Follower fetching in Redpanda 23.2 and Redpanda Cloud means no more choosing between cost, consistency, and performance

Last week we announced the beta release of Redpanda 23.2 in our Redpanda Community on Slack. 23.2 is packed with new features that improve performance, automation, and cost optimization. One of the most important new capabilities of 23.2 is follower fetching.
In this post, we explain what follower fetching means, and present an example to illustrate how it can help you save big on your cloud infrastructure bill.
What’s follower fetching?
In the simplest terms, follower fetching enables your Redpanda consumers to fetch records from the closest physical replica of a topic partition, regardless of whether it’s a leader or a follower.
Seasoned Apache Kafka® users may be familiar with follower fetching from running multi-rack or multi-AZ Kafka deployments. It was originally created to minimize cross-rack network traffic when hardware couldn’t keep up with the demands of high-throughput applications. Now, follower fetching has taken a different (but more meaningful) role as a way to significantly reduce cloud network costs for large streaming data clusters.
As fault-tolerant multi-AZ deployments become the norm for streaming data in the cloud, the infrastructure costs of sustaining high-throughput stream processing are substantial since most cloud providers levy extra charges for network traffic that crosses availability zones. This can lead to sticker shock when reading your cloud infrastructure bills. And, as traffic prices increase, companies focus more on collocating applications with the services they depend on, within the same AZs.
There’s plenty of opportunity here to reduce spend by optimizing network traffic, and follower fetching does just that. Below is a quick visual of what follower fetching looks like for a Redpanda topic.
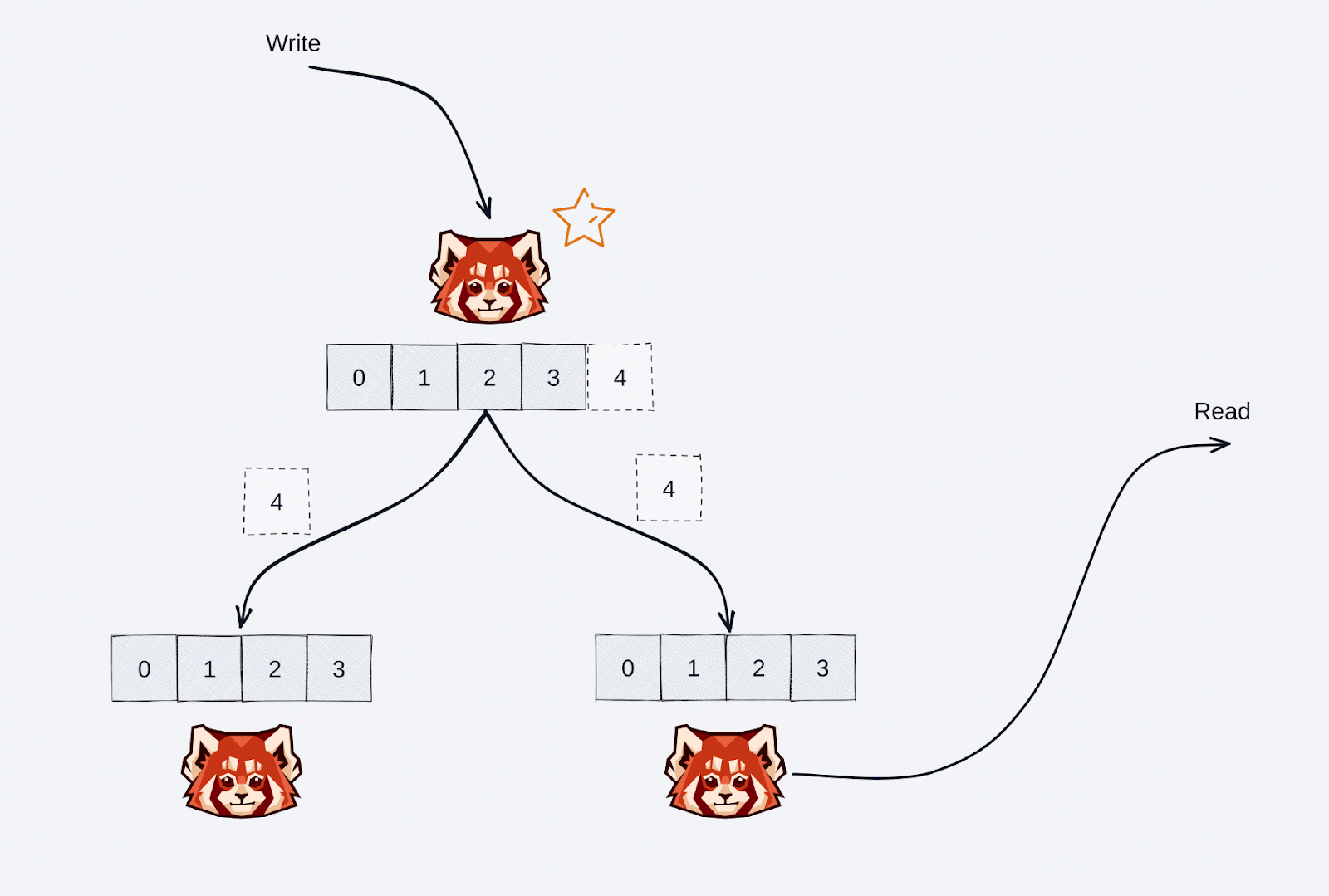
As before, all data written/produced to a topic’s partitions must be written to the “leader” replica of the partition, hosted on a particular node. Data is then transparently replicated to other replicas on other nodes, which “follow” the leader’s current offset or “high water mark.”
What’s different about follower fetching is that consumers can now read data from any replica in the replica set of the partition. With the proper configuration, consumers can even pick the closest available replica in the cluster topology to:
Help shape network traffic for the lowest cost by minimizing cross-AZ reads
Minimize read latency for consumers
Support additional read throughput by efficiently using the network bandwidth of all nodes in the cluster.
With follower fetching in Redpanda, you no longer need to make tradeoffs between cost, consistency, and performance. Let’s see how it works with a quick example.
Reducing your cloud infrastructure bill with Redpanda follower fetching
In this example, a hypothetical customer — Acme Corporation — has a streaming data workload running in AWS with the following characteristics:
Avg ingress (MB/s) | 300 |
Avg egress (MB/s) | 1800 |
Peak ingress (MB/s) | 2300 |
Peak egress (MB/s) | 5600 |
To run the workload, Acme is using a 3-AZ Redpanda BYOC deployment on AWS using im4gn.4xlarge instances in us-east-2. Assuming that Acme doesn’t have follower fetching enabled in Redpanda, after discounting, Acme’s monthly AWS bill looks like this:
Compute cost | $12,573 |
Networking cost | $103,680 |
Total monthly costs | $116,253 |
Total yearly costs | $1,395,036 |
By enabling follower fetching, Acme Corporation can eliminate the majority of its cross-AZ consumer traffic, which in turn reduces its monthly networking costs by 60%, from $103,680 to $41,472. This translates to a 53% annual savings in AWS infrastructure costs.
Monthly AWS bill (no follower fetching) | Monthly AWS bill (follower fetching enabled) | |
|---|---|---|
Compute cost | $12,573 | $12,573 |
Networking cost | $103,680 | $41,472 |
Total monthly costs | $116,253 | $54,045 |
Total yearly costs | $1,395,036 | $648,540 |
This is an example at the higher end of savings where the workload has a relatively high average egress. Of course, the potential cost savings from enabling follower fetching will vary based on your specific workload’s cross-AZ traffic volumes.
It’s worth noting that one of our beta customers expects to save up to 50% of their cloud infrastructure costs—simply by enabling follower fetching. This is because with several times more egress traffic than ingress traffic (not uncommon in publish/subscribe streaming), their current cross-AZ traffic costs nearly equal the baseline instance cost of running their clusters in Amazon EC2.
Start saving on cloud costs with follower fetching in Redpanda!
Redpanda follower fetching is currently in beta and will be generally available in the coming months. To learn more about beta participation, check out the 23.2 beta announcement, if you haven’t already.
To enable follower fetching in Redpanda using the 23.2 beta release, you just have to configure properties for the consumer and the Redpanda cluster and node:
For a Redpanda cluster, set the
enable_rack_awarenessproperty totrue.For each Redpanda node, set the
rackproperty to a specified rack ID / name of the node’s AZ.For each consumer, set the
client.rackproperty to a specified rack ID / name of the node’s AZ.
For additional information on exactly how follower fetching works, check out our beta documentation. To learn more about how Redpanda helps companies stream data faster at lower cost, check out our customer stories and browse the Redpanda Blog for examples and step-by-step tutorials. To see it in action for yourself, try Redpanda for free!
If you have questions about follower fetching or getting started with Redpanda, ask our team in the Redpanda Community on Slack.

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



