
Real-time data analytics
Real-time data analytics has recently risen to prominence because of powerful IT infrastructure becoming more affordable thanks to cloud computing and the emergence of high-performance data processing frameworks that abstract complex algorithms.
Real-time analytics involve processing data as it’s generated and delivering insights for decision-making as soon as events happen. This helps organizations respond to the changing external environment, and deliver real-time insights or alerts to end users.
This article provides a brief introduction to real-time data analytics, how it differs from batch processing, and possible reference architectures to implement it.
Summary of key real-time data analytics concepts
Concept | Description |
|---|---|
Real-time data analytics | Real-time data analytics processes data as soon as it is generated and emphasizes the freshness of derived insights. |
Real-time data analytics architectures | Real-time analytics can be implemented by using streaming platforms and real-time analytics databases. |
Streaming data platforms | Streaming data platforms ingest high-throughput data and make them available for processing. Stream processors execute real-time window-based aggregations to derive insights. |
Real-time data analytics databases | Real-time analytics databases possess enough memory and querying ability to run complex logic combining incoming data with accumulated long-term data. |
Understanding real-time data analytics
Real-time data analytics is about processing events as soon as they happen and reporting based on them. Events are data points generated by user actions or happenings in the external world that the organization is dealing with.
For example, for a financial organization, event data can come from currency rate fluctuations or changes in the prices of commodities in the international market. For an e-commerce organization, events can originate from user actions on the website.
Processing logic in real-time analytics can be a database query, a complex algorithm, or a machine learning model inference. Depending upon the complexity of the task at hand, the processing operation can be time-consuming and require expensive infrastructure.
For example, running a simple query to generate an alert based on incoming data over a small window may be straightforward. However, the infrastructure complexity increases if the operation requires combining the incoming data with a large amount of historical data and then running a query or model inference.
You can measure the effectiveness of real-time analytics in terms of latency. It provides a measure of the freshness of data considered in the analysis. Latency can be of two types - data latency and processing latency.
Data latency refers to the time it takes for data to be available for processing after an event occurs. This includes the data transfer delay and any preprocessing and write delays that may occur before data is available for analysis. Processing latency is the time spent on the data to derive insights after it has reached the system. Both kinds of delays are non-ideal in a real-time analytics pipeline. But depending on the use cases, one of the delays may be easier to reduce, and the architectural choices in this domain are often related to prioritizing one over the other.
Real-time data analytics vs. batch processing
Real-time data analytics differs from traditional batch-based analytics in the sense that it is triggered by events rather than by time. Batch processing relies on the periodic running of processes rather than being triggered based on events.
Results from batch processes are much slower than real-time analytics results. Typical batch process frequency is in terms of hours or days. However, the advantage is that batch processing can better use infrastructure and achieve high throughput. You can optimize storage requirements by taking advantage of compression. Since data is not immediately accessed, the accumulated data can be stored optimally and later retrieved for processing.
In recent times, infrastructure becoming cheaper has led to a reduction in the use of batch-based pipelines. In practice, real-time data analytics may also run based on micro batches or batch processes that run more frequently.
Real-time data analytics use cases
Real-time analytics use cases can be divided into two broad categories depending upon the audience for whom the analytics is targeted.
Real-time business intelligence
Business intelligence use cases can vary from simple alerts or short-time window-based aggregations to ones that require combining real-time data with historical data. They often require generating reports and visualizations based on user-generated data.
The audience here is the higher management personnel or analysts who make strategic decisions based on how the users interact with their organization. Their latency requirements are a lower priority than user-facing analytics. Since the target audience here is smaller in number and cares mostly about pre-calculated metrics, concurrency requirements are also much lower.
For example, in a financial institution, every user's transactions get aggregated with the past transactions made by all users to get a real-time view of monthly, quarterly, and yearly performance.
User-facing analytics
User-facing analytics deals with real-time insights that go directly to the end users. Such analytics are more complex than traditional business intelligence because the insights are sent to millions of users simultaneously based on various criteria. The users may also choose to modify multiple parameters related to insights. Hence, user-facing analytics require much more processing power than real-time business intelligence.
User-facing analytics exists in many domains like finance, social media, e-commerce, etc. For example, a stockbroker provides real-time insights into how well one’s assets are performing and provides real-time reports. The users can tweak many elements of the reports, making the backend operations all the more complex.
Another example of user-facing analytics is in e-commerce personalization. The user’s current actions are compared in real time with past interactions through a logic or model inference to predict subsequent actions and offer a personalized experience on the website.
Implementing real-time data analytics
Implementing real-time analytics requires several foundational components to store incoming high-speed data and process them within the required time frame (usually governed by service level agreements). Broadly, a real-time analytics architecture consists of two key components.
Streaming data platform
Real-time analytics database
Streaming platforms
A streaming platform facilitates receiving high-speed data, storing it, and making it available for processing. One must choose a scalable streaming platform optimized for high throughput use cases to implement a stable real-time analytics platform. Distributed streaming platforms like Apache Kafka® or Redpanda do a good job as the foundational component of the real-time analytics pipeline. Cloud-based platforms like AWS Kinesis, Azure Stream, and Google Dataflow are good alternatives for implementing real-time analytics architectures.
Most streaming platforms come built-in with stream processing engines. Users can also plug in different stream processing engines if the use case requires more than what is offered as a default —for example, Apache Spark Streaming.
Streaming platforms also come with the ability to store the events they ingest. Platforms like Redpanda allow setting retention periods as infinite and use tiered storage that archives data into the cloud.

Real-time analytics databases
Most real-time data analytics requirements must combine incoming data with historical data to derive insights. For such requirements, a streaming platform alone is not enough. One also needs a database that enables quick retrieval of historical data alongside the incoming data. This is where real-time databases excel. Real-time databases are optimized for high-frequency writes, concurrent reads, and sub-second responses for complex analytical queries.
Traditional transactional databases that use row-oriented storage are optimized for quick writes and do not do a good job of concurrent read queries with complex logic. Real-time analytics databases rely on the NoSQL paradigm and use columnar storage to provide the same analytical querying ability with much better response time. They can handle semi-structured data as well.
Open-source databases like Apache Pinot™, Apache Druid®, ClickHouse, etc, are great examples of databases optimized for real-time data analytics. Some cloud-based data warehouses from AWS, Azure, and GCP also advertise real-time database features, but they tend to become very expensive in practice. AWS Redshift and Azure Synapse are examples of these cloud-based services.
A real-time analytics database is almost always used in combination with a streaming platform. The data from the streaming platform is inserted into the real-time database, which makes it available for analysis in no time. One can use complex queries that combine the data that was just ingested with the accumulated data and fetch results quickly.
A high-level architecture to serve user recommendations using a streaming data platform and real-time database looks as below.
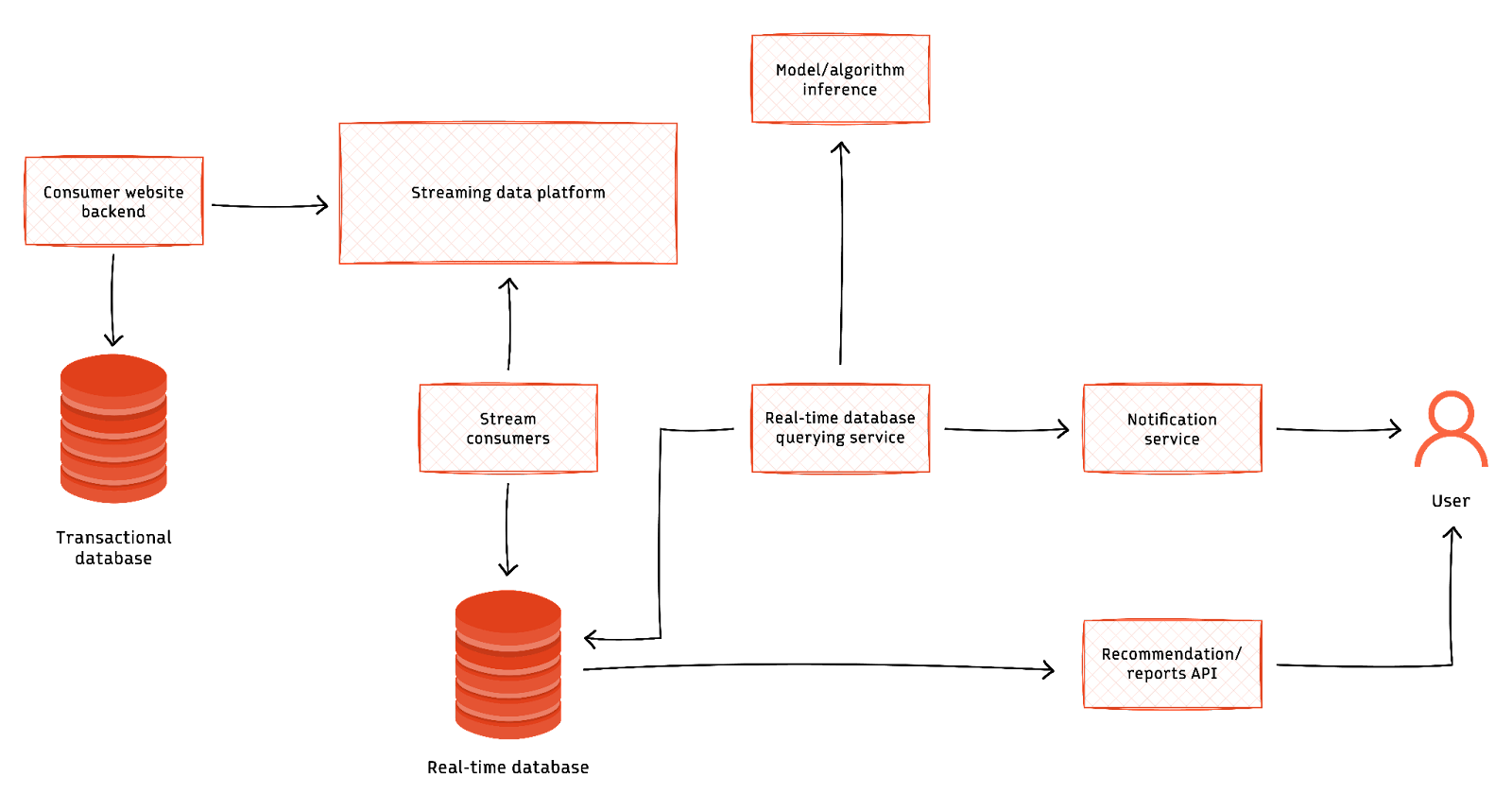
Key considerations for real-time data analytics
Choosing the best-fit architecture for your real-time data analytics solution must be done by considering various aspects of the requirement. The following section discusses various factors one must consider while designing the architecture.
Nature of use cases
Choosing the best-fit architecture requires one to carefully analyze all aspects of the use case. The use case dictates the query latency and the throughput that needs to be supported by the architecture. For example, a business intelligence use case may have a relaxed latency expectation and lower concurrency requirements.
The freshness of data and the extent to which it needs to be combined with the historical data is another key factor. For example, in customer behavior analysis, fresh data often needs to be combined with events that happened long before to generate insights. The complexity of the query also plays a critical role in deciding the architecture. For some use cases, pre-aggregated results may be enough, and on-demand aggregation may be an overkill.
Stream processing vs real-time databases
A critical aspect of designing a real-time architecture is to decide whether one needs a real-time database. A streaming platform and a data warehouse with basic real-time support will be able to handle most of the small-time window-based aggregations. Most streaming platforms can also retain data infinitely if needed.
However, the querying ability of streaming platforms is generally not as good as real-time databases. Even though it is possible to write custom code and implement any functionality you need through stream processing engines, the comprehensive query layer of the real-time database will have an edge regarding development speed and maintainable code.
To summarize, if your use case has only smaller window-based aggregations that do not need historical data, you may be able to implement it just by using a streaming platform. But if your use case has complex analytical queries on historical data, you are better off adding a real-time database to the mix.
Choosing the right streaming platform
A stable real-time analytics pipeline requires a scalable streaming platform optimized for high throughout. If the use case requires high throughput, then one must choose a distributed platform that can scale horizontally. Redpanda provides a simplified deployment mechanism and is faster than Kafka in several use cases. Redpanda also eliminates needing external dependencies like JVM, Zookeeper, etc.
If your use case warrants a real-time database, integration support for popular streaming platforms is also a key factor. Pulling data from Redpanda is as easy as defining a few configurations for Druid and Pinot.
Choosing the right real-time database
While choosing the real-time database, one must focus on the critical aspects of the use case. The ability to handle complex queries and the query language are key differentiators. For example, real-time OLAP databases are better for implementing user-facing analytics.
Data warehouses with basic real-time analytics features will be a better fit for business intelligence use cases. Other than querying ability, the degree of concurrency, and latency for your specific use case also must be considered before finalizing a real-time database.
Self-hosted vs. BYOC vs. Fully managed
The architectural components required for a real-time analytics system are available in multiple flavors. If the organization requires full control of its infrastructure, it can choose the relevant frameworks and deploy them within its own infrastructure. The organization has full control of its data in this case. However, this option requires deep engineering bandwidth and may not be viable for smaller organizations with strict cost constraints.
Completely managed services help to reduce the initial cost and deployment effort in setting up real-time analytics systems. Such services abstract away all the underlying infrastructure and deployment configurations to let engineers focus only on their core business logic. The obvious disadvantage is that the vendor controls the full infrastructure and may not provide much flexibility to the engineers.
A middle ground between these two options is the Bring Your Own Cloud (BYOC) model that enables organizations to configure their cloud accounts where the managed services will be set up. This provides enough flexibility to the organization without worrying about underlying hardware infrastructure. The cloud provider of their choice takes care of it, and the managed service runs on top of this cloud.
Different frameworks provide varying degrees of flexibility when it comes to choosing between these models. For example, ClickHouse provides options for bringing your own cloud or using it as a managed service. Redpanda also allows customers to use their completely managed service or BYOC service. Choosing between these alternatives must factor in the organization’s strategic direction and the key aspects of the use case.
Have questions about Kafka or streaming data?
Join a global community and chat with the experts on Slack.
Conclusion
Real-time data analytics enables organizations to bring insights to stakeholders as soon as the events happen. It plays a critical role in business intelligence as well as user-facing analytics. In the case of user-facing analytics, the concurrency and performance requirements are far higher than in simple business intelligence use cases.
You can use a streaming platform, a real-time database, or a combination of both to implement real-time analytics. Choosing the right architecture for your real-time analytics use case must be done based on the complexity of logic, latency, and the degree of concurrency needed.
