
Event-driven programming
Events are discrete incidents capturing state changes in systems. These events are generated by event sources, which encompass a broad spectrum, ranging from user interfaces to IoT devices and serverless functions. Event-driven programming is a paradigm in which program execution is governed by such events, as opposed to a strictly sequential operational sequence.
Event-driven programming facilitates the development of inherently more responsive and scalable systems. By promptly reacting to events as they unfold, applications maintain high responsiveness to user interactions. They can dynamically accommodate shifting workloads.
Responsiveness and scalability are paramount considerations for real-time user experiences at scale. Event-driven programming seamlessly aligns with these imperatives. This article delves into the intricacies of event-driven programming, emphasizing best practices and implementation strategies.
Summary of key event-driven programming concepts
Concept | Description |
|---|---|
Events | Discrete incidents or occurrences that transpire within a system |
Event-driven programming | Writing programs to capture, process, and react to asynchronous events |
Event-driven architecture | Producers generate events, and consumers subscribe to them, taking action upon their occurrence. An event broker/queue mediates between producers and consumers, guaranteeing reliable event delivery. |
Event processing | Stateless processing treats each event as an isolated occurrence. In stateful processing, the system maintains information about the event's context over time. |
Event persistence | The process of storing events in a database or other storage mechanism |
Event retrieval | The process of retrieving events from storage for processing |
Key considerations | - Consistency - Atomicity - Schemas - Event catalog |
What is Event-driven architecture?
Event-driven architecture (EDA) is an architectural pattern that utilizes events as the predominant communication mode among diverse system components. In traditional architectures, components explicitly request data or services from one another, leading to a more tightly coupled system. In contrast, event-driven architectures decouple components, making systems more resilient and scalable.
Main architectural components
Producers are tasked with generating events and pushing them into the system. These entities may include user interfaces, IoT devices, or backend services.
Consumers subscribe to events and respond to them. These consumers can be individual services, microservices, or any other system component requiring action in response to particular events.
Event stores are where events are persistently stored. They serve as a reliable source of truth for the system's state.

Producing and consuming events
The producer-consumer pattern plays a fundamental role in event-driven programming. Producers generate events, and consumers subscribe to them, taking action upon their occurrence. An event broker/queue mediates between producers and consumers, guaranteeing reliable event delivery.

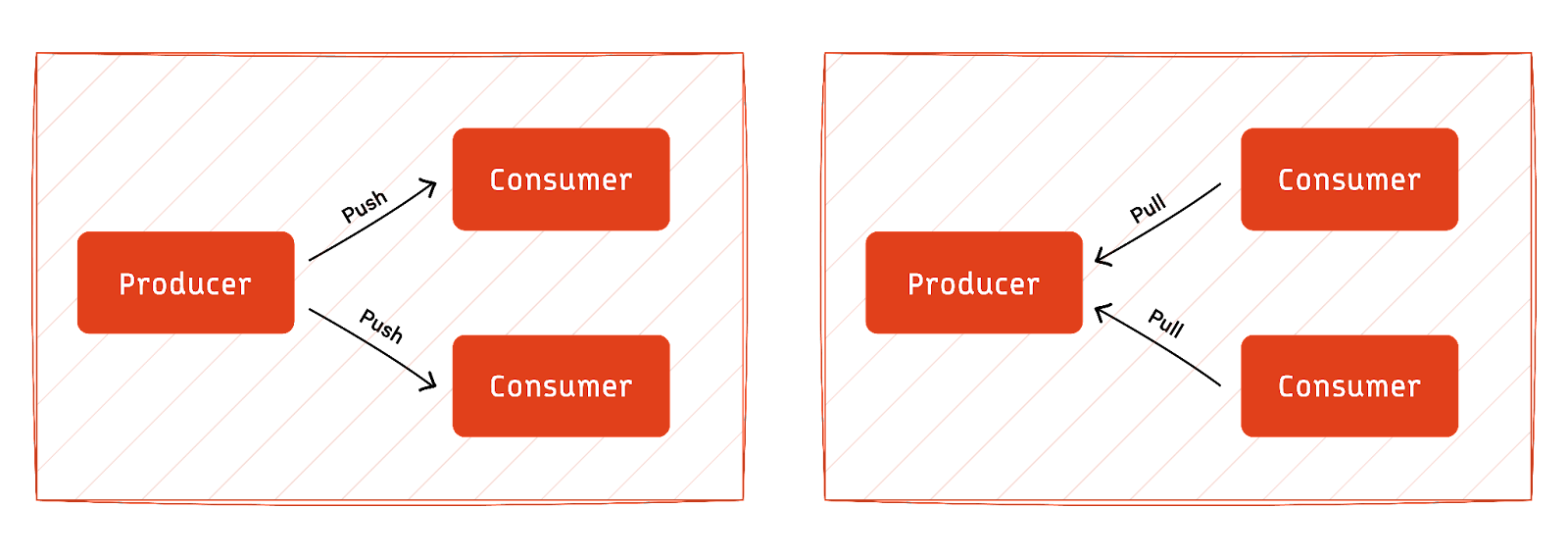
We can distill events into two primary choices when producing and consuming them.
In a push-style interaction, producers actively send events to consumers as soon as they occur.
In a pull-style interaction, consumers periodically query or pull events from a centralized event broker.
The push approach is well-suited for real-time applications where immediate action is crucial. The pull approach is more suitable for systems with less stringent real-time requirements.
Implementation approaches
Building upon the foundation of event-driven architecture (EDA), let's explore various approaches to effectively implement and leverage this paradigm. Remember that the selection of an approach depends on the unique requirements, scalability considerations, and architectural preferences of the system in question.
Event sourcing
Event sourcing is a powerful architectural pattern that provides a comprehensive method for managing and storing the state of a system by capturing changes as a series of immutable events.
In event sourcing, events represent state transitions within the system. They are not just notifications but authoritative records of system state changes. Each event encapsulates a specific state transition, capturing what has occurred in the system. These events are immutable once generated, forming an unalterable log that serves as a historical record of all state changes.
Producers are entities responsible for generating and emitting events. On the other side, consumers in event sourcing are entities that subscribe to and process these events. They update their state or trigger further actions based on the events they receive.
For instance, a producer could be an application component that receives a user command and generates an event reflecting the change requested by the user. This producer initiates the generation of events based on the actions it receives.
Event sourcing helps maintain data consistency by providing a reliable and ordered record of state changes. With each event being immutable, the system ensures that events are faithfully recorded and can be replayed to recreate the exact state at any given moment.
Command sourcing
In command-sourcing, producers are responsible for generating and emitting commands. A command represents an intention or request to change the system's state. Producers generate commands in response to user actions or external stimuli.
These commands are processed to generate corresponding events. Unlike event sourcing, where events capture state changes, command sourcing generates events due to command processing. These events represent the actual changes made to the system's state.
For example, a user interacting with a web application might trigger the generation of a command to update their profile information.
CQRS
Command Query Responsibility Segregation (CQRS) is a key architectural pattern that separates the concerns of handling command (write) operations from query (read) operations in a system. To enhance clarity, let's explore CQRS using the terminology of producers and consumers.
Producers in the context of CQRS generate commands. Commands represent intentions to modify the system's state and are responsible for initiating changes. Producers, often associated with the command side, are entities that initiate actions such as user interfaces, services, or external systems.
The command side of CQRS validates commands, enforces business rules, and initiates the appropriate actions to modify the system's state. Producers generate commands, and systems process these commands to produce events that reflect state changes.

Commands, when successfully processed, result in events. Events represent the outcome of command execution and encapsulate the changes made to the system. These events are then stored and become the source of truth for the system's state, contributing to event sourcing.
Consumers in CQRS subscribe to events and are responsible for updating their read models or projections. These consumers, often associated with the query side, process events to maintain a denormalized and optimized view of the data for efficient querying. Consumers include components such as reporting services, analytics engines, or any entity that requires read access to the system's state.
CQRS also introduces the concept of a read model, which is an optimized representation of the data tailored for querying. Projections are the mechanisms consumers use to update and maintain these read models based on the events produced by the command side. The read model is designed to serve the specific needs of consumers, improving query performance.
Event processing
In the context of an event-driven architecture, events serve as more than mere triggers; they encapsulate valuable details regarding a system's state changes and dynamics. Event processing takes this concept further by concentrating on the thorough analysis, interpretation, and purposeful usage of events to extract insights and enable intelligent responses. Event processing can be categorized into stateful and stateless approaches.
Stateless event processing
Stateless processing treats each event as an isolated occurrence, not retaining context between events. This approach is suitable for scenarios where events are processed independently.
Let's look at an example of stateless processing that computes the sum of values in a batch of data:
// Creates a DStream (Discretized Stream) by reading lines of text from a socket connection with the specified hostname and port.
val lines_read = sc.socketTextStream("localhost", 8888)
// Transforms the input by splitting each line into words, then converts each word to an integer
val numbers_read = lines_read.flatMap(_.split(" ")).map(_.toInt)
// Calculates the total sum of integers
val total_sum = numbers_read.reduce(_ + _) Stateful event processing
In stateful processing, the system maintains information about the event's context over time. This approach is useful for scenarios that require continuous monitoring and tracking of event states. Some examples of stateful operations include windowed operations, which compute aggregates over a sliding data window and update the state based on new input data.
Let’s look at the code example below.
// Establishes a DStream by reading lines of text from a socket connection with the specified hostname and port.
val lines_read = sc.socketTextStream("localhost", 8888)
// Transforms the input DStream by splitting each line into words and converting each word to an integer.
val numbers_read = lines_read.flatMap(_.split(" ")).map(_.toInt)
// Applies a sliding window operation to the DStream, creating a new DStream (window_op) that captures data from the last 10 seconds every 5 seconds.
val window_op = numbers.window(Seconds(10), Seconds(5))
// Maps each element to a tuple (1, n) and calculates the sum and count of elements within the specified window.
val totalSum = window_op.map(n => (1, n)).reduceByKey((a, b) => (a._1 + b._1, a._2 + b._2))
// Take Average
val average = totalSum.mapValues(sum => sum._2 / sum._1) Event store and event persistence
Event persistence refers to storing events in a database or other storage mechanism, while event retrieval refers to retrieving events from storage for processing. Efficient mechanisms for storing and retrieving events are crucial for the performance of an event-driven system. Implementing the right strategy ensures that events are accessible when needed without compromising system responsiveness.
Events can be stored in various ways, such as in a relational database, a NoSQL database, or a message queue. The choice of storage depends on the system's specific requirements, such as performance, scalability, and data consistency. You may consider factors like
Event volume
Desired query capabilities
Availability requirements
You can also perform event indexing to support efficient querying and filtering of events. It involves creating indexes on event fields, such as time, source, or type, to improve retrieval performance.
Essential considerations in event-driven programming
When implementing event-driven workflows, consider the following:
Consistency and concurrency
Consistency and concurrency are two important considerations in event-driven systems. Achieving and maintaining these qualities is crucial for the reliability and accuracy of the system. Consistency ensures that the system's state accurately reflects the sequence of events, while concurrency addresses the challenge of handling multiple, potentially simultaneous, operations.
The single-writer principle is a fundamental concept that ensures consistency and data integrity. It states that only one writer should be allowed to write to a given event log. This ensures that events are processed consistently, without conflicts or inconsistencies.
Locks
You can use locks or latches to synchronize event access and implement the single-writer principle. This ensures that only one writer can access an event simultaneously, preventing conflicts and ensuring consistency.
Versioning
When events are generated, they should be assigned a unique version number. This allows consumers to handle events out of order and ensures that events are processed in the correct order.
Idempotence
Idempotence means an event can be processed multiple times without changing the system's state. This property ensures that events can be safely retried if they fail, simplifying the processing of events.
Conflict resolution
Conflict resolution mechanisms resolve conflicts that arise when multiple events are processed concurrently. These mechanisms can include techniques such as versioning, arbitration, or reconciliation.
Atomicity with transactions
In event-driven systems, preserving atomicity within transactions is a fundamental requirement, especially when concurrently processing multiple events. This necessity is particularly pronounced in microservices architecture, where the autonomy and independence of each microservice are pivotal aspects of the overall architecture.
Define clear boundaries
To effectively achieve atomicity within transactions in such an environment, it is essential to delineate clear boundaries for each microservice. These boundaries define the ownership and data modification rights, ensuring that each microservice operates independently and that transactions are meticulously managed. By explicitly specifying what data a microservice owns and can modify, this approach safeguards against inadvertent conflicts during event processing.
Use a transactional framework
A transactional framework manages transactions across multiple microservices, ensuring that all events are properly coordinated and the system remains consistent. Popular transactional frameworks include Saga, Axon, and Spring Cloud Transacted.
Schemas to manage data evolution
Using schemas to manage the evolution of data over time is an essential aspect of event-driven systems. Schemas provide a structure for data that can be used to ensure consistency and integrity as data evolves over time.
Define a schema for each data entity in your system, including the fields and their data types. That way, all events that contain data for a particular entity conform to the same structure, making it easier to process and analyze the data.
Define a schema versioning strategy that includes each schema's version number or identifier. When making changes to a schema, ensure that the new version is backward-compatible with previous versions. Backward compatibility ensures that events processed with older schema versions are correctly handled. The system remains in a consistent state, even as new versions of the schema are introduced.
Event catalog
An event catalog is a centralized repository of all the events that occur within an event-driven system. It provides a common language and understanding of the events exchanged between different system components.
The event catalog should have a clear structure that makes it easy to navigate and understand. You can categorize events by type, such as user, system, or business events.
Document the relationships between events, such as which events trigger other events or which events are triggered by other events. This helps developers and business stakeholders understand how events are connected and how they fit into the overall system architecture.
Have questions about Kafka or streaming data?
Join a global community and chat with the experts on Slack.
Conclusion
In conclusion, event-driven programming is not merely a buzzword but a transformative paradigm in modern software development. By harnessing the power of events, systems can achieve enhanced responsiveness, scalability, and adaptability.
This article delved into event-driven programming with a technical focus, highlighting best practices and implementation strategies. As engineers, staying informed and embracing these practices is imperative to meet the continually evolving demands of today's software development landscape.
