
Event sourcing database architecture
Event sourcing is an architectural pattern that provides a comprehensive method for managing and storing the system state by capturing changes as a series of immutable events. Unlike traditional database architecture that updates the state directly, the event sourcing approach is similar to the ledger concept in accounting. Data is stored as a sequence of events in an append-only log, allowing changes to be tracked over time.
An event sourcing architecture establishes a record system with an audit trail that can be used to construct the current state of domain objects without losing any intermediate information. It is especially effective in simplifying data management for complex domains and provides the flexibility to reprocess data using logic.
This article explores event sourcing database characteristics, implementation suggestions, and advantages. We also cover several challenges and their solutions.
Summary of key event sourcing database architecture concepts
Concept | Description |
|---|---|
Event-based storage | Data is stored as a series of events. |
Immutable log | Records can only ever be written, never modified or deleted. |
Materialized views | Views of the current state of domain objects are constructed by processing events and deriving state through the chain of events on the object. |
Replayability | Events can be replayed to re-create state or materialized views, including changes in materialization logic. |
You can combine the concepts above to develop applications that can process data in real time and output the desired results to achieve the system's business goals.
Event sourcing database architecture—overview
Event sourcing uses a database storage technique focusing on the immutable recording of state changes as events. It involves generating an event, such as 'User Profile Updated,' when users update their profile in an application.
Instead of directly updating the user's record in a database, the event contains all relevant data, including the timestamp, user ID, and the specific changes made. The event is then serialized into a format like JSON or XML and stored in an append-only log.
Immutable log
The log serves as the authoritative source of truth for the system. Records are only added and never updated or deleted. You just add a new event with the appropriate modification for any adjustments. The log thus records the complete history of changes, enabling the system to reconstruct past states and see the event sequence that led to the current state.
Queries
Retrieving data in an event-sourced system involves a process called state reconstruction. Instead of querying a static table, the system reads a series of events and replays them to derive the current state. This process can be illustrated with a simple banking application. When calculating a user's current balance, the system reads all related 'Deposit' and 'Withdrawal' events from the event store. The system dynamically computes the current balance by sequentially applying these events - adding deposits and subtracting withdrawals. This method provides a highly accurate and traceable account of how the balance was arrived at, unlike traditional databases where only the final state is stored.
Additionally, this approach allows for temporal queries. For instance, one could reconstruct the account balance as of a specific date by replaying events only up to that date.
Materialized views
You can create materialized views by processing individual events and calculating the resulting changes to the domain object, such as the account balance, to provide meaningful output. This view can be updated in a traditional RDBMS database system, streamed to another event-sourcing destination, or queried directly from the stream processing system.
Since the complete sequence of events is available, it is possible to replay them at any point in time to generate a new materialized view or integrate alterations in the event processing logic. For instance, you can use it to compute new interest rates or to apply updated fraud detection algorithms.
Streaming
Event sourcing is a valuable technique that complements stream processing technologies. As new events are generated, they are typically sent to a real-time event streaming system like Redpanda. The system preserves the order of the events and makes it available for further processing by stream processing frameworks like Apache Flink®. The events can also be saved in data lake formats like Apache Parquet for long-term storage.
Streaming technologies can process events in real-time, allowing an instantaneous response to system changes. For example, an event indicating a stock trade can trigger an immediate computation related to portfolio valuation, risk analysis, or compliance checks in a stock trading application. This real-time processing capability is essential when prompt response to data changes is critical.
Additionally, complex event processing (CEP) can be employed to identify patterns or combinations of events. In the context of our stock trading example, CEP can detect specific patterns of trades that might indicate fraudulent activity or market manipulation, triggering alerts or preventive actions. This integration enhances the system's responsiveness and allows sophisticated real-time analytics and decision-making based on the event stream.
Example event sourcing application
We implement a simple hypothetical banking example to understand the concepts better. We use a Redpanda topic as an immutable event store to record account transactions and Flink to process the events and maintain the account balance.
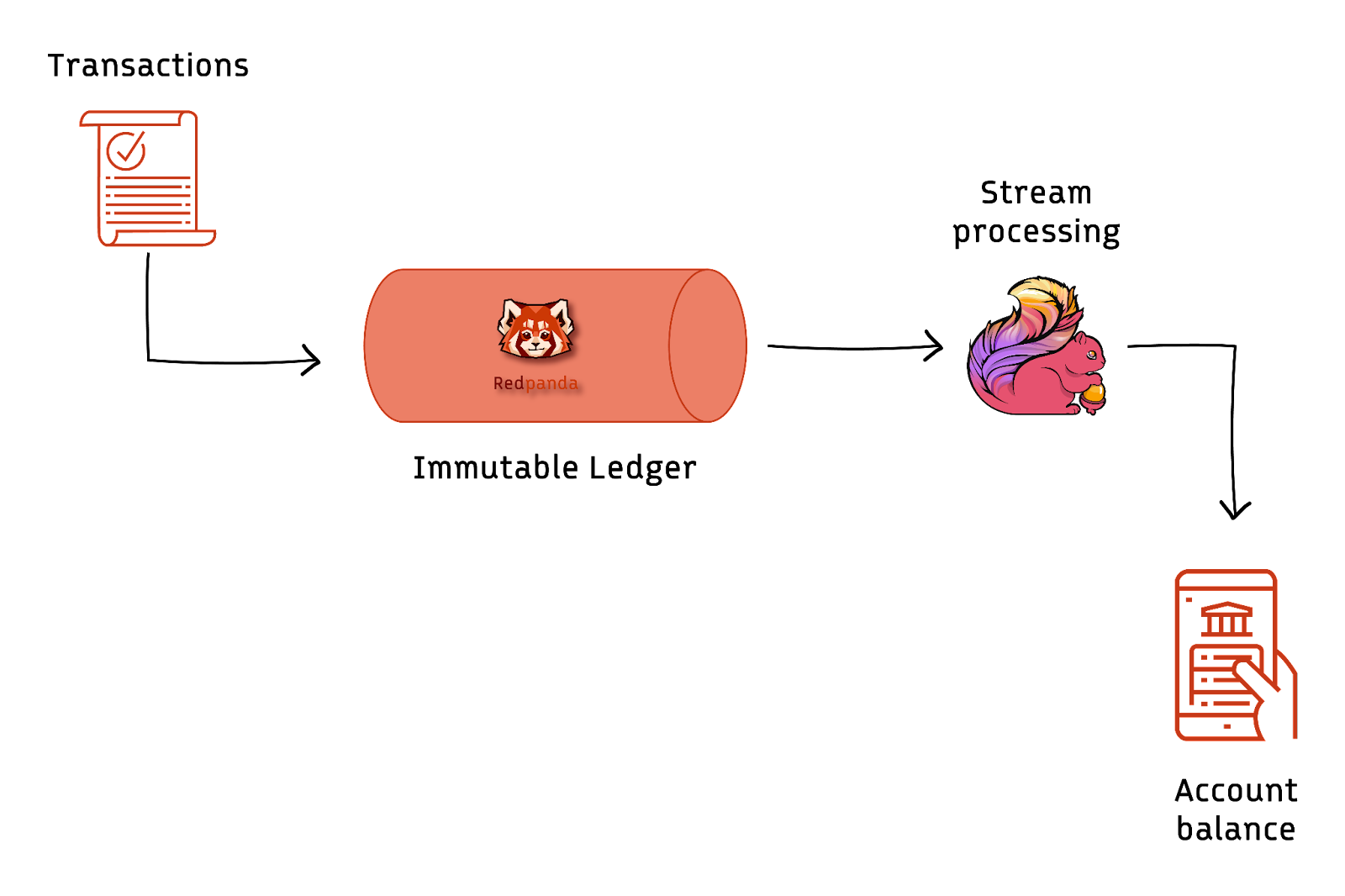
As transactions occur, they are loaded into Redpanda in JSON format, including the account ID, amount, and timestamp:
{
"accountId": l,
"amount": -20.0,
"timestamp": 1702468800
}A Flink streaming function keeps track of the balance for a specific account in its state. The function updates the state with the new balance whenever a new transaction is received in the topic.

Let’s say business requirements change, and you now want to apply a historical interest rate on the account balance. The replayability feature of the event sourcing system allows you to replay the events using an updated function that applies the interest rate during each change in the balance. This means you can retrospectively re-calculate the balance at each step.

As business rules or requirements change, you can still access the detailed information necessary to calculate historical values or derive new insights according to the new logic.
Advantages of event sourcing
Event sourcing architecture provides a comprehensive and chronological record of all events. The immutable nature of event logs ensures that historical data is never lost or overwritten, maintaining data accuracy. Reprocessing events with different logic offers exceptional flexibility in adapting to new requirements or changing business rules. Additionally, you can:
Efficiently handle extensive data and transaction volumes, making it ideal for systems needing scale.
Manage complex systems where understanding the sequence and impact of events is crucial.
Query the historical system state at any point in time, offering powerful insights into trends and changes over time(temporal data analysis.)
This approach guarantees that your data remains intact, free from tampering, and without any loss or corruption. Moreover, it enhances auditability and traceability and provides a robust foundation for disaster recovery.
Event sourcing challenges and solutions
Like any approach, event sourcing also presents some challenges. However, some approaches exist to mitigate them.
Uncontrolled storage growth
Accumulating events over time can significantly increase storage requirements. You can compress older events to reduce storage space without losing information. Another solution is to create periodic snapshots of the current state to avoid reprocessing the entire event log. This way, you can reduce the data needed to reconstruct the current state.
For example, Redpanda uses tiered storage to help offload and store historical data in cheaper cloud storage. You can easily retrieve archived data via a broker component without implementing a separate consumer for the cloud storage. Redpanda automatically rehydrates the data back to the broker to recreate the event state as needed.
Inconsistent performance
Processing a long chain of events, especially during system startup or when recalculating materialized views, can be resource-intensive, negatively impacting application performance. To counteract this, you can
Implement caching mechanisms to quickly access frequently requested data.
Use efficient algorithms and data structures to optimize event processing.
Distribute the workload across multiple servers or services and scale infrastructure as needed.
Use high performing streaming technologies for consistent performance.
For example, Redpanda effortlessly handles large data volumes, so you can perform complex analytics with real-time data. It offers up to 10x lower average latencies for the same workloads as compared to open source alternative Apache Kafka® on identical hardware, even under sustained loads.
Implementation complexity
Event sourcing architectures are more complex than traditional systems. Specialized knowledge and skills are required to work with them effectively. To reduce complexity, you can
Design the system modularly to isolate complexity and facilitate maintenance.
Leverage existing frameworks and tools that provide abstractions and simplify the implementation of event sourcing patterns.
Tools like Flink or Materialize can abstract some of the complexity, making it easy for developers to implement event sourcing. You can use Redpanda as the underlying event store that works seamlessly with both technologies.
Data privacy concerns
Storing every change as an event may raise privacy concerns, particularly with regulations like GDPR that mandate data delectability. You can address data privacy concerns by
Storing only non-sensitive event data.
Implementing event data anonymization.
Implementing policies to expire and delete events that are no longer necessary or contain sensitive information.
Make sure to regularly audit the system for compliance with data privacy regulations and conduct periodic reviews to ensure that the system adheres to best practices in data privacy.
Alternative implementations
The event sourcing pattern is often used with CQRS (Command Query Responsibility Segregation) to improve the capability of temporal queries and state management. CQRS separates operations that read data (queries) from those that update data (commands).
A command is an instruction to change the system's state. It could be something like "Add a new account" or "Update a balance." Commands modify the state of the system but do not return data. They are typically processed asynchronously. In contrast, A query requests to read data without changing the system's state. Queries return data and are often run synchronously.
Queries can be optimized for read performance, while commands can be validated before running to ensure the system remains consistent. This separation offers several benefits, such as better scalability, complexity management, and performance optimization.
Scalability: By separating reads and writes, you can scale each operation independently, optimizing resources based on the different load characteristics of commands and queries.
Simplified queries: The read model can be simplified and optimized for query efficiency, even using different storage mechanisms more suited to reads.
Improved performance: Command operations can be optimized for write efficiency, and complex business logic can be handled without impacting read performance.
Enhanced flexibility: Allows different models to evolve independently, adapting to changes in business requirements more efficiently.
Have questions about Kafka or streaming data?
Join a global community and chat with the experts on Slack.
Final thoughts
Event sourcing can be an effective architecture for managing data dependent on chronological sequencing. Its ledger-based method ensures historical accuracy and facilitates the straightforward tracing of data alterations over time.
Redpanda with Flink and cloud storage is a powerful, easy-to-use combination for event-sourcing implementations. Plus, Redpanda’s Data Transforms feature (powered by WebAssembly) allows outbound data transformation via Wasm.
Eventually, you can use this to implement capabilities like predicate and projection push-down, which have the potential to speed up basic streaming operations by reducing the amount of data that goes from Redpanda to your stream processors.
