
Event streaming
In today's dynamic technological landscape, swift and real-time data processing is critical for organizations. Event streaming has become a pivotal technology in scenarios where timely insights and actions based on data are critical.
Event streaming refers to capturing and processing events in real time. These “events” can range from user interactions on a website, sensor readings in an IoT (Internet of Things) network, financial transactions in a banking system, etc. Events capture and transfer state changes among systems.
At its core, event streaming involves the continuous, unidirectional flow of events from producers to consumers. Producers generate events, and consumers process and respond to these events in real time.
This article explores event streaming patterns and other implementation considerations for collecting and processing event data.
Summary of key event streaming concepts
Feature | Description |
|---|---|
Event streaming | The real-time capture and analysis of data streams. |
Publish-subscribe pattern | Producers send events to a central hub (broker), and multiple consumers receive relevant events based on their interests. |
Event sourcing pattern | The persistence of state as a sequence of events enables the reconstruction of the application's state by replaying these events. |
CQRS pattern | Separates the command (write) and query (read) responsibilities of a system by maintaining two distinct models—one optimized for reading and another for writing. |
Replayability and backfilling | Replaying historical events for system testing or populating new features, contributing to system robustness and flexibility. |
Real-world event streaming use cases
Event streaming is useful in many scenarios involving continuous, real-time data flow. Let’s look at a few real-world use cases:
Fraud detection
Financial institutions use event streaming to detect and prevent fraudulent activities in real time. By analyzing a continuous stream of transactions, anomalies and patterns indicative of fraud, like unusually large transactions, multiple transactions from different locations in a short time frame, or other suspicious patterns, can be identified immediately.
Personalized customer experiences
In e-commerce, event streaming creates a personalized customer experience. User interactions, such as clicks, searches, and purchases, are captured as events. The data is then used to analyze user behavior in real time, allowing businesses to provide personalized recommendations, and targeted advertisements.
IoT (Internet of Things)
In IoT applications, event streaming is utilized for predictive maintenance. Sensors on equipment continuously generate events related to temperature, vibration, and other operational parameters. Analyzing these events in real-time makes it possible to predict when machinery or devices are likely to fail, enabling proactive maintenance, reducing downtime, and preventing costly equipment failures.
Healthcare
In healthcare, event streaming is employed for real-time patient monitoring. Medical devices and sensors generate continuous data related to vital signs, patient conditions, and treatment responses. Event streaming allows healthcare providers to monitor patients in real time, detect anomalies, and trigger immediate alerts or interventions in case of critical events. This can be particularly crucial in intensive care units or remote patient monitoring scenarios.
Getting started with event streaming
Traditional batch processing operates on bounded data sets in batches rather than individually. In contrast, event streaming reacts to data in real time, responding to individual occurrences as they happen. Event-driven systems typically employ message queues or streaming platforms to capture and process data as it streams in.

Event streaming offers several advantages over traditional batch processing approaches. For example,
Enables data processing as it arrives, allowing for real-time analysis and decision-making.
Promotes decoupling between components, allowing for modularity, independent development, and easier deployment and maintenance.
Provides resiliency and recovery features if the events are durable.
Factors to consider
When selecting between event-driven and batch processing, several factors should be considered:
Latency requirements
Event-driven processing excels in scenarios demanding low latency, where immediate responses or actions are critical. Batch processing, on the other hand, is suitable for tasks that can tolerate some latency.
Resource availability
Since batch processing data sets are bounded, we can pre-determine compute resources and plan for the workload. In contrast, streaming workloads can be unpredictable.
Data consistency
Event-driven processing may introduce complexities in ensuring data consistency across multiple data sources. Events are often processed asynchronously and independently. For example, if two events occur nearly simultaneously in different parts of the system, they might lead to conflicting data changes that are challenging to reconcile.
Batch processing, with its sequential nature, provides better data consistency guarantees. Since it processes data in a controlled, sequential manner, it's easier to maintain a consistent state across all data sources. For instance, a batch process might update several databases overnight, ensuring that all changes are based on the same set of data and are applied in a predictable order.
Application complexity
Event-driven systems can be more complex to design and maintain due to their asynchronous nature and reliance on messaging infrastructure. Batch processing systems are simpler to understand, implement, and manage.
Ultimately, the choice between event-driven processing and batch processing depends on the application's specific requirements and the data's nature. Event-driven processing is the defacto approach in real-time scenarios, while batch processing excels in handling large volumes of data with lower latency requirements.
Combining event streaming and batch processing
There may also be scenarios when neither one of the two approaches seems fit for the problem at hand. For instance, consider a customer recommendation system. An event-driven approach would react to individual customer interactions, providing personalized recommendations in real-time.
However, this level of granularity may only be necessary for some scenarios and can be an overkill. Ideally, we would want to process customer interactions in batches every few minutes, providing “near-real-time” recommendations while reducing complexity and resource demands.
Microbatching is a hybrid approach in such cases, aiming to bridge the gap between event-driven and batch processing. It involves processing data in small batches, typically with millisecond-to-minute intervals, and offers near-real-time processing with fewer complexities. Microbatching is particularly useful for applications that require low latency but not necessarily true real-time processing. It offers a middle ground with reduced complexity compared to fully event-driven systems.
Popular frameworks like Apache Spark™ and Apache Flink® support microbatching.
Event streaming patterns
Event processing patterns provide practical solutions for efficiently handling and responding to various events. This section discusses a few such common patterns.
Publish-subscribe
The publish-subscribe pattern involves a central hub (message broker) that facilitates communication between producers (publishers) and consumers (subscribers). Producers send events to the hub without knowing who or what receives them. Consumers can “subscribe” to specific event types and receive relevant events. This decoupling enables a scalable and flexible system where components can evolve independently.
It can be largely categorized into three main steps:
A publisher publishes a message on a topic.
The message broker receives the message and routes it to all of the subscribers who have subscribed to that topic.
The subscribers receive the message and process it.
Let’s look at an example implementation in Python using RabbitMQ that showcases how a producer broadcasts a message to all consumers and how a consumer consumes the published messages.
# Producer
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='msg-test', exchange_type='fanout')
message = "Hello, subscribers!"
channel.basic_publish(exchange='msg-test', routing_key='', body=message)
connection.close()
# Consumer
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='msg-test', exchange_type='fanout')
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='msg-test', queue=queue_name)
def callback(ch, method, properties, body):
# Logic for handling received messages
print(f"Received: {body}")
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
print('Waiting for messages to consume….')
channel.start_consuming()
Event sourcing
Event sourcing is a powerful pattern where the current state of an application is derived by replaying events from the beginning. Instead of persisting the current state in a database, events representing state changes are stored. The application can then rebuild its state by replaying these events.
So, event sourcing provides a fail-safe way to design systems and bring a system back to a past state when needed.
class Account:
def __init__(self, account_id):
self.account_id = account_id
self.events = []
def deposit(self, amount):
event = DepositEvent(self.account_id, amount)
self.events.append(event)
def withdraw(self, amount):
event = WithdrawalEvent(self.account_id, amount)
self.events.append(event)
def get_balance(self):
balance = 0
for event in self.events:
if isinstance(event, DepositEvent):
balance += event.amount
elif isinstance(event, WithdrawalEvent):
balance -= event.amount
return balance
class DepositEvent:
def __init__(self, account_id, amount):
self.account_id = account_id
self.amount = amount
class WithdrawalEvent:
def __init__(self, account_id, amount):
self.account_id = account_id
self.amount = amount
class EventStore:
def __init__(self):
self.events = []
def save(self, event):
self.events.append(event)
def get_events_for_account(self, account_id):
events = []
for event in self.events:
if event.account_id == account_id:
events.append(event)
return events
if __name__ == "__main__":
account = Account("55625172")
account.deposit(200)
account.withdraw(50)
event_store = EventStore()
event_store.save(DepositEvent(account.account_id, 200))
event_store.save(WithdrawalEvent(account.account_id, 50))
# Getting entire state from events
events = event_store.get_events_for_account(account.account_id)
for event in events:
print(event)
balance = account.get_balance()
In this example, the EventStore class is responsible for storing events. The get_balance() method of the Account class reconstructs the current state of the account by replaying all of the events associated with that account.
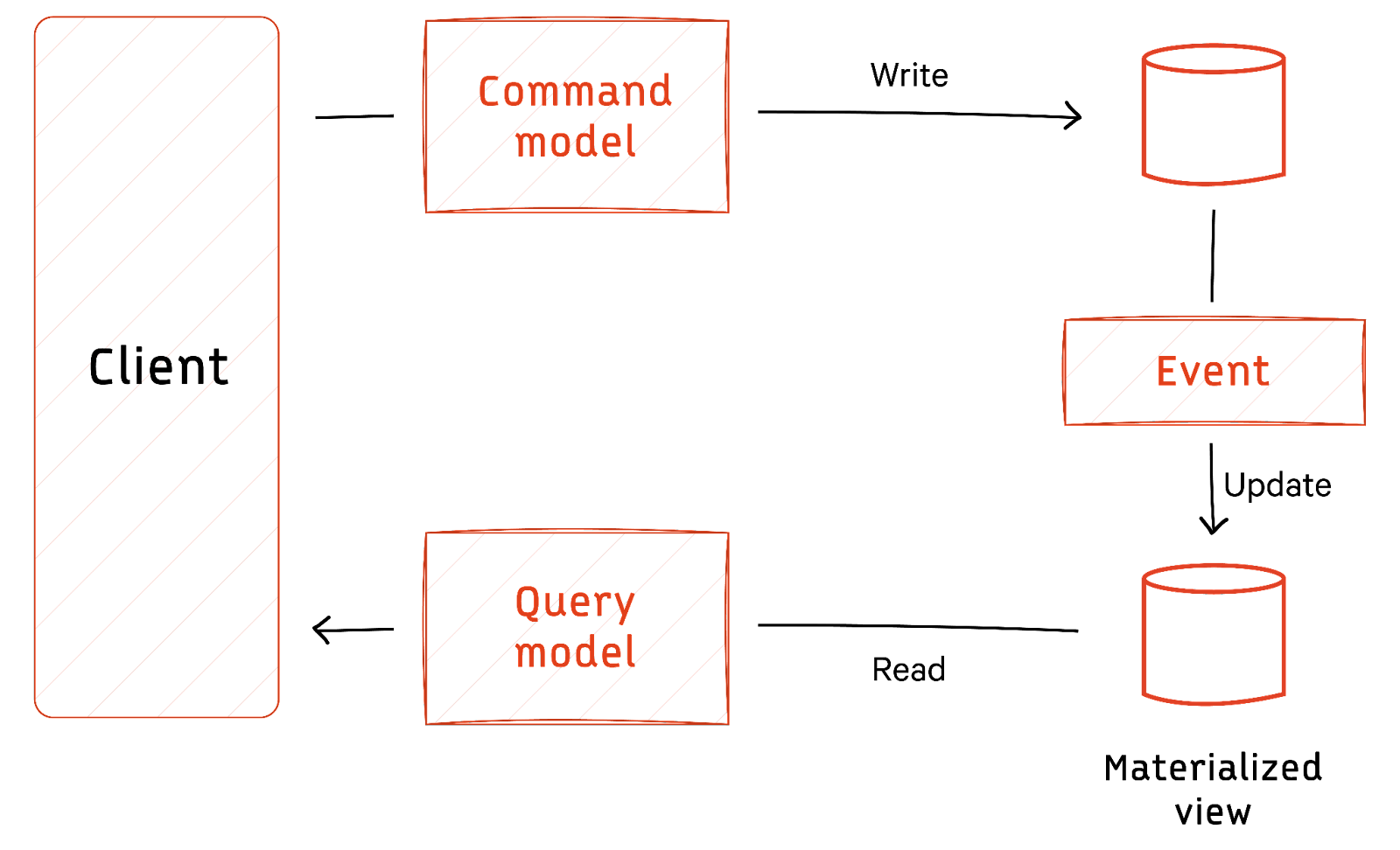
CQRS
Command Query Responsibility Segregation (CQRS) is an architectural pattern that separates the command (write) and query (read) responsibilities of a system. It suggests maintaining two distinct models—one optimized for reading and another for writing.
Commands update the write model, and queries retrieve data from the read model. This separation allows for each model's independent scaling, optimization, and maintenance.
While it introduces complexity, especially regarding synchronization between models, CQRS is beneficial in scenarios where read and write requirements differ significantly, enhancing performance and flexibility.
Other important considerations in event streaming system design
Event streaming systems require the following additional considerations for increased efficiency.
Stateful vs. stateless processing
Stateful processing maintains the state, or context, of data as it flows through the system. The system keeps track of the previous interactions or changes that have occurred.
For instance, if it's processing a data stream, it might remember the last processed point or maintain a summary of the data seen so far. Stateful processing is useful in use cases related to fraud detection, anomaly analysis, and user session management that require maintaining historical context.
In contrast, stateless processing handles each event independently without retaining any memory of previous interactions. Every event is processed in isolation. Stateless processing shines in scenarios where data is self-contained, and every event can be considered an individual occurrence—such as high-volume, short-lived data streams, real-time analytics, and event-driven applications.
The choice between stateful and stateless processing depends on the specific requirements of the application and the nature of the data being processed.
Sync vs. async processing
Synchronous processing adheres to a sequential order, where each task or operation must be completed before the next one can commence. This approach ensures a clear progression through the event data pipeline, making it well-suited for tasks with dependencies or when data integrity is paramount. However, synchronous processing can become a bottleneck if certain tasks are time-consuming and may cause delays.
In contrast, asynchronous processing embraces parallelism, allowing multiple tasks to run simultaneously without waiting for each other to finish. This non-blocking approach enhances throughput and responsiveness, particularly for data pipelines that involve long-running operations or network interactions. Asynchronous processing enables efficient utilization of computing resources but may introduce complexities in task coordination and error handling.
The selection between synchronous and asynchronous processing in event streaming depends on the data's nature, the processing pipeline's complexity, and the desired performance goals. Synchronous processing is often preferred for tasks with strong dependencies or when strict data consistency is required. Asynchronous processing, on the other hand, is a better choice when dealing with independent tasks.
Upcoming trends in event streaming
The broader adoption of event streaming beyond traditional use cases emphasizes the need for more versatile and robust event streaming platforms that can handle diverse and complex scenarios.
AI/ML integrations
By incorporating AI and ML algorithms into event streaming platforms, organizations can derive more sophisticated insights in real time. Predictive analytics, anomaly detection, and automated decision-making have become feasible, enabling systems to respond to events and proactively anticipate and adapt. This trend signifies a shift towards more intelligent event processing systems.
Edge computing
Edge devices generate significant event data that can be summarized locally, reducing latency and bandwidth requirements. Decentralized event processing allows critical decisions to be made closer to the data source. This trend is particularly relevant in IoT scenarios.
Cloud-native solutions
Cloud-native event streaming solutions leverage the scalability, elasticity, and managed services provided by applications designed to run in the cloud. Notably, Redpanda has emerged as a frontrunner in offering a scalable and fault-tolerant event streaming platform for organizations of all sizes.
Redpanda is a simple, powerful, highly scalable, and cost-efficient streaming data platform compatible with Apache Kafka® APIs—while eliminating Kafka complexity. It comes built-in with a human-friendly CLI and a rich UI that simplifies working with real-time event data.
For example, Redpanda uses cloud object storage (Amazon S3 or Google Cloud Storage) as the default storage tier. This enables it to deliver new capabilities like intelligent tiered storage and manage and distribute petabytes cost-efficiently and with minimal administrative overhead.
Have questions about Kafka or streaming data?
Join a global community and chat with the experts on Slack.
Conclusion
Event streaming is increasingly critical in modern data architectures and applications. As the volume, velocity, and variety of application events grow, event processing becomes even more essential for businesses to gain insights, make informed decisions, and drive operational efficiency. While this article introduces event streaming, we’ll soon publish a detailed guide on the intricacies of event stream processing. Stay tuned!
