
Event stream basics
Let’s start from the top. An event refers to any change to a system—every action, the time it occurs, and its associated metadata is called an event. The continuous flow of event data is called an event stream. So, an event stream can be described as a sequence of events ordered according to time or has timestamps.
Dealing with event streams is critical in modern times because of the emphasis on real-time insights. Acting on events involves generating alerts, detecting patterns, deriving aggregated metrics, or storing them forever in a fault-tolerant and orderly fashion.
This article explains an event stream, its use cases, and various architectural paradigms for event streaming.
Summary of key event stream concepts
Concept | Description |
|---|---|
Event streams | Events streams are sequences of events relevant to a business that are ordered by time of production or reception. |
Event-driven architecture | Event-driven architectures envision the complete system as a collection of decoupled services that react to receiving various events. |
Event stream processing | Event stream processing involves executing various business logic on alerts, aggregation, and report generation. |
Event sourcing | Event sourcing architectures rely on storing the events permanently and having an immutable log of events over time that can recreate the state of the whole system at any point in time. |
Understanding event streams
An event stream is a continuous flow of data about changes happening in a system. Considering the time and order of generation, anything relevant to a business that needs tracking can form an event stream.
For example, consider a logistics enterprise that tracks the real-time location of its shipments worldwide. The periodic events sent from onboard GPS modules specifying the system coordinates represent an event stream. The company can then use it to generate alerts based on patterns or aggregate them to derive relevant metrics for their operation. Other common examples of event streams include stock market trade signals, user activity data, etc.
Challenges in dealing with event streams
Dealing with event streams involves challenges different from handling static data for the following reasons.
Varying stream velocity
In most cases, events represent something happening in the physical world. They do not follow regular intervals or exhibit predictable velocities. External factors like network connectivity lead to further irregularities in reception time. Hence, any system that acts on events must always be on and act on it as soon as the event is received.
Unpredictable event volumes
Events streams do not follow a pattern of predictable volume. The streams can idle for an extended period and then suddenly get overwhelmed with several back-to-back events. Consider a system with numerous sensors that trigger events whenever the ambient temperature exceeds a specific threshold. Such a system can stay idle for a long time and then suddenly start producing events from all sensors if the climatic conditions of the region change.
Out-of-order events
Events may lose the order in which they were produced in the physical environment by the time they reach the processing system. Network delays, physical distance, or logical errors in the event production sub-system can lead to out-of-order events. The processing subsystem must have fail-safe mechanisms to handle such scenarios.
Event streams are continuous and unbounded
Most event streams are never-ending. So, a storage and processing system that deals with events must always be online and support large data volumes. It also must be fault-tolerant so that events are never lost. Even if the processing subsystem fails or goes down for a short period, enough fault tolerance must be built to store events reliably until the system returns online.
Solving event stream challenges
Handling challenges related to events in real time requires a different architectural paradigm. This is where dedicated event streaming systems and message brokers come into the picture. Platforms like Apache Kafka®, Redpanda, and ActiveMQ provide a buffer for holding events scalably and facilitate asynchronous processing.
They also come with fault-tolerant storage and enforce strict ordering once the event reaches the buffer. Choosing an event-handling platform best suited for your use case must be done based on the following factors.
Event volume handling and processing performance.
Extend of fault tolerance
Complexity of event processing logic
Going for the best platform in all the above factors often results in prohibitively expensive infrastructure bills. So, choosing one that balances the use case-specific factors and cost is important. Check out our guide on how to choose the best event streaming platform to learn more.
Handling event streams
Now that we understand the foundational aspects of event-handling architecture, let's delve into the architectural patterns in this space.
Simple event-driven architecture
A simple event-driven architecture pattern consists of decoupled event producers and consumers. It generally involves a publish-subscribe model, where the streaming framework keeps track of subscriptions and delivers events accordingly. If a consumer has not subscribed to an event, it can never see it once published.
In simple event-driven architectures, consumer logic is a trigger that executes an action or identifies a simple pattern that spans multiple events. Identifying patterns that include various events in a publish-subscribe mechanism requires the consumer to store previous state information. Some of the applications of the publish-subscribe model are as follows.
Facilitating communication between microservices
Asynchronous processing for high-latency tasks
Parallel processing workflows
Data replication
An example of event-driven architecture is a typical eCommerce organization that executes several tasks driven by customer events while maintaining a highly responsive website. For example, consider an app dealing with orders, warehouse, shipping, payment, etc. A purchase event on the website triggers the order, inventory, payment, and shipping microservices to execute actions that complete the order. A simple event-driven architecture for this use case is shown below.
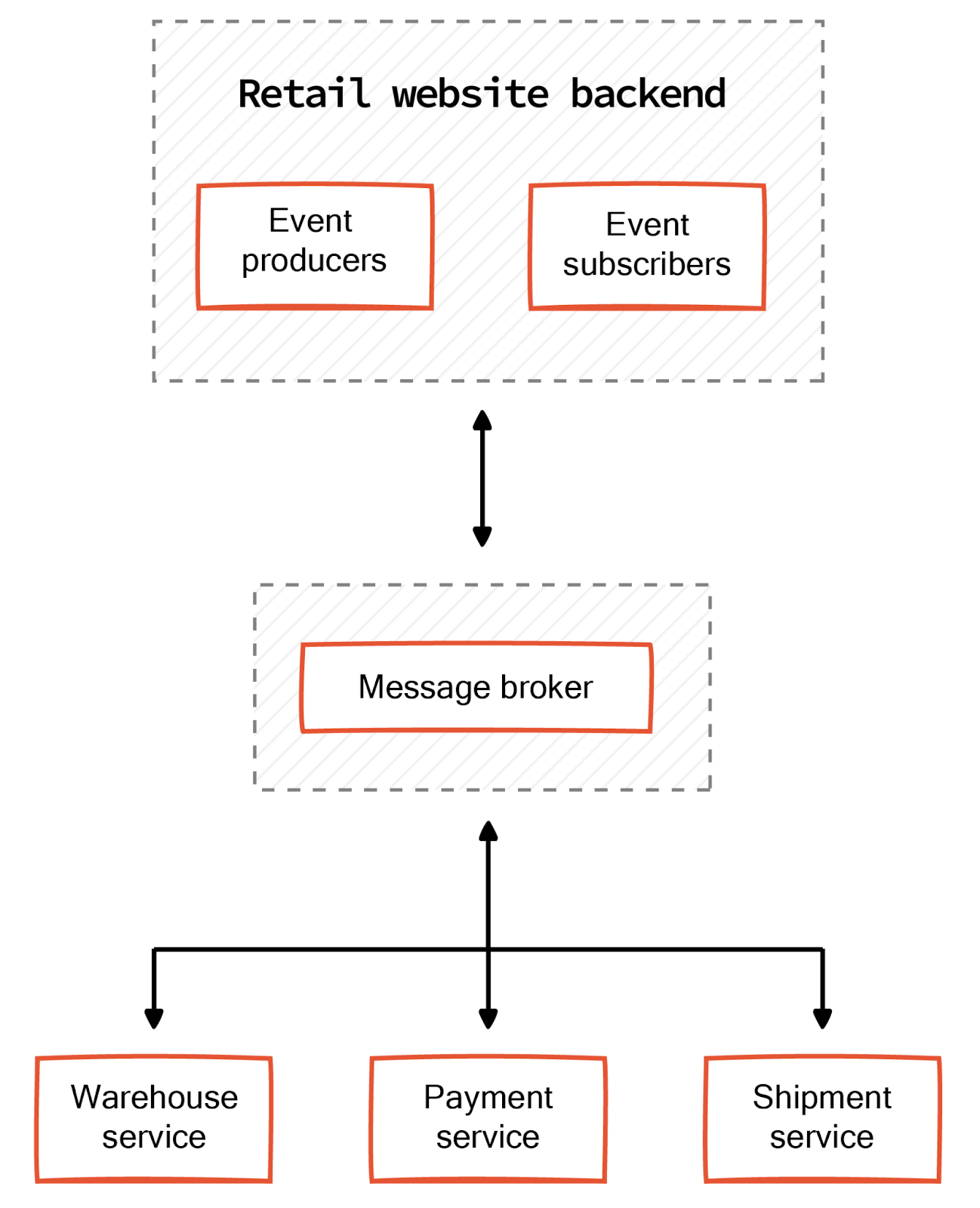
Event streaming architecture
Event streaming architecture works based on decoupled producers and consumers. However, their focus is on consumers processing a high volume of events with the best throughput and latency. There is no subscription and the stream is a never-ending log of events available to any consumer wanting to process it.
Since the event stream is always available for consumption without a subscription, consumers who require information on previous events can create windows based on the never-ending streams and execute complex event processing algorithms.
Event streaming applications require the consumers to run complex logic based on event windows. Hence, they need a framework that facilitates concisely writing complex logic. This is where frameworks like Kafka streams and Flink are helpful. They can work on top of an event buffer and provide a rich library of high-level functions and SQL-based logic representation.
Some use cases where an event streaming model fits well include:
Identifying complex patterns that require historical data.
Deriving metrics or building reports based on aggregating events.
Transforming events for downstream systems like data warehouses.
Let us consider the example of a logistics provider that relies on event processing for alerts and reporting. The shipment trucks send regular updates of their GPS coordinates. The processing system runs logic on these events on different aggregation levels.
For example, one consumer application can monitor trucks individually and generate alerts for specific conditions, say a truck remaining in the same location for more than an hour. Another consumer application can aggregate based on the destination region and build real-time reports of delays in shipments to that region. The architecture looks as below.
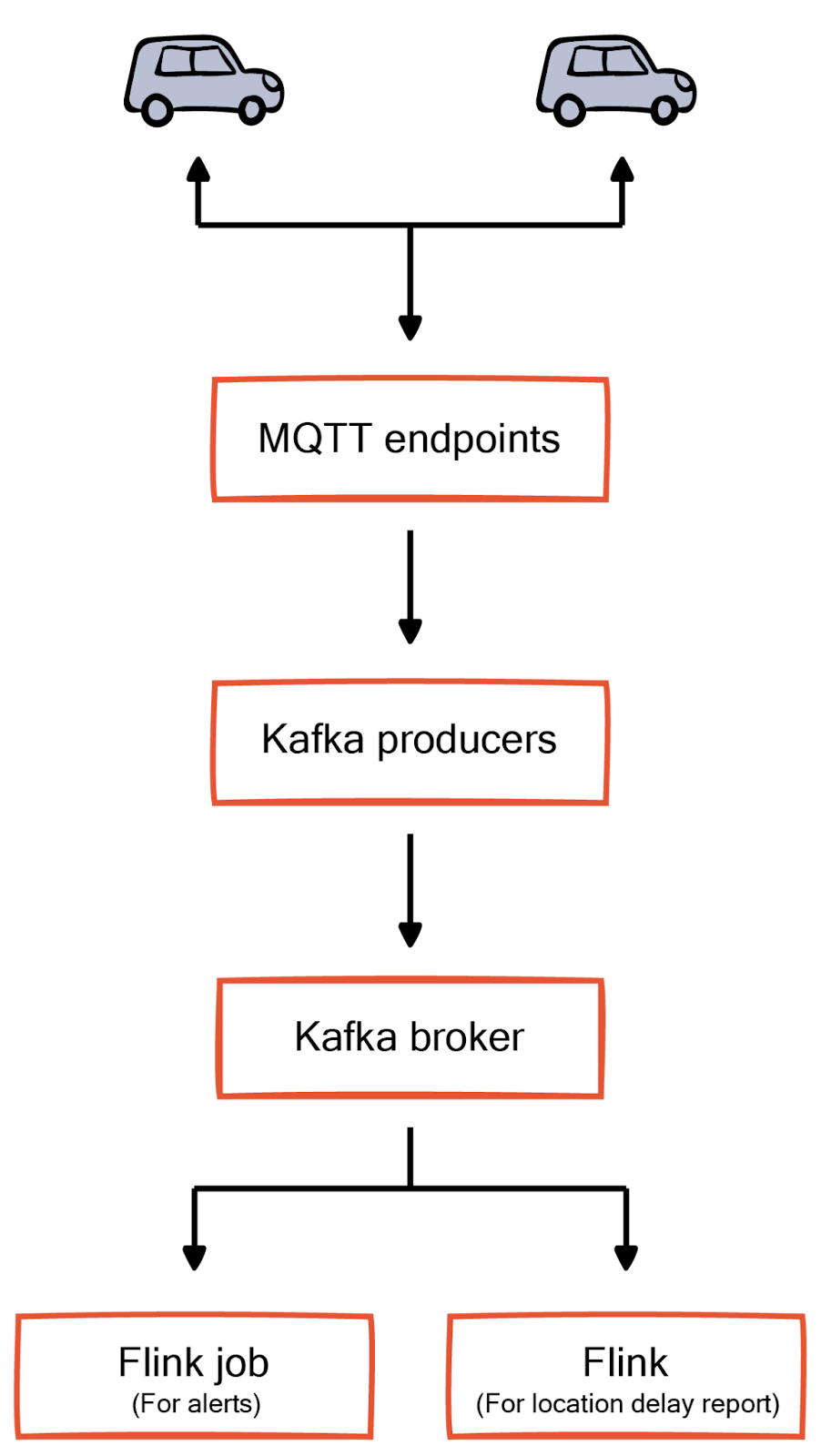
Event sourcing
The event sourcing pattern extends the concept of a never-ending immutable log to build the current state of evolving business entities. Unlike traditional systems, which only store the latest state, the event sourcing pattern saves all the events that resulted in a particular state. Since every change is an event, all operations are inherently atomic. The system's current state at any point in time can be rebuilt by replaying the stored events from the very beginning.
A challenge in the event sourcing pattern is that it’s tricky to recreate a state through simple queries. To address this, one can combine the CQRS pattern with event sourcing. CQRS, or command query responsibility segregation, separates the read and write model.
In the case of CQRS-based event sourcing, all the writers deal with the events. However, the read operations rely on a separate data model that periodically syncs by playing the events to create the latest state.
Typical applications of event sourcing patterns are as follows.
Domains where an immutable audit trail is a non-negotiable requirement
Analyzing historical data for building models and algorithms based on events
To implement highly resilient systems. An event-sourcing system can recreate its state at any point by replaying the events.
The typical architecture of an event sourcing system with a CQRS pattern in the eCommerce domain looks as below.
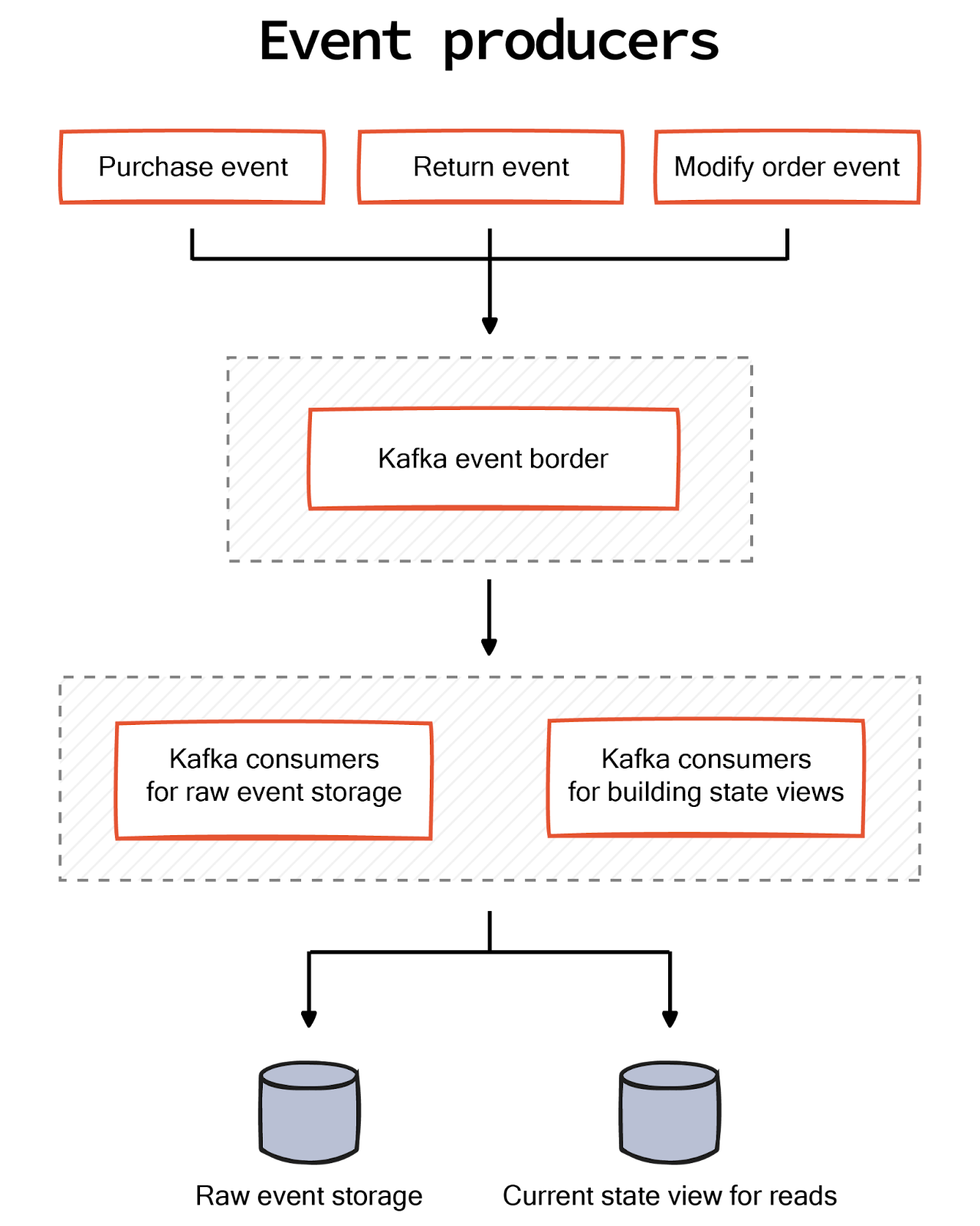
Conclusion
An event stream is an ordered sequence of changes in a system. Handling unbounded streams poses unique challenges compared to static data because events exhibit unpredictable velocity and volume. Handling such ambiguity requires a resilient and robust architecture. Depending upon the use case, you can choose a simple publish-subscribe model, a stream processing pipeline, or an event sourcing pattern for handling event streams.
A publish-subscribe model fits well for use cases that involve integrating several microservices using events or handling asynchronous task execution. Event streaming goes one step beyond and focuses on running analytics algorithms and complex event processing on streams. Event sourcing relies on events for all its state management and provides great resilience because it can regenerate the state at any time.
