, partitioning, and sharding
Efficient data distribution is crucial in stream processing. Developers use partitioning and sharding data across different processing units to achieve load balancing and parallelism. This helps in scaling the application and ensuring that data is evenly distributed, preventing hotspots and optimizing resource utilization.
# Simulated stream data
stream_data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Number of processing units
processing_units = 3
# Partition data into processing units
partitioned_data = [stream_data[i::processing_units] for i in range(processing_units)]
# Simulate processing on each partition
for unit, data in enumerate(partitioned_data):
print(f"Processing unit {unit}: {data}")In this example above, we have a simulated stream of data (stream_data) and three processing units (processing_units). The code partitions the data into three segments to distribute the workload evenly.
Incorporating in-memory processing for low-latency data handling
In-memory processing is a key strategy for achieving low-latency data handling in stream processing. By storing frequently accessed data in memory, developers can reduce access times and boost system responsiveness. This practice is particularly beneficial for applications that require real-time processing and low-latency responses. The code example below does exactly that by creating in-memory cache to store data that can be accessed easily with little to no latency.
# Create an in-memory cache to store frequently accessed data
memory_cache = {}
# Store data in memory
key = "user123"
data = {"name": "John", "age": 30, "city": "New York"}
memory_cache[key] = data
# Retrieve and process data from memory
if key in memory_cache:
cached_data = memory_cache[key]
print("Processing data from memory:", cached_data)Emerging trends in stream processing
Let’s now dive into the newest and transformative trends in stream processing.
Artificial intelligence
Downstream AI tools have fueled an increased demand for stream processing data. As organizations harness the power of artificial intelligence to drive insights and automation, the need for real-time, continuous data processing has become paramount. Stream processing facilitates the seamless integration of AI-generated insights into downstream applications, enhancing decision-making, automating processes, and providing timely alerts. The agility of stream processing ensures that AI models receive the most up-to-date data, allowing downstream tools to deliver accurate and relevant outcomes.
Edge computing
Edge computing has also gained prominence as IoT devices generate vast amounts of data that require real-time processing. Edge computing involves processing data closer to the data source, reducing latency, and conserving bandwidth. So for streaming data, edge computing can be the key to getting quick, real-time insights from the heaps of data right at the source. Serverless computing is another new trend that simplifies stream processing by abstracting infrastructure management and scaling automatically. It allows developers to focus on code and logic rather than operational concerns.
WASM
There is a newer trend of adopting WebAssembly (WASM) or similar technologies to address the issue of data usage along complex message flow. In stream processing, ensuring data sovereignty and preventing data duplication is a growing concern.
Integrating directly with data lake or lakehouse-oriented systems can lead to the "Iceberg problem," where a large portion of data remains unused or underutilized that WASM helps to solve. This trend recognizes the need for efficient data governance and utilization, making it paramount for stream processing solutions.
WASM has also allowed for a few technological strides that will shape the future of stream processing as we know it. A notable illustration is the introduction of the "Data Transforms Sandbox" by Redpanda, a contemporary data ingestion platform.
This sandbox represents a revolutionary shift, transforming Redpanda from a cost-efficient data streaming tool into an integrated platform capable of executing common data processing tasks across end-to-end streaming pipelines. This development signifies a glimpse into the future of technology, where data ingestion and processing seamlessly converge, enabling the rapid delivery of curated data products to operational and analytical applications within milliseconds!
Have questions about Kafka or streaming data?
Join a global community and chat with the experts on Slack.
Conclusion
Stream processing is a game-changer, allowing organizations to crunch and understand data in real-time. It's a leap ahead from old-fashioned batch processing methods offering speed and agility. It's all about delivering real-time insights and innovation, and it's just getting started.
