
Flink CDC
Nowadays, there’s a widespread expectation that data will be processed and analyzed in near real-time. However, in practice, many organizations have existing infrastructures built around RDBMS. Streaming applications must talk to traditional relational databases for tasks such as data enrichment, persisting state, or integrating real-time insights with historical data.
In this article, we examine Change Data Capture (CDC) as a solution to address this challenge, specifically Flink CDC, a collection of adapters provided for use with the popular Apache Flink® stream processing software.
Summary of key Flink CDC concepts
Concept | Description |
|---|---|
Change data capture (CDC) | CDC converts actions in a conventional database into an event stream. |
CDC sources | Traditional databases can be used as CDC sources using adapters |
Flink | It is a framework for real-time stream processing |
Flink CDC connectors | Flink provides CDC connectors for connecting to many traditional database sources |
Flink CDC Scenarios | Applications for Flink CDC include maintaining audit trails, data synchronization, and integration of traditional and streaming architectures. |
Introduction to CDC
CDC is a process that allows changes to a conventional database to be streamed in real-time - bridging the gap between streaming and non-streaming databases. Originating in the early 1990s, CDC captures database changes, such as inserts, updates, and deletes, as a sequence of events, providing a real-time snapshot of database activities.
This mechanism is comparable to database replication methods, where changes to one database are sent to and replayed on a standby database to ensure its state matches the primary.
How does CDC work?
CDC continuously monitors and records each change in a database, transforming these modifications into an event stream. The output of CDC is an audit trail of all actions, which another system can process. For example, you can update the state in another environment or trigger changes to external systems as they occur in the source database.
CDC often uses existing database replication functionality, such as processing a Write-Ahead Log (WAL), to generate events. CDC events trigger operations within the streaming platform or replay operations into another database. They maintain data synchronization by performing each insert, update, and delete operation on the target database using SQL.
CDC systems ensure data is processed only once and maintain data integrity by recording the current position in the database log as an offset value. For data consistency, you can maintain the offset state in a durable store and reuse it across consecutive runs of the CDC application.
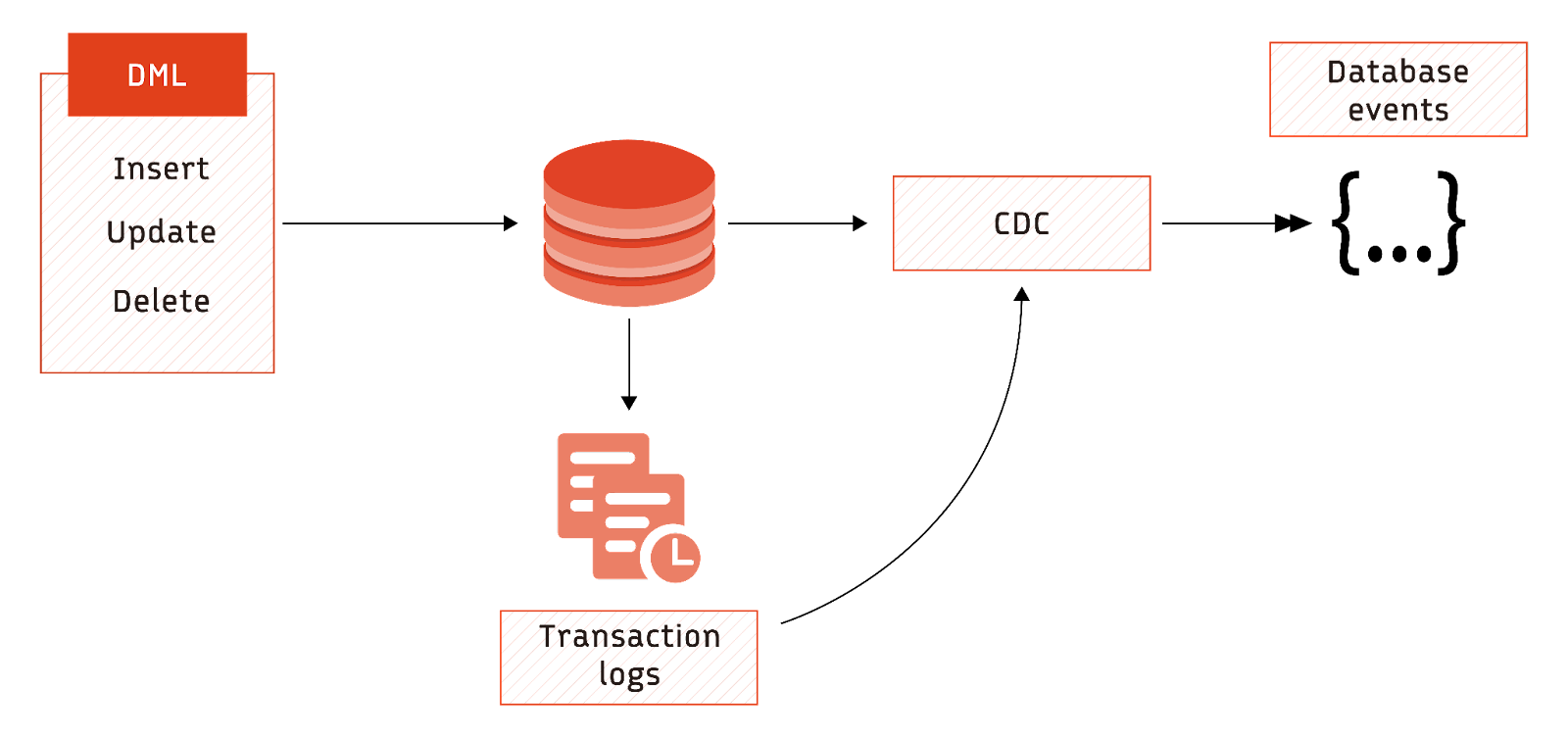
How is CDC used?
CDC converts database change events (insert, update, delete) into a data stream. You can process the data stream using streaming systems like Flink to complement real-time analytics.
CDC records contain the operation performed and the relevant data. For example, an update operation would include the table and the data before and after the update.
See the example below—the following payload is an extract from Debezium.
{
"schema": { ... },
"payload": {
"before": {
"shipment_id": 1,
"is_arrived": false
},
"after": {
"shipment_id": 1,
"is_arrived": true
},
"source": {
"db": "postgres",
"schema": "inventory",
"table": "shipments",
"txId": 556,
},
"op": "u",
"ts_ms": 1465584025523
}
}
It is then possible to process the resultant event stream in various ways, including
Streaming operational database changes to be analyzed in real time or stored in a data lake for historical reporting or audit purposes.
Synchronization of disparate platforms by replaying the events from one system to another.
Triggering automated processes in response to changes in the source database.
Flink CDC connectors
Flink is a robust and powerful open-source framework for real-time stream processing. It can perform stateful computation with high throughput and low latency for continuity and accuracy when stream processing.
Flink offers a variety of connectors that provide integration capability for various data sources and sinks. Flink's CDC connectors offer an abstraction layer with a simplified and standardized mechanism for connecting databases to stream processors. They allow easy integration of RDBMS systems into Flink's stream processing architecture.
Flink currently offers CDC connectors for the following database types:
MongoDB | MySQL | Oceanbase |
Oracle | Postgres | SQL Server |
TiDB | DB2 | Vitess |
Below are some real-world application architectures of Flink CDC connectors:
Maintaining database audit trail
In this use case, changes are streamed from the database using a CDC connector, and the streamed data is then converted into Parquet format and stored on AWS S3 cloud storage. The architecture provides a complete audit trail of historical changes that can be analyzed using a distributed SQL query engine such as Presto.
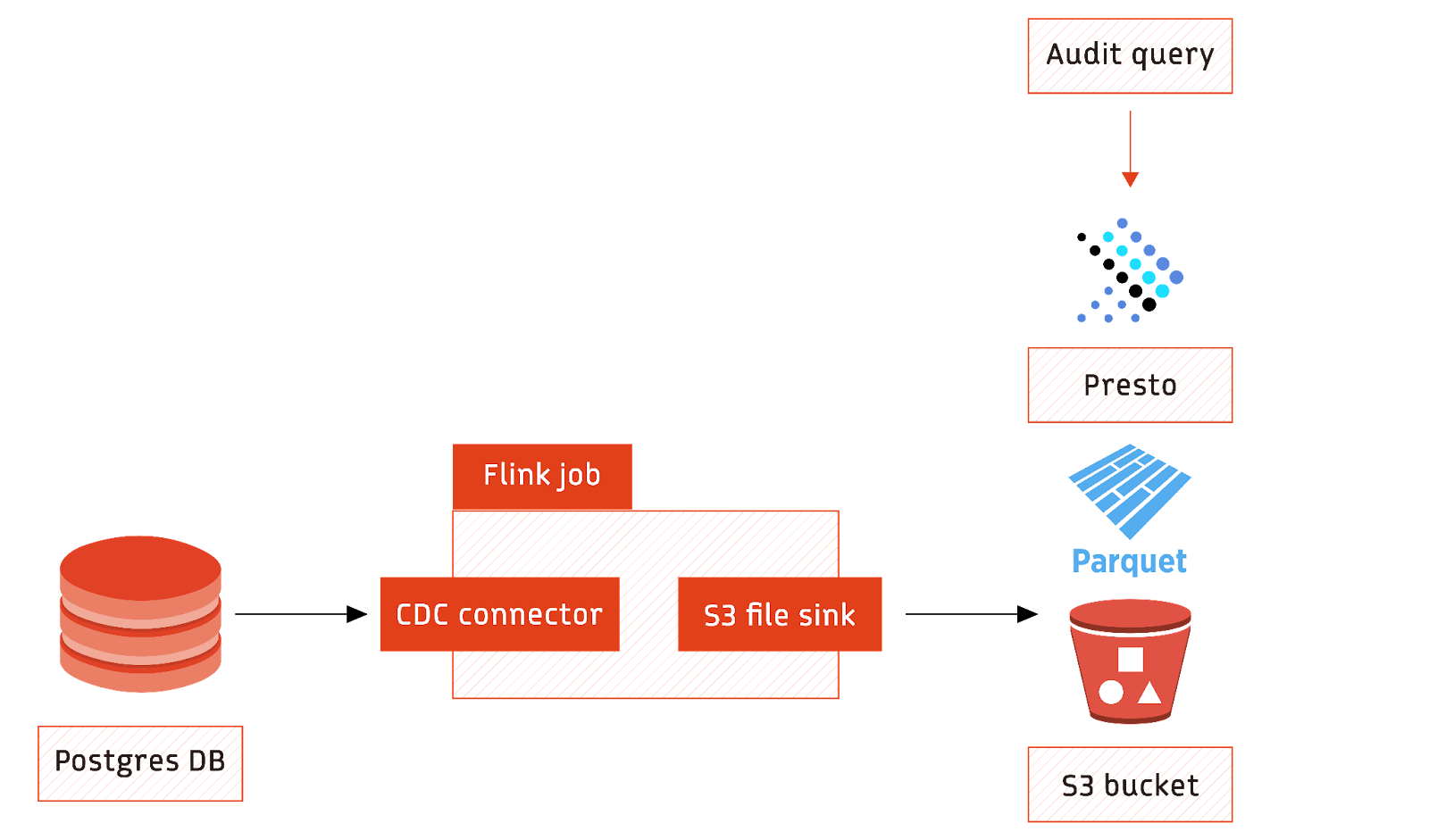
The Flink Postgres CDC connector collects database changes as they occur and writes the events using the S3 file sink connector. Flink natively supports Parquet as a format for writing data.
Creating materialized views
In this scenario, CDC facilitates the creation of materialized views. Database change events are captured from the stream processing system and converted to updates of a second database. It updates reporting tables in real time, allowing applications to query up-to-date data efficiently. Providing materialized queries in this way enhances the responsiveness and accuracy of data-driven applications.
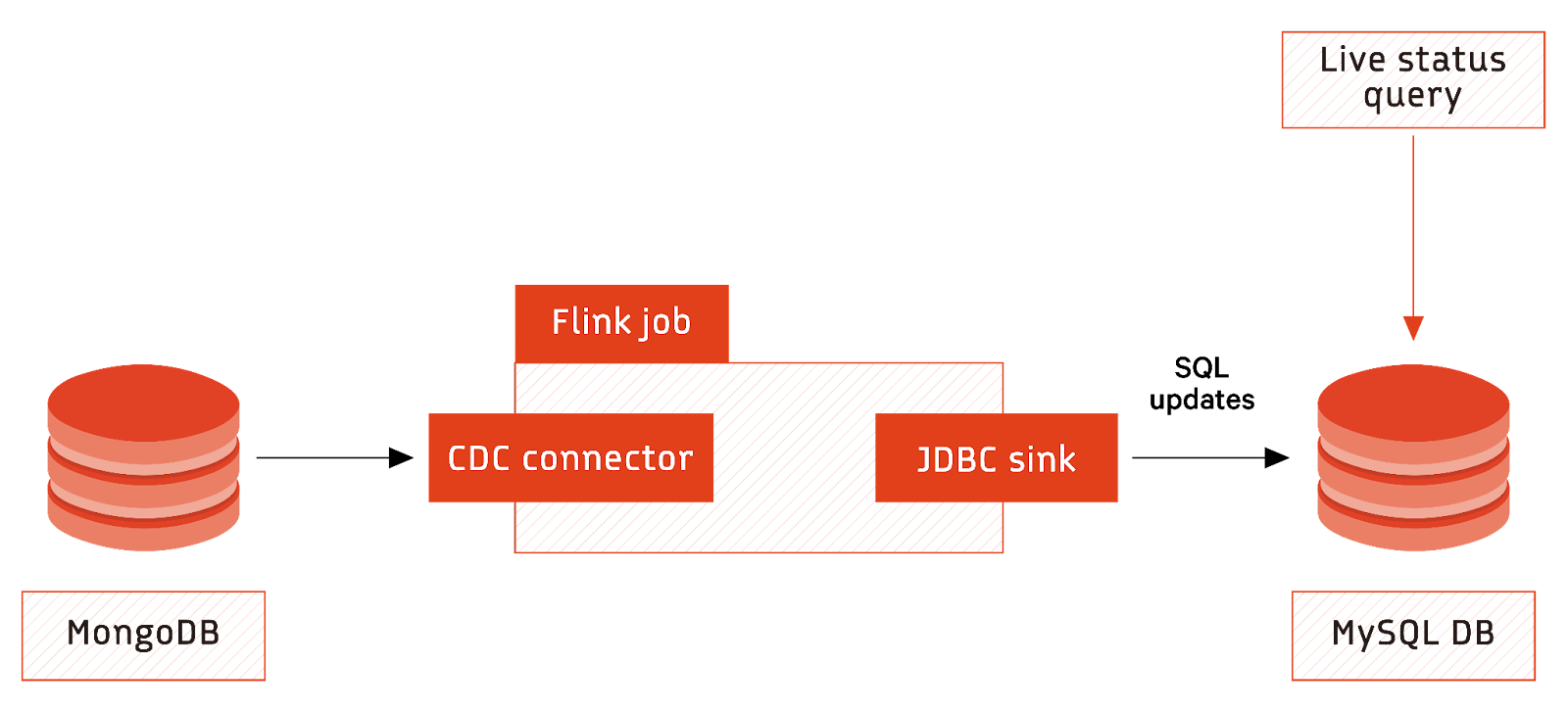
The Flink MongoDB connector collects updates from the primary database. Flink stream processing converts the updates into SQL statements, which get applied as update statements to a MySQL database containing summarised information using the JDBC sink.
Real-time inventory management
An eCommerce environment implementing real-time inventory management might implement the following architecture. Events generated by customer purchases are captured and streamed.
As orders are received, Flink stream processes transform them into API calls to an external order processing system. This integration of streaming user data with the order processing system ensures real-time order processing and management of inventory levels.
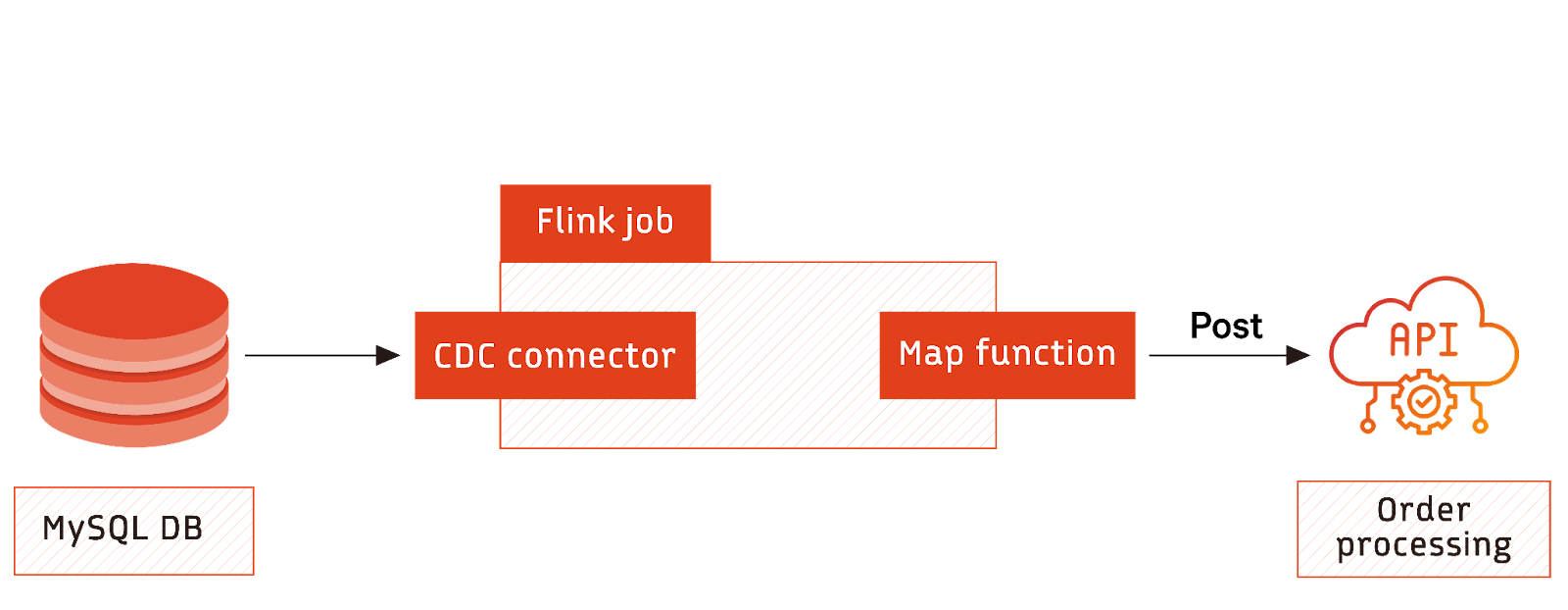
The Flink MySQL connector tracks entries to the orders database. A map function converts each event to an appropriate JSON format and posts the message over HTTP in an API call to the external system.
Multiple destinations
In this use case, CDC streams database changes from SQL Server to Redpanda, a streaming platform providing a queuing mechanism for real-time event processing. Multiple streaming jobs subscribe to these events in parallel, in this case, both maintaining an audit trail and performing fraud detection.
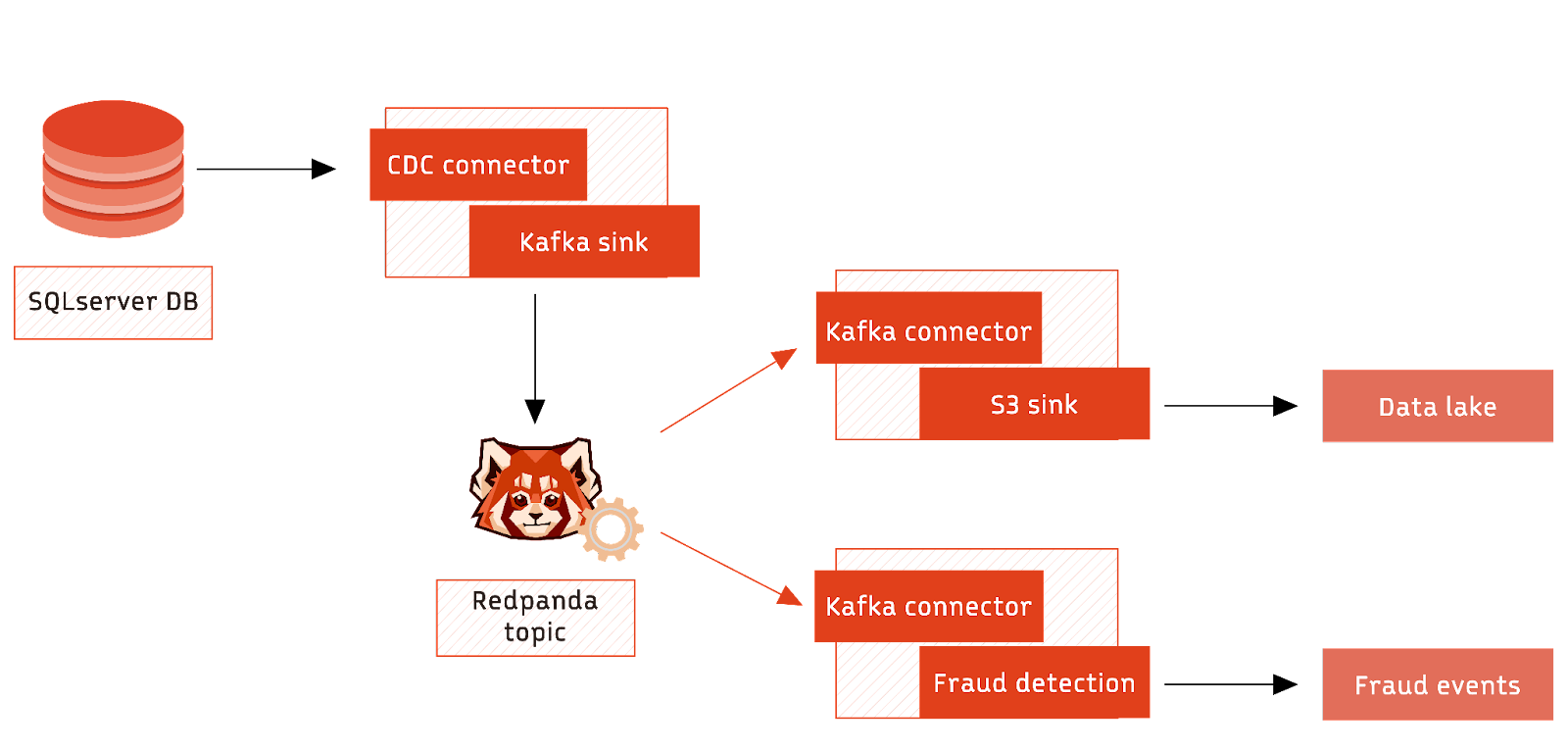
Leveraging Redpanda as an intermediary for stream data handling effectively segregates operational concerns. The separation allows the fraud detection algorithm to be revised and re-run without affecting existing audit trail data. It maintains data integrity without compromising system flexibility.
Flink stream processing
For each use case mentioned above, multiple transforms, updated metrics, side outputs, updated states, and logic could be applied to the events before Flink sends them to an external system. The complexity and nature of the logic would vary depending on the specific application and its requirements. However, processing will often involve converting the CDC events into a structure relevant to the domain represented in the database.
Have questions about Kafka or streaming data?
Join a global community and chat with the experts on Slack.
Flink CDC connector example
To explore Flink CDC's workings more deeply, we will use the Flink Postgres CDC connector as an example. All connectors follow a similar approach and have standard functionality.
The Postgres CDC connector allows a Flink Job to subscribe to changes on designated Postgres tables, creating a stream of events that other streaming functions or connectors can process.
Internal operations
The connector initially sends a READ event for each row in the monitored table.
It uses a database transaction to ensure that the initial event data is from a table snapshot at a single point in time.
It uses the Postgres streaming replication protocol to capture changes to the table and generate an event for each change.
This process takes a long time to complete for large tables, but there are options to mitigate this, such as enabling incremental snapshots or disabling snapshots altogether.
The CDC connector achieves change capture by configuring and listening to a Postgres replication slot. It generates and sends events from the messages sent to the slot and keeps track of the write-ahead log (WAL) offset.
Flink's CDC functionality uses connector libraries from Debezium, meaning you can apply most standard Debezium options to Flink CDC connectors. Debezium functionality includes capturing schema changes and enabling the downstream event structure to be updated if necessary.
Checkpoints
The Flink CDC connectors store the data processing state in the Flink job state, so it is essential to configure checkpoints and savepoints for your Flink job to ensure it restarts from the same point the job terminates.
Code examples
If using the Flink datastream API in Java, you can use the CDC connector to create a DataStream source using the PostgreSQLSource source function builder:
SourceFunction<String> sourceFunction = PostgreSQLSource.<String>builder()
// Database connection details
.hostname("localhost")
.port(5432)
.database("postgres")
.username("postgres")
.password("password")
// Table monitoring details
.schemaList("inventory")
.tableList("inventory.shipments")
.slotName("flink")
// output format
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
env.addSource(sourceFunction)
.print();
env.execute();
If using Flink SQL, a streaming table can be registered using similar parameters in the SQL syntax.
CREATE TABLE shipments (
shipment_id INT,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'localhost',
'port' = '5432',
'username' = 'postgres',
'password' = 'password',
'database-name' = 'postgres',
'schema-name' = 'inventory',
'table-name' = 'shipments',
'slot.name' = 'flink',
);
Once set up, the CDC source or table can be streamed, converted, and inserted into a sink table like any other Flink streaming source.
Alternatives to Flink CDC
Flink CDC is a robust real-time data synchronization and processing tool, but other noteworthy options provide similar data integration and management capabilities. Alternatives like Kafka Connect, Maxwell, and custom solutions offer advantages in certain circumstances that may be more suitable for your use case or operational environment.
Kafka Connect, part of the Kafka ecosystem, excels in streaming data between Kafka and other systems, making it useful for those already using Kafka or Redpanda.
Maxwell, a MySQL binlog reader, efficiently converts database changes into a JSON event stream, which is helpful for real-time analytics or replication with MySQL databases.
Custom solutions can be tailored to your needs and provide the flexibility to address unique challenges, such as legacy system integration or maintaining specific compliance requirements.
Redpanda Serverless: from zero to streaming in 5 seconds
Just sign up, spin up, and start streaming data!
Conclusion
With the growing demand for real-time data processing and analytics, CDC technology is increasingly important in bridging the gap between legacy sources and streaming platforms.
Flink CDC is gaining popularity due to its ease of use, speed, and flexibility. It enables businesses to use their most commonly used database systems as event sources for streaming platforms with minimal setup required.
Streaming events directly into a stream-processing platform such as Flink means the records can be transformed and processed in real time and dispatched to various other systems.
Flink and Redpanda work together when building operational and analytical use cases at scale. Redpanda can act as both the source and sink, while Flink performs stateless or stateful processing on streams coming in and out of Redpanda.
To try Redpanda for yourself, try Redpanda Serverless for free and start streaming data in seconds!
