Leave compromises in the dust with flexible per-topic controls and predictable durability guarantees

Redpanda has always emphasized strong data durability guarantees as a hallmark of its design. However, the usage of streaming data platforms has broadened to a point where not every stream leads to a system-of-record. Customers have told us they want more flexibility in choosing between these durability guarantees and higher performance, especially for new use cases.
Customers also want broader choice in storage devices to fit into existing network-attached storage architectures or squeeze more operating costs out of their infrastructure budgets. They don’t want to sacrifice Redpanda’s rock-solid data safety guarantees altogether but instead, choose them on a use-case-by-use-case basis.
For these reasons, we introduced write caching in Redpanda 24.1, which offers both game-changing performance benefits and the ultimate level of control over data safety, performance, and storage infrastructure costs. In our latest benchmarks, we demonstrated that write caching can achieve 90+% lower latencies on a wider range of storage and also reduces CPU utilization.
In this blog, we walk you through how write caching works and the benchmark results that underscore its positive impact on application performance in your streaming data infrastructure.
What is write caching and how does it work?
Write caching offers a new form of the acks=all producer configuration supported by the Apache Kafka® protocol. On the durability spectrum, It sits between acks=0 (fire and forget) and Redpanda’s traditional acks=all/-1 behavior, which provides extremely strong durability guarantees.

Without write caching, configuring acks=all not only replicates to a majority of brokers in the Raft quorum of a partition but also flushes data to disk on those same brokers before acknowledging a message to the client. This permits all data to be recovered, even after a correlated failure of any number of brokers or the pods/instances running them, as long as the storage devices themselves are durable.
Write caching introduces an in-memory buffer on each broker and defers writes to disk until a configurable buffer size or flush interval has been reached. With an acks=all producer configuration and write caching enabled, producer requests are acknowledged after data is replicated but before it is written to disk. This makes more efficient use of precious I/O bandwidth (IOPS) and enables Redpanda to maintain lower latency, even with higher latency storage devices such as Amazon EBS or block-based network storage appliances.
Here’s an illustration of how messages are replicated with and without write caching before the client receives an ack.
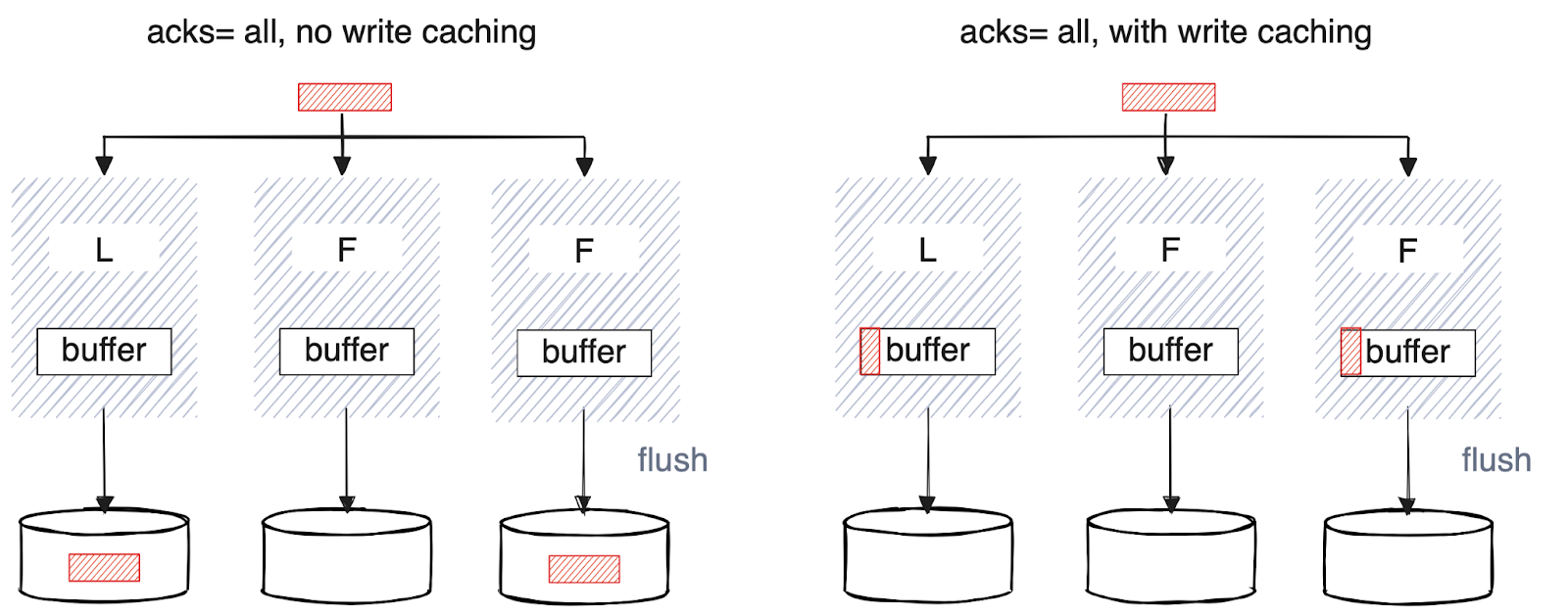
Of course, there's a durability tradeoff to be paid here. While a majority of brokers, often in different cloud availability zones, will have a consistent view of the data, a correlated failure of the entire cluster or a majority of brokers hosting a partition at the same time (e.g., a rare multi-AZ outage) could result in a small amount of data loss. This, coupled with very low out-of-the-box defaults for flush.ms/bytes, makes this scenario unlikely.
This is also the case with Kafka using acks=all, where multiple instance failures could result in a loss of acknowledged data residing in the OS page cache. This is why it's so important to have controls at the application level to define durability guarantees.
Using write caching in your streaming applications
Above all, customers told us they want a seamless experience while migrating existing Kafka applications to use write caching. We’ve taken that to heart by not only providing a simple per-topic configuration property write.caching=true, but also a global default that automatically opts into/out of write caching for all topics on the cluster.
Setting the cluster configuration write_caching_default=true means all topics will automatically use write caching with zero config or code changes to your applications.
Furthermore, to align with apps that have been finely tuned for Kafka’s durability behaviors, we added support for Kafka’s existing flush-tuning properties flush.ms, flush.bytes which define flush intervals from the OS page cache to disk in Kafka. In Redpanda, these properties control write caching similarly, in specifying exactly how frequently we sync broker state to durable media using fdatasync().
Beyond easy application migration, the topic-wise approach unlocks a game-changing degree of flexibility.
Unlike other systems bound by rigid speed/durability/cost trade-offs that force a choice at the technology or cluster level, Redpanda supports both mission-critical and relaxed-durability workloads running side by side in a single cluster — in the cloud, on-premise, or at the edge.
This unparalleled flexibility is crucial for organizations investing in a versatile, long-term streaming data infrastructure that supports diverse use cases that should be fully portable across environments.
Write caching benchmarks
Let’s talk about how this performs at scale. We benchmarked two different setups to test-drive write caching in various scenarios. These represent the two key use cases we designed after working with customers:
Running select workloads with relaxed durability requirements on direct-attached NVMe devices. NVMes are typical for Redpanda deployments and are suitable for running mission-critical, highly durable, and low-latency operational workloads. But these workloads can just as easily share a cluster with the ‘relaxed durability’ workloads ideal for write caching.
Running relaxed durability workloads on higher latency storage devices. Higher latency storage with fewer IOPS is often the norm in lower-end cloud instances, in on-premises storage appliances or private cloud environments, and sometimes in cloud block storage services such as Amazon EBS, (a popular choice in Kafka cloud deployments).
Understanding the setup
Let’s have a look at the benchmarking setup for all of our test scenarios.
For all of our tests, we have a cluster of 9 im4gen.8xlarge instances in AWS, using different storage devices representing our use cases above. Storage types are indicated in the results. The EBS storage used 2 2TB GP3 volumes per node with 16K IOPS and 1GB/s throughput.
For each test, we used the Open Message Benchmark framework with different workload configurations, as shown below, including the producer/consumer configuration common to all tests. All tests were run for 30 minutes.
Workload 1: Used in sections "Producing performance" and "Going faster on a broader range of hardware."
topics: 1
partitions_per_topic: 1395
subscriptions_per_topic: 2
consumer_per_subscription: 240
producers_per_topic: 240
consumer_backlog_size_GB: 0
warmup_duration_minutes: 5
test_duration_minutes: 30
producer_rate: 1171875 (~1.17GBps)
message_size: 1024Workload 2: Used in the section "Pushing the limits."
topics : 1,
partitionsPerTopic : 2000,
messageSize : 1024,
subscriptionsPerTopic : 2,
producersPerTopic : 500,
consumerPerSubscription : 250,
producerRate : 1800000 (~1.8GBps),
consumerCount : 500
consumerBacklogSizeGB : 0,
warmupDurationMinutes : 1,
testDurationMinutes : 30,Producer configuration (all tests)
enable.idempotence=true
acks=all
linger.ms=1
max.in.flight.requests.per.connection=5Consumer configuration (all tests)
auto.offset.reset=earliest
enable.auto.commit=falseNow, let's look at the results and see how the benefits of write caching stack up.
Producing performance!
When it comes to performance, write caching shows up most directly in the Produce latency, or so-called publish latency of workloads. This is where write caching makes more efficient use of IOPS by batching up writes to disk and performing less frequent but more efficient writes to disk, reducing latency as data is streamed into topics.
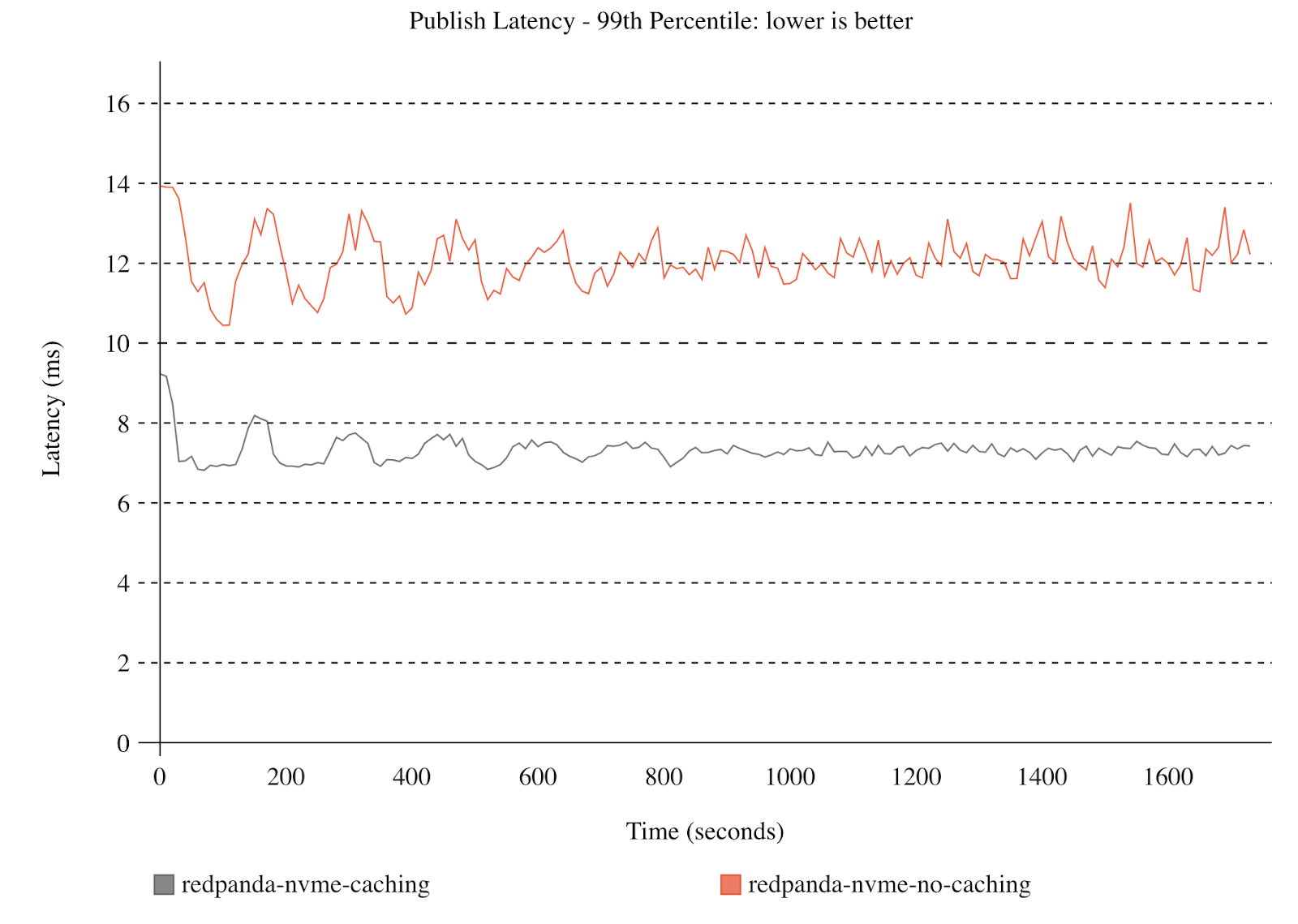
Here’s the P99 “publish/produce latency” observed in an Open Message Benchmark workload running on NVMes, with and without write caching. Even on high-performing storage devices, we see a substantial performance benefit because Redpanda decouples disk writes from the produce path.
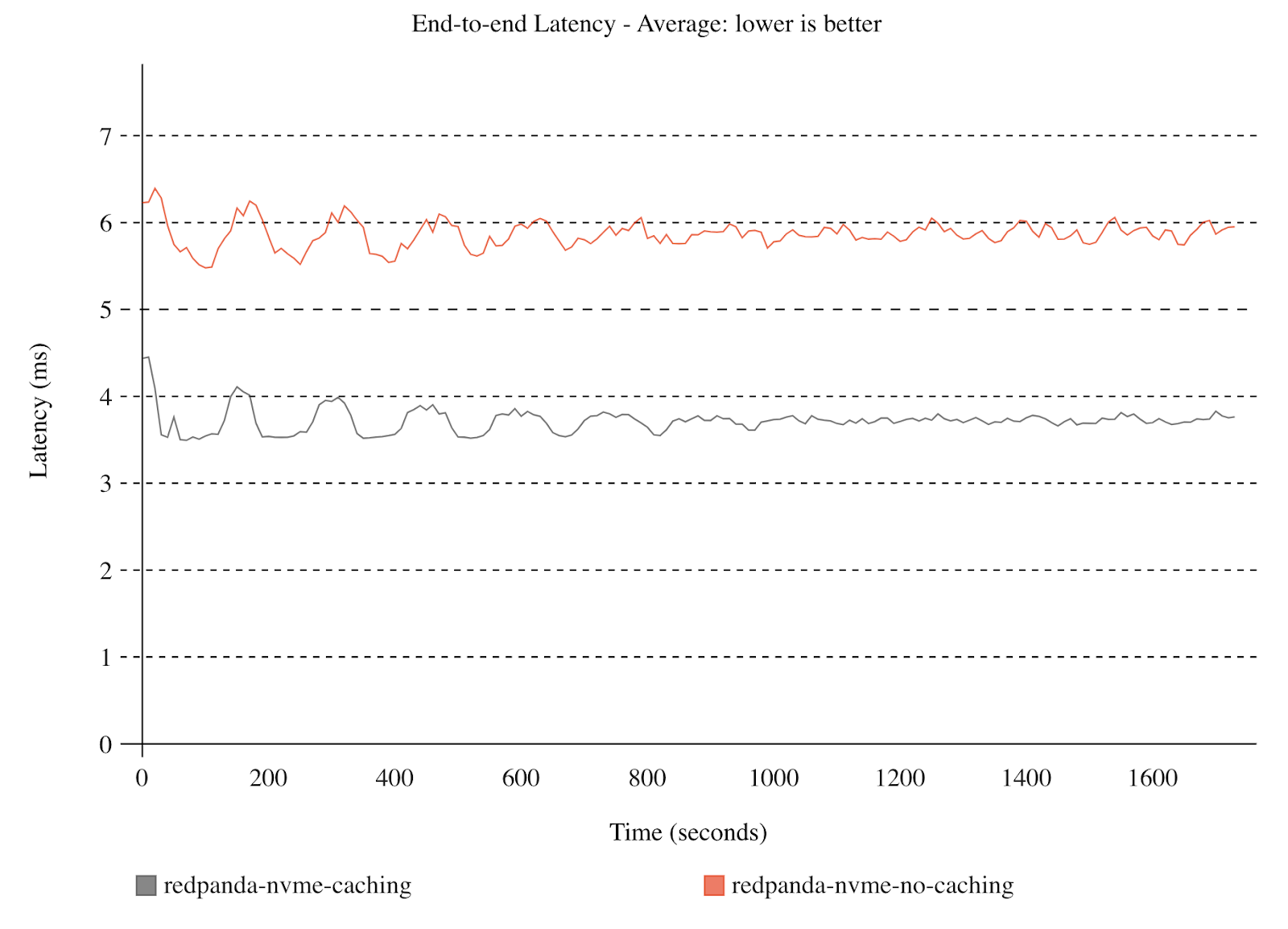
These latency-reducing benefits accrue directly to the bottom line end-to-end (E2E) latency. Here we see the average latency of the same workload with and without write caching.
Going faster on a broader range of hardware
As we alluded to above, write caching really shines on higher latency network-attached storage devices, which provide users the benefits of being highly reliable, detachable, and independently scalable.
Here we run our workload on an Amazon-EBS backed Redpanda cluster, and plotted the median (P50) end-to-end latency over time, as well as the overall end-to-end latencies observed throughout the entire test. Notice the dramatic drop in median, P90, and P99 latencies and the smooth, low P50 observed throughout the 30-minute benchmark.
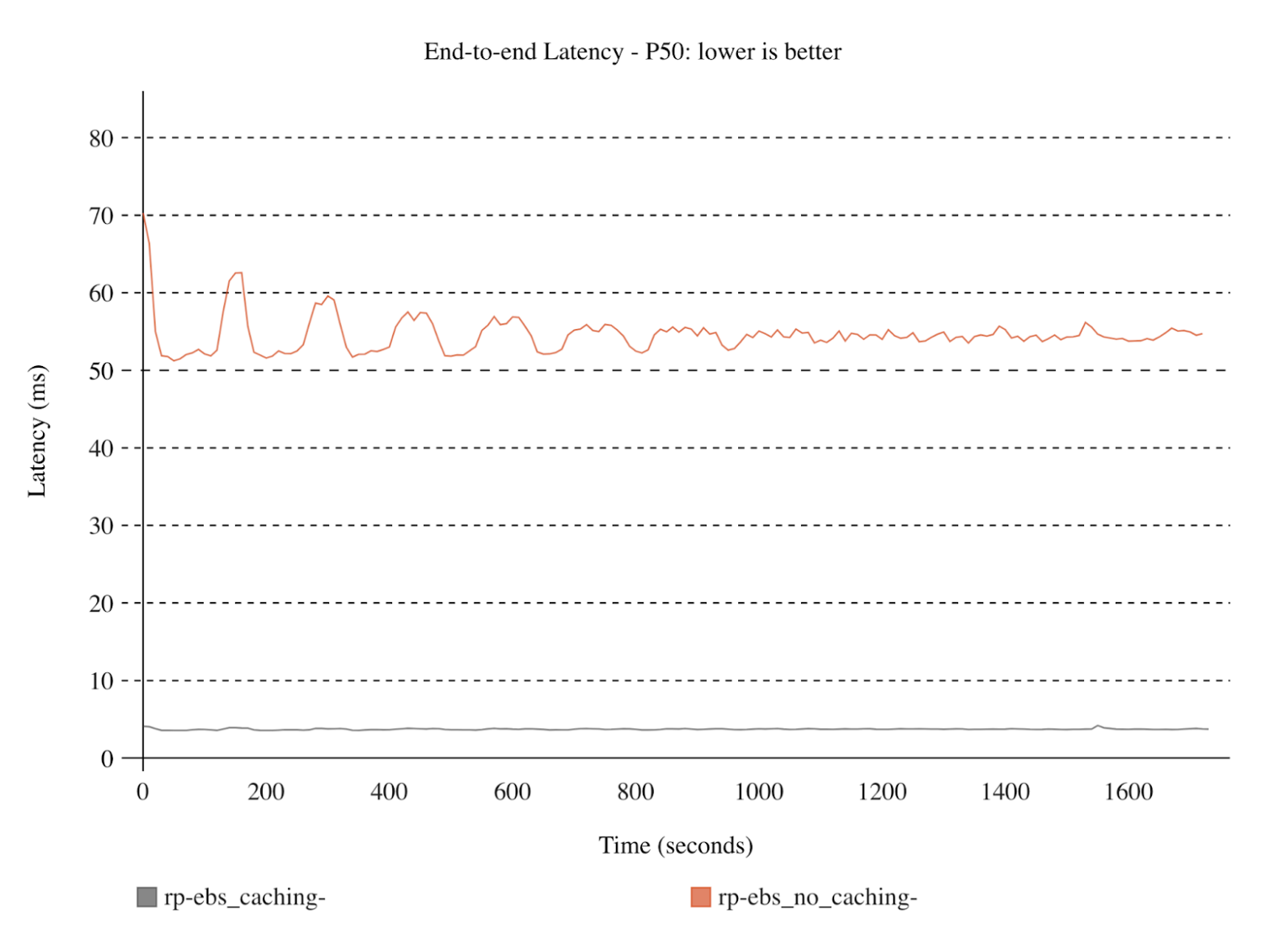
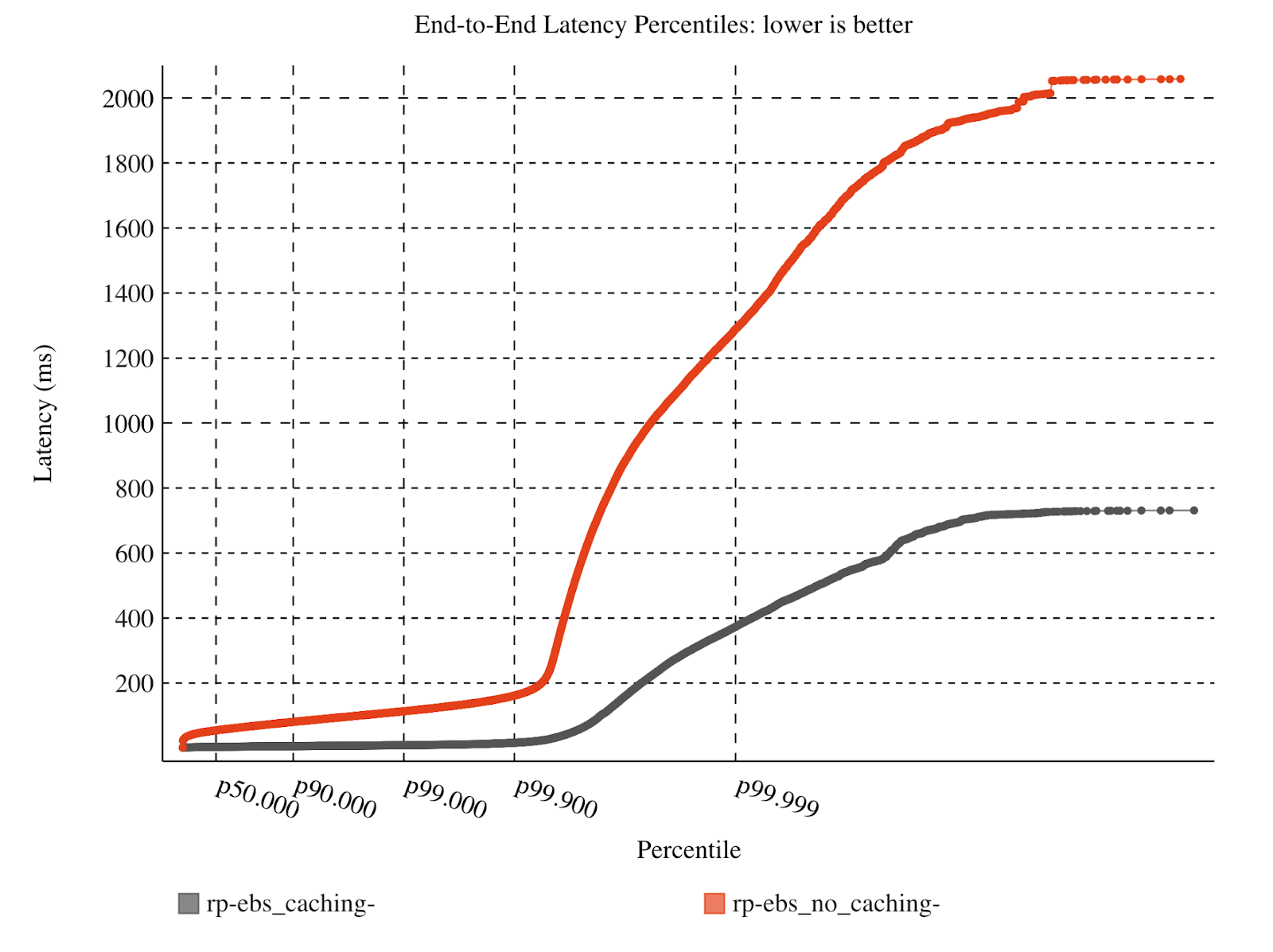
You’ll note that Redanda without write caching shows rather high end-to-end tail latency (> P99.9). This is largely due to sub-optimal write patterns that exhaust the IOPS limit for the EBS disks. However, for most users, the P99, P90, and P50 are what matters. Here still, the difference is massive at roughly 8.5ms P99 with write caching and 113ms P99 without.
That’s more than a 90% reduction in latency with the added flexibility of using resizable, detachable Elastic Block Storage.
Pushing the limits
We wanted to explore an extreme case to highlight the maximum benefit write caching can deliver, so we used a more ‘strenuous’ workload with various setups.
This workload purposefully saturates the CPUs on a cluster with network-attached storage without write caching, partly due to the many small (4KB) write requests to disk. This saturation generates back pressure to clients and results in a smaller-than-normal effective batch size, creating further inefficiency and a situation that's effectively more than Redpanda can handle (with acceptable latency).
We also ran that same strenuous workload on an NVME-backed cluster.
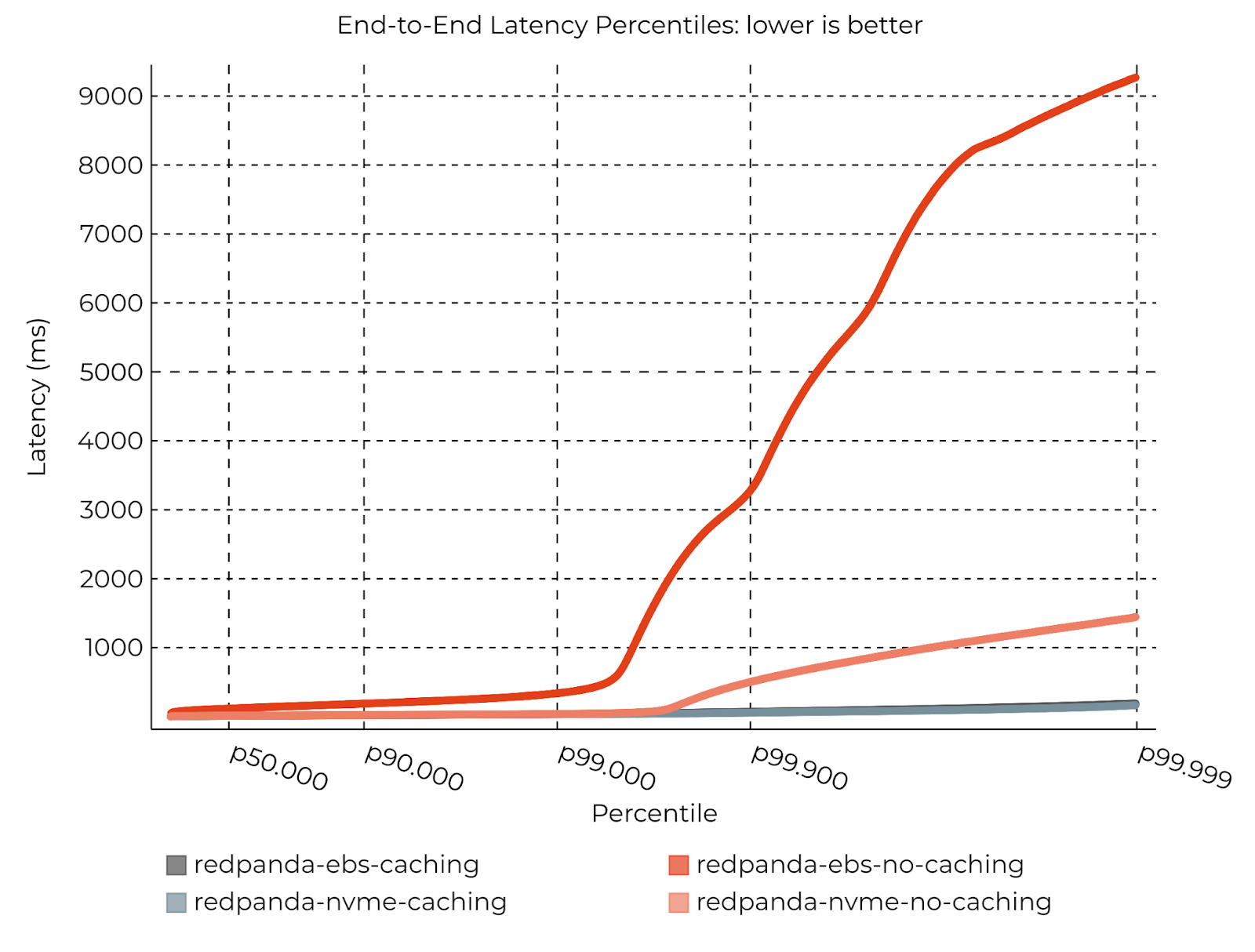
The results speak for themselves. While write caching performs consistently well on both setups (33ms P99), tail latencies are orders of magnitude lower, and the advantage is most pronounced on EBS, where the latencies are unacceptably high without write caching.
Again, this is because with write caching, Redpanda spends less time handling write requests and more time processing Kafka requests. In a cluster that's pushed to its limits (perhaps during times of peak load), that extra efficiency is a game changer.
Note: If you’re wondering, the dark gray line is barely visible because write caching performed so consistently on both setups.
CPU efficiency
Write caching not only unlocks lower latency workloads and maintains acceptable latencies on a broader range of hardware, but also reduces CPU utilization by approximately 10%. This provides extra headroom to handle throughput spikes or support adding additional consumers or partitions in existing applications, without adding hardware to your cluster and helps you control infrastructure costs.
The verdict: write caching delivers better performance, lower costs, and more flexibility
Protecting every byte, even in the face of infrastructure failures, is paramount for system-of-record streams. Write caching offers unmatched flexibility in a world of mixed streaming workloads that include analytics and ephemeral data. It balances reliable performance, durability, efficiency and infrastructure choice, giving you control over the levers to deliver maximum value to your organization while minimizing your IT infrastructure costs.
Interested in trying it yourself? Sign up for a free trial to take write caching for a spin! If you have questions about these benchmarks and want to chat with our engineers, ask away in the Redpanda Community on Slack.

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



