Streaming data in real time just got a whole lot simpler
Redpanda engineers are always looking to create more “easy buttons” for streaming data. In keeping with this mission, Redpanda Connectors are fully-managed solutions for integrating different data systems with your real-time clusters in Redpanda Cloud.
These source and sink connectors are directly supported by Redpanda Cloud and remove the need for manually building integrations with the Kafka API or Kafka Connect. And, they’re available right in the Redpanda Console.
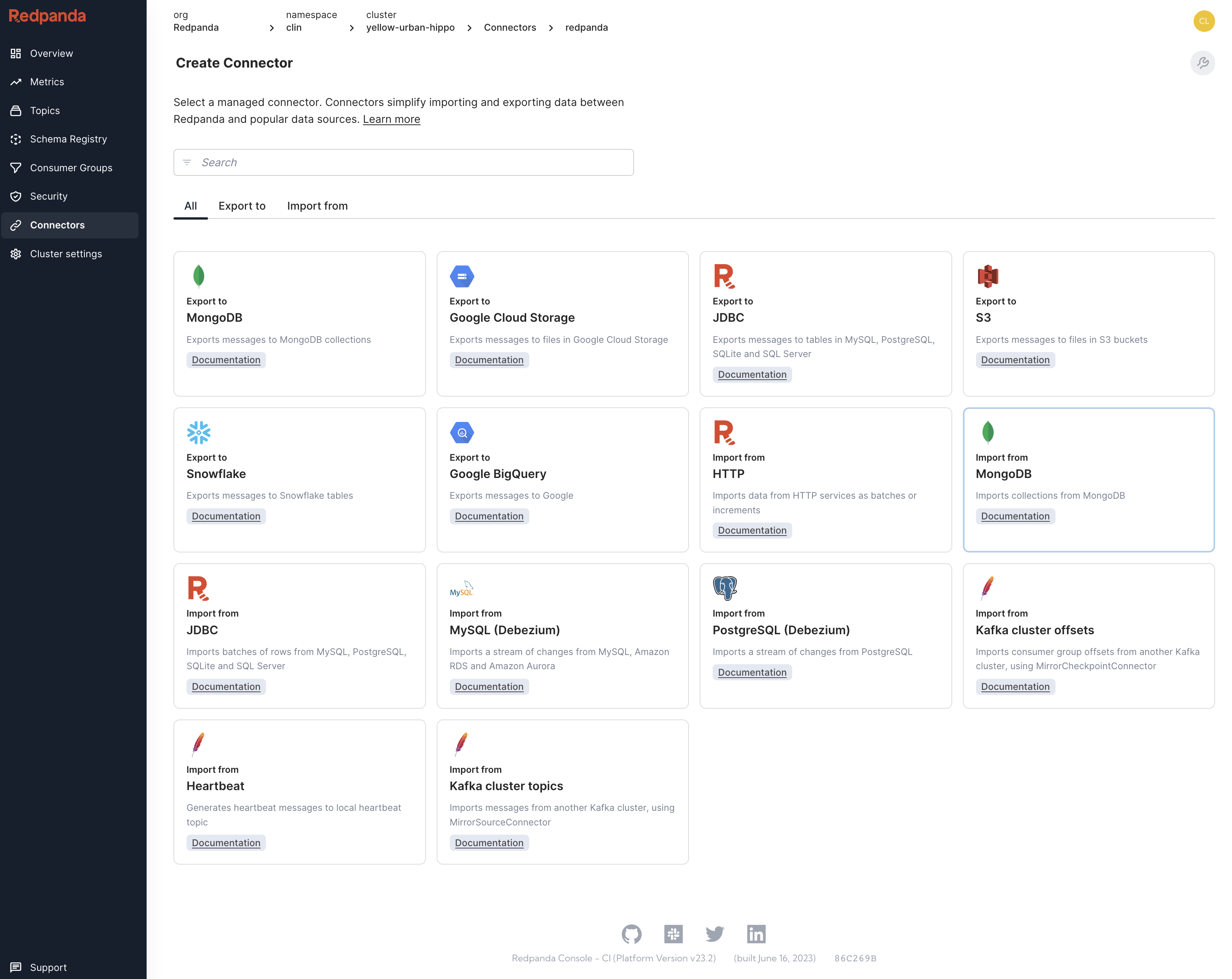
To accelerate developers, data engineers, and architects building with Redpanda and popular database systems, we recently launched new managed connectors for:
MongoDB (source and sink)
MySQL, PostgreSQL, SQLite, SQL Server / JDBC (source and sink)
HTTP (source)
These add to our existing menu of managed connectors for popular data systems including Amazon S3, Google BigQuery, MySQL, PostgreSQL, and Snowflake. Let’s take a quick look at the new data connectors now available to any Redpanda Cloud user.
MongoDB (source and sink)
Let’s start with our connectors for MongoDB, the super-popular NoSQL database loved by developers worldwide for its ease of use and simple, scalable data model. Redpanda typically integrates with MongoDB when:
Redpanda events are exported to MongoDB for inserts or updates.
Changes in MongoDB collections are imported to Redpanda topics for other applications to consume. Generally, this is actively growing data like logs, clickstream, user behavior, and audit data.
Previously, these integrations were done manually using Kafka Connect by leveraging Redpanda’s Apache Kafka wire compatibility. But now, you can use Redpanda’s fully managed and supported MongoDB Source and MongoDB Sink Connectors to build real-time and event-driven applications even faster.
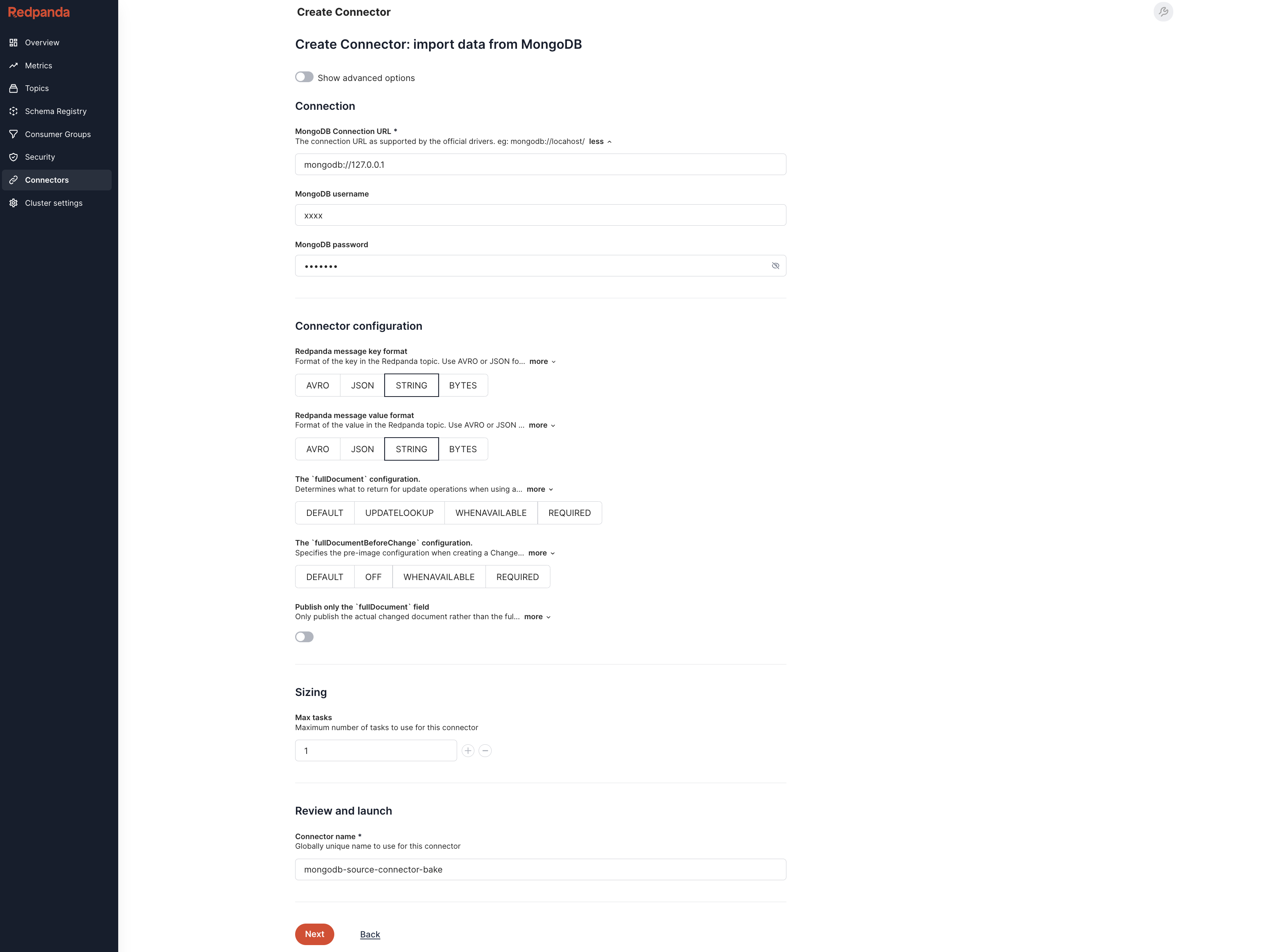
Setting up MongoDB connectors in Redpanda is straightforward. Before you begin, make sure you have a MongoDB deployment with the required access credentials and network connectivity, allowing Redpanda to connect to the database. Specifically, ensure that the role has the read right to the admin database for logs and the "listDatabases" privilege in the config database.
To configure MongoDB connectors in Redpanda, you can rely on the user-friendly Redpanda UI, which provides step-by-step guidance. Once the configuration is complete, the connector will use MongoDB's oplog (operation log) to capture and track changes occurring in the database.
As MongoDB uses replica sets for high availability, each replica set maintains its own independent oplog. When using the MongoDB connector, it automatically attempts to assign a separate task for each replica set. Depending on your requirements, you have the flexibility to adjust the maximum number of tasks that the connector can use.
MySQL, PostgreSQL, SQLite, SQL Server / JDBC (source and sink)
Relational databases are often used as a source for Redpanda, importing batches of rows from relational tables into Redpanda topics. Use cases for RDBMS as a source include database synchronization and audit logging. Redpanda can also sink real-time data to relational databases for any number of downstream applications.
Now, Redpanda has introduced managed connectivity to MySQL, PostgreSQL, SQLite, and SQL Server using the JDBC connector.
For developers integrating relational databases with streams, Redpanda’s managed Source and Sink Connectors for MySQL, PostgreSQL, SQLite, and SQL Server via JDBC remove the need for manual Kafka Connect-based solutions when integrating Redpanda with relational database systems.
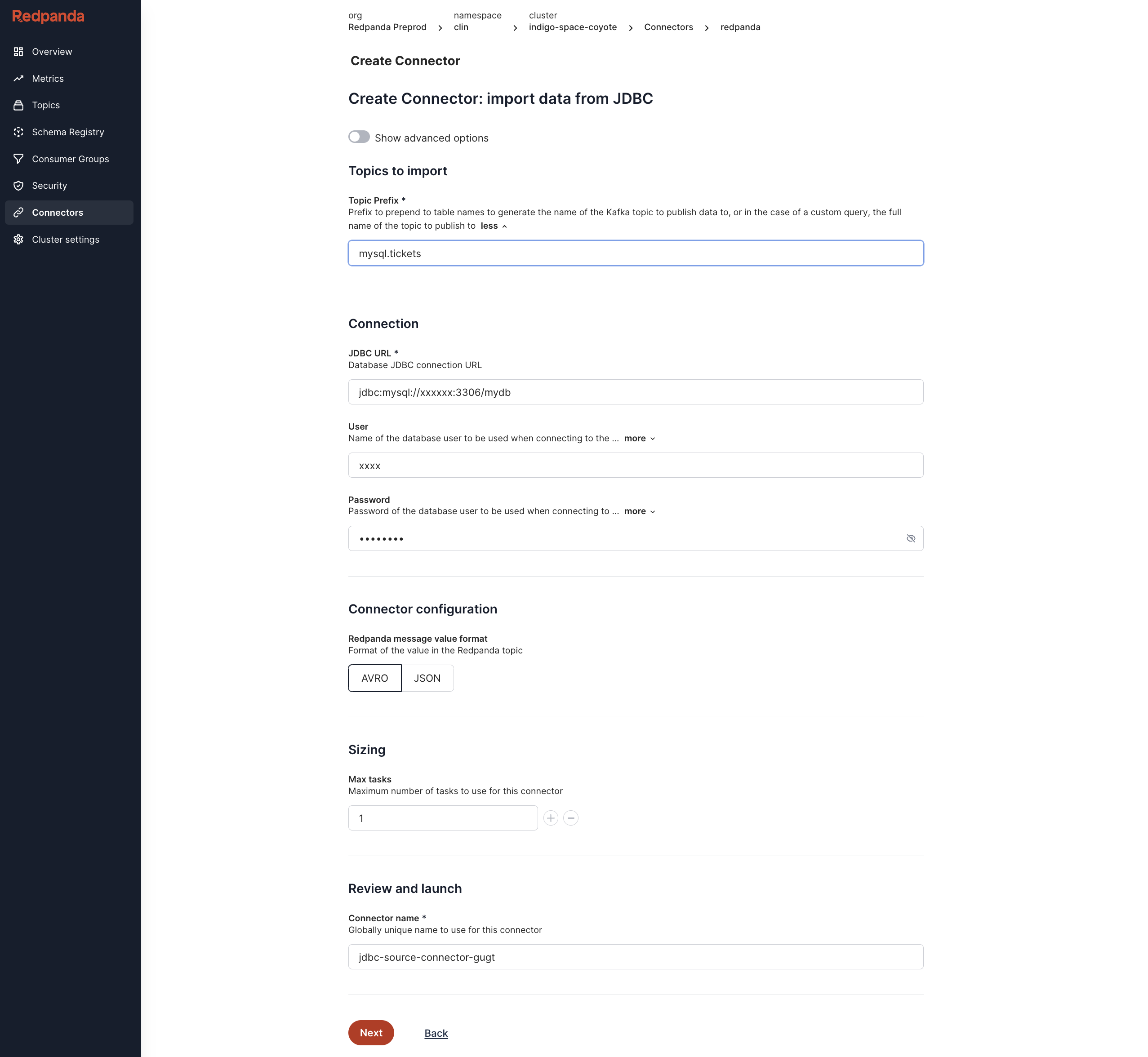
To configure the connector, make sure the database user specified in the connector's configuration has appropriate privileges for the required operations (such as read access to the source tables and write access to the target tables, as well as access to the change logs).
It’s best to specify either a whitelist or a blacklist of tables to include or exclude from the connector's operations to avoid capturing unnecessary events. To improve performance, increase the maximum number of tasks to enable more concurrent reading and processing of changes from multiple source topics.
Note: for low-latency data imports, check out the Debezium-driven CDC connectors for MySQL and PostgreSQL.
HTTP (source)
When you’re just looking to import data from an HTTP source to Redpanda, for example, to enable change data capture (CDC) from JSON/HTTP APIs, Redpanda now has a fully managed HTTP source connector. The connector periodically polls the HTTP endpoint to import data to Redpanda topics. This makes it super simple for web services to produce messages to Redpanda, without needing to use Kafka APIs or language-specific libraries.
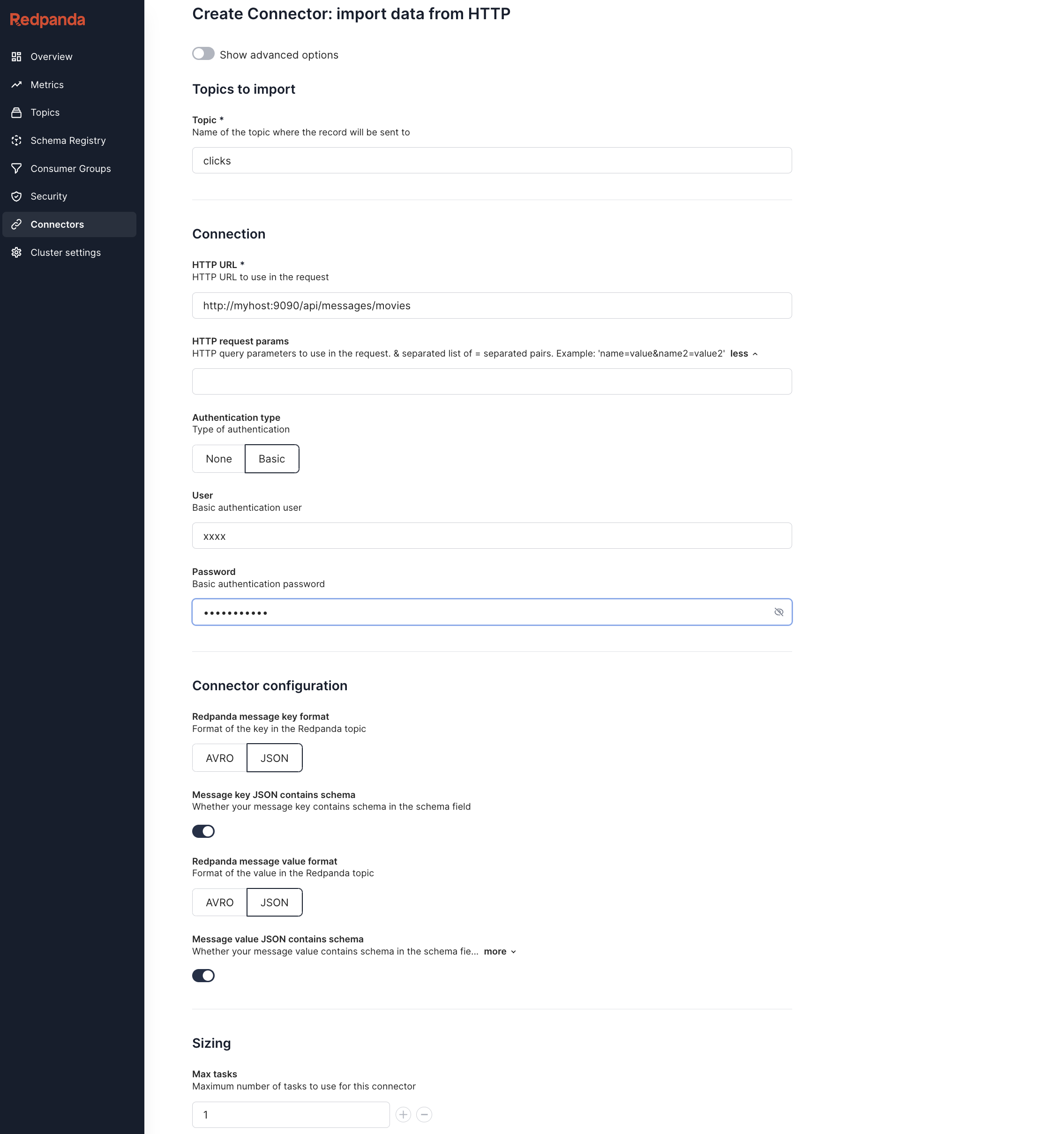
Redpanda also supports basic authentication with credentials for the API endpoint.
Getting started
If you’re building data applications with Redpanda, browse our library of fully-managed connectors to see how we can support the other parts of your data stack, and reduce the manual effort involved in moving data up and downstream of your clusters. You can also check our documentation for detailed walkthroughs to help you create your first connectors.
We’re continually working on adding new source and sink connectors based on customer demand, so jump into our Redpanda Community on Slack and let us know if your data store of choice is missing from the list!
To kickstart your fully-managed Redpanda cluster with simple, intuitive connectors, take Redpanda Cloud for a test drive!

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



