
Real-time data ingestion
“Uber, the world’s largest taxi company, owns no vehicles. Facebook, the world’s most popular media owner, creates no content. Alibaba, the most valuable retailer, has no inventory. And Airbnb, the world’s largest accommodation provider, owns no real estate. Something interesting is happening,” Tech Crunch’s Tom Goodwin wrote to describe the digital disruption happening across every industry.
Tech companies are now rapidly creating new products using real-time data, as in the case of Uber, which harnesses a real-time data stream of its drivers’ cars and matches them with real-time demand for rides.
Across diverse industries, real-time data heavily influences decision-making, which expedites responses and enhances customer experiences. Real-time data ingestion is crucial in utilizing real-time data to its full potential.
But what exactly is real-time data ingestion, and how can you implement it? This article explores the tools and architectures available for real-time data ingestion.
Summary of key concepts in real-time data ingestion
Concept | Explanation |
|---|---|
Real-time data for decision making | Real-time data ingestion enables businesses to make timely operational decisions based on current data, facilitating faster and more accurate decision-making, which is critical to the organization's success. |
Real-time data ingestion | Real-time data ingestion captures and stores data for processing and analytics for immediate insights. |
Real-time data sources | Real-time data ingestion collects data from various sources, such as IoT sensors, weblogs, and mobile apps, in real or near-real time. |
Real time versus batch data ingestion | Data ingestion can be classified into two main categories: batch and streaming (or real-time) ingestion. Batch ingestion involves the accumulation of data that is processed in chunks (or batches) at regular intervals while streaming ingestion requires data to be collected as it is created. |
The role of real-time data for decision-making
Real-time data, as the name suggests, is processed and made available almost instantaneously or with minimal delay after it is generated or collected. This is in contrast to batch-processed data that is processed at regular intervals, such as hourly, daily, weekly, or monthly.
Businesses build real-time data pipelines that ingest data at one end and then further process data downstream for analytics. Data flows continuously as a stream from the generating source to final consumption. Businesses can make more informed decisions, optimize their processes, and create new value streams for
Faster decision-making
Improved operational efficiency
Personalized customer experiences
Proactive monitoring
By leveraging real-time data, businesses can react quickly to environmental, market, and customer behavior changes, enhancing competitiveness and better overall business outcomes.
Below are some example use cases.
Finance
Traders and financial institutions rely on real-time market data to make split-second decisions and capitalize on opportunities in the market. Risk management systems continuously assess and mitigate potential financial risks, such as fraud detection, by using real-time data to identify and block suspicious activities while ensuring that legitimate transactions are processed without disrupting the consumer.
IoT and sensor monitoring
The Internet of Things (IoT) relies heavily on real-time data, with sensors and devices continuously collecting and transmitting data for various applications. For example, IoT and sensor monitoring gather data on traffic, air quality, and energy usage to streamline city services. Predictive maintenance is another application where IoT systems detect potential issues before they arise, enabling proactive maintenance and repair.
Personalized marketing campaigns
In marketing, real-time data can be leveraged to deliver personalized marketing campaigns that target individuals based on their search behavior, online activity, and location. Marketers create custom-tailored advertisements, recommendations, and promotions that resonate with their target audiences.
Security and surveillance
In security and surveillance, real-time data is used to monitor areas for potential threats, respond quickly to security breaches, visualize threats in real time, and set alerts for detecting attacks. Having a system in place ensures that the appropriate actions are taken to protect people, property, and assets.
Streaming data architecture
Streaming data architecture is a subset of the event-driven architecture. Event-driven architecture is a system that reacts to external occurrences or events as they happen. It processes events and triggers when a specific event occurs, sometimes using a publish-subscribe architecture.
Streaming systems treat every data point as an event that captures a state change from a source system. They break up events for loose coupling and scalability among producers and consumers.
A streaming-based architecture often employs data ingestion tools such as Redpanda to collect and distribute data in real time, ensuring that data is made available for further processing with minimal delay. Data messages are published, or software triggers are activated as events occur. The data ingestion tool manages messages in an immutable log.
Logs are append-only, which means that data (or messages) are only added to the end of the log. This is similar to how data is written in a traditional log file—always added at the end. Once a record is written, it cannot be changed. Data remains constant and unaltered, ensuring data consistency and reliability.
Stream processors subscribe or listen for incoming published data. Data is stored for later use/processing or real-time services like APIs, alerts, real-time dashboards, etc.
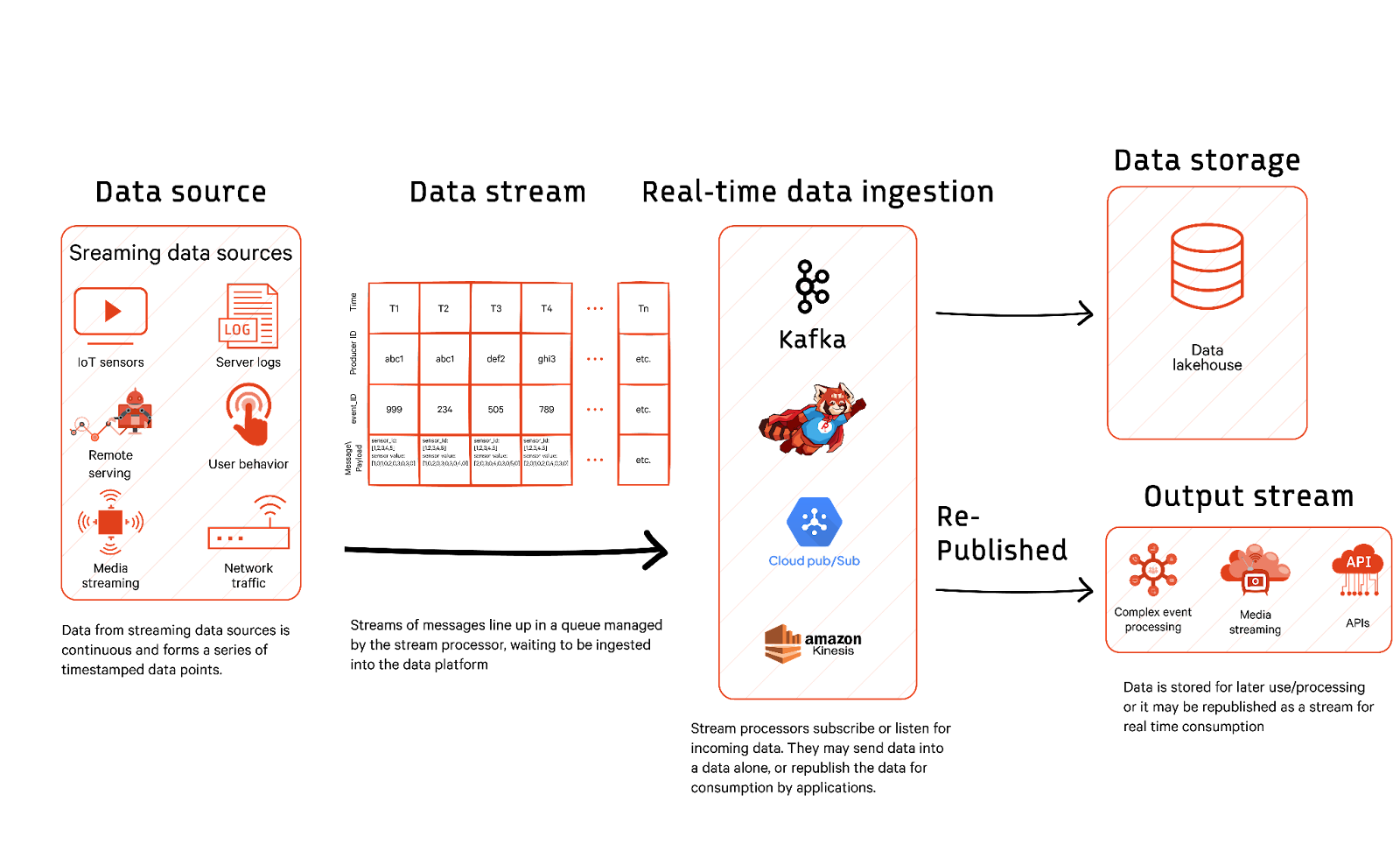
Streaming data architecture is known for its scalability and ability to manage large data volumes from multiple sources, making it an excellent choice for modern applications and microservices. By reacting quickly to system triggers, event-driven architecture ensures that data is processed and delivered efficiently, improving operational efficiency and reducing decision-making latency.
Recommendations for implementing real-time data ingestion
Ultimately, the decision to implement real-time data ingestion depends on the specific use case, industry requirements, and available resources. Performing a return on investment comparison of batch processing versus real-time data ingestion can lead to an appropriate infrastructure decision.
For applications like periodic reporting or trend analysis, which do not require immediate insights or decision-making, batch-processed or near-real-time data may be more appropriate.
Other factors to consider include the data volumes and scalability, data retention requirements, data latency, high availability requirements, and the desired level of data security.
Data volumes and scalability
Data volume in real-time data pipelines measures throughput reported in MB/s or GB/s. Data engineers calculate a theoretical sustained throughput limit to determine the requirements of the pipeline. This value is the sum of the size of all the messages expected per second. A best practice in data engineering is to target 80% of this value for each cluster.
As an example, consider the following message from an IoT device:
{
"header": {
"messageType": "sensorData",
"timestamp": 1636549200
},
"payload": {
"sensorType": "temperature",
"value": 25.5,
"unit": "Celsius"
}
}Uncompressed, this message takes about 4kB on disk. At scale, suppose you have 1000 devices sending 200 similar messages every second.
4kB * 1000 * 200/s = 800MB/s
If you compress the data stream, you can reduce the data size and include this in your considerations. Based on the 80% rule, you will target 640 MB/s per cluster.
Data volume increases rapidly as operations scale. In the example above, if the business anticipates increasing the number of devices over time, the pipelines will also need to be able to scale. However, not all scaling is anticipated. Monitoring the throughput and latency of your pipelines is necessary to keep pipelines working during periods of rapid growth or increased activity.
With a real-time data ingestion platform like Redpanda, you can scale to petabytes of data without impacting code. Scales horizontally or vertically — add more nodes or allocate more cores as your workload grows. Redpanda also offers intelligent tiered storage by automatically moving older data between brokers and cost-efficient cloud object stores, like S3.
Data retention
Data retention dictates how long messages are kept on disk before deleting or compacting. Keeping more data available within the real-time data ingestion system enables the data to be reprocessed if needed. However, retaining too much data can lead to filling up disk space.
When considering retention settings, you must assess the use case and understand possible failure scenarios. Downstream applications and processes need time to process event streams before they are deleted. Additionally, some experimental use cases, such as A/B testing or Machine Learning, require that historical raw data be available to reprocess to perform realistic testing.
Redpanda provides several ways to manage disk space to ensure the production stability of the cluster. You can:
Configure message retention and cleanup policies.
Configure storage threshold properties and set up alerts to notify you when free disk space reaches a certain threshold.
Use continuous data balancing feature to automatically distribute partitions across nodes for more balanced disk usage.
Create a ballast file to act as a buffer against an out-of-disk outage.
Data latency
Data latency, or freshness, is critical for real-time data ingestion to guarantee that the data being ingested is delivered promptly, per the business use case requirements. This requirement is determined by the decisions made or downstream actions taken based on the data. How quickly do these decisions need to be made? How fast or slow is a system using the data?
For example, consider an assembly line with data streaming from sensors from each machine. The sensors provide monitored data to determine whether each machine operates within safe limits. The industrial engineer in charge of safety determines that a status update once per minute is sufficient to provide maximal safety to workers on the assembly line.
Redpanda provides up to 10x lower tail latencies for the same workloads on identical hardware, even under sustained loads compared to other data ingestion platforms like Apache Kafka®.
High availability
High availability of pipelines is needed to ensure data integrity and overall data accessibility to downstream users and applications. Failures can happen at any point, and data ingestion systems must provide redundancy mechanisms.
For example, Redpanda assures high availability by continuously replicating data among members of the cluster. While the technical explanation is out-of-scope for this guide, you can read more about it here.
Data security
Security is vital for real-time data ingestion to guarantee that ingested data is safeguarded from unauthorized access or data injection attacks. This is particularly essential for applications involving sensitive data, where end-to-end encryption is a non-negotiable best practice and data protection laws, such as GDPR, must be considered.
Authentication and authorization best practices, like the SASL framework, are followed in real-time ingestion as well. Access control lists (ACLs) work in tandem with authentication and provide a way to configure fine-grained access to provisioned users. Another security best practice is to enable encryption with TLS or mTLS.
Redpanda offers several security features for authorization and authentication as part of Kafka API compatibility and through the Redpanda Console.
Summary of Redpanda features for real-time data ingestion
By selecting the appropriate tools, businesses can ensure their real-time data ingestion process is efficient and scalable. As mentioned above, Redpanda offers highly customizable solutions for a wide range of real-time data use cases. We summarize the features in the table below.
Pipeline considerations | Redpanda capabilities |
|---|---|
Data volumes and scalability | Highly capable on a few nodes: benchmarked at 79.574ms for large workloads on three nodes. Capable of scaling vertically and horizontally. Offers Tiered Storage to increase the amount of data that can be retained. |
Data retention | The default is 24 hours. A configuration that can be set at the topic or cluster levels for time or size-based retention. A cleanup policy can also be configured to compress and store or delete the logs. |
Data latency | End-to-end latency benchmarked at 13.91ms for small workloads (50MB/s) and 79.574ms (1GB/s) with 3 nodes. In the benchmark test, this was significantly faster than Kafka, delivering faster performance without additional hardware. |
High availability | Self-healing platform with features such as replica synchronization, rack awareness, partition leadership, producer acknowledgment, partition rebalancing, and tiered storage and disaster recovery. |
Security | Offers multiple forms of authentication (including Kerberos), fine-grained access control lists (ACLs), TLS and mTLS data encryption, configurable listeners, easy to configure in the security console, IAM Roles for self-hosted clusters. |
Have questions about Kafka or streaming data?
Join a global community and chat with the experts on Slack.
Conclusion
Businesses and organizations must make decisions as events unfold. Real-time data ingestion tools collect data as it is generated from various sources for further analysis and processing in your real-time data pipeline. Ingestion tools must handle data at volume and scale, retain data as needed, and provide high availability with low latency.
Most existing tools require developers to build workarounds in code to meet all of the above requirements. However, Redpanda is a developer-friendly data ingestion platform with several built-in capabilities for increased efficiency.
To get started, you can grab the Redpanda Community Edition on GitHub and browse the documentation. If you have questions or want to chat with our engineers, join the Redpanda Community on Slack.
