Get predictions on the fly using real-time data with simplified data transformations—powered by WASM

In the world of machine learning, change is the only constant. The traditional reliance on large, batch-processed datasets is giving way to a more dynamic, real-time data approach. This evolution is driven by the understanding that the ability to process and analyze data in real time is not just an advantage—but a necessity.
This is particularly true in sectors like the food-delivery ecosystem, where customer expectations and business needs can switch at the drop of a hat. Here, streaming data engines, like Redpanda, emerge as key players transforming the landscape of data processing and machine learning.
In this post, you'll see an example of how to use Redpanda Data Transforms (powered by WebAssembly) for real-time predictions in an ML-driven food delivery application.
The predicament with batch-processed data
Food delivery time prediction has traditionally relied on batch-processed data. This method, while somewhat effective, often leads to stale insights due to the latency between data collection and processing. The data variables typically include the delivery partner’s mode of transport, age, ratings, and the crucial metric of distance between the restaurant and delivery location.
Enter streaming data: the real-time revolution
In recent years, the food delivery industry experienced a tremendous spike in demand. This surge, partially driven by the pandemic, highlighted the painful limitations of batch-processed data models and underlined the need for real-time data processing. Real-time data processing allows immediate insights and adaptability — key components in an industry driven by time-sensitive customer expectations.
Streaming technologies, like Apache Kafka®, bubbled up to solve the challenges brought on by the influx of real-time data. Kafka, known for handling high-throughput data streams, provides the backbone for real-time data ingestion and processing. However, Kafka's architecture, while robust, often requires additional components for data transformation and processing.
Enter Redpanda, a modern implementation of the Kafka API built in C++ to be a streamlined alternative to Kafka. It addresses some of Kafka's complexities by providing a simpler setup and operational experience for developers.
For example, Redpanda Data Transforms is powered by WebAssembly (Wasm) and allows in-place data processing. This means data can be cleaned, transformed, and prepared for machine learning models directly within the Redpanda broker, eliminating additional data-processing layers.
Implementing Redpanda in real-time predictive models
To illustrate Redpanda’s role in ML applications that handle high volumes of data in real time, let’s continue with our example of a food delivery service.
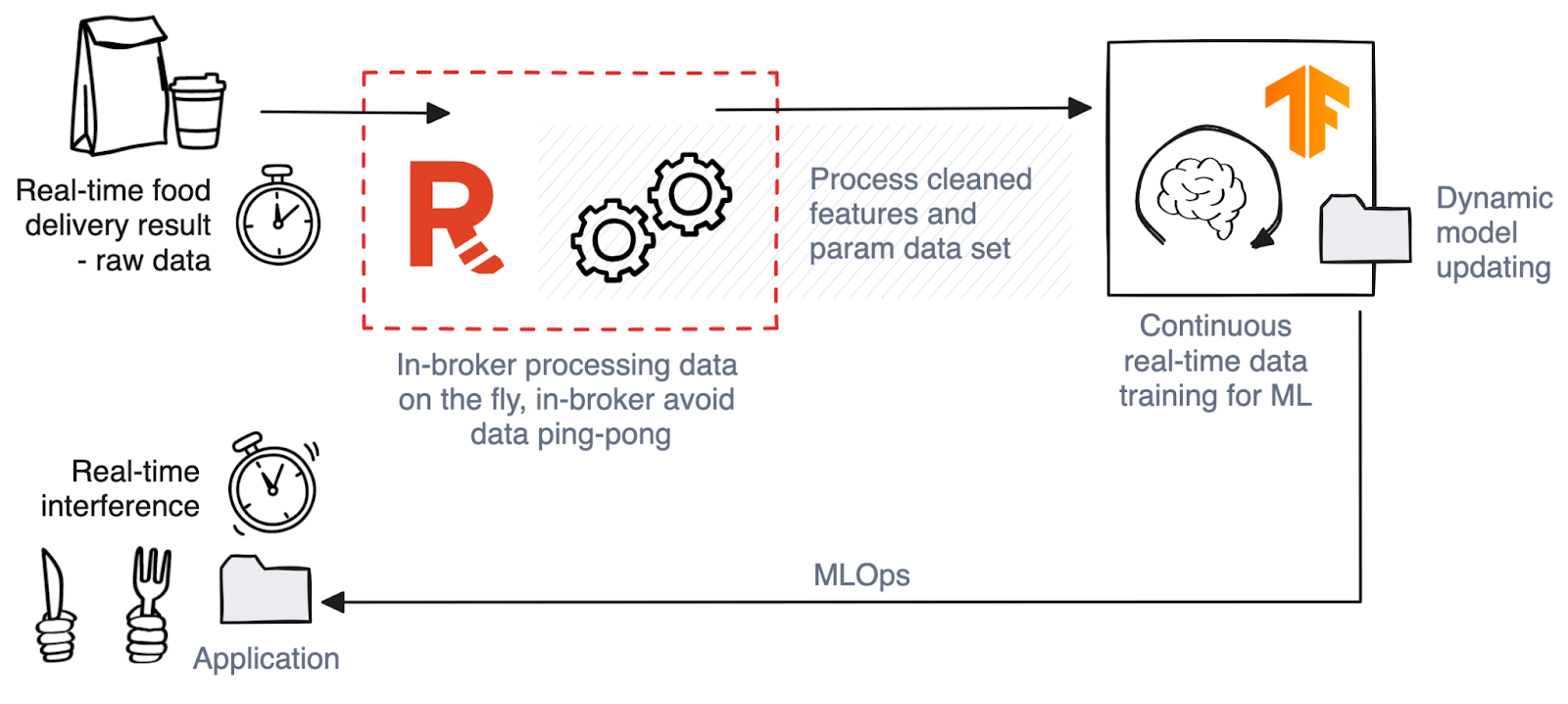
In our “food delivery time” prediction model, the architecture involves the following key components:
Data ingestion: This data comes from various sources and is often raw and unstructured, which presents the first challenge.
Instant data transformation: Once ingested, a custom-built Golang script uses Redpanda’s Wasm feature to process the data on the fly. This includes calculating the missing “distance” metric — a critical feature for this predictive model. This process exemplifies feature engineering in ML, where key data features are developed or transformed to enhance model accuracy. Redpanda’s real-time data transformation efficiency enables immediate and dynamic feature creation and modification.
ML model training with TensorFlow: The transformed data is then fed into an ML model built using TensorFlow I/O. TensorFlow I/O facilitates the consumption of real-time data streams, allowing the model to be continuously updated with fresh data. However, it’s important to note that initial training still requires a batch of historical data to establish a baseline.
Model deployment and inference: Once trained, the model is deployed for real-time inference. As new data streams in, the model dynamically adjusts its predictions, providing up-to-date delivery time estimates.
User-facing application: The final component is a user-facing application that uses the model’s predictions to provide customers and delivery partners with accurate, real-time delivery estimates.
Now that you understand the components, let’s move on to the implementation. Below is a diagram of the setup.
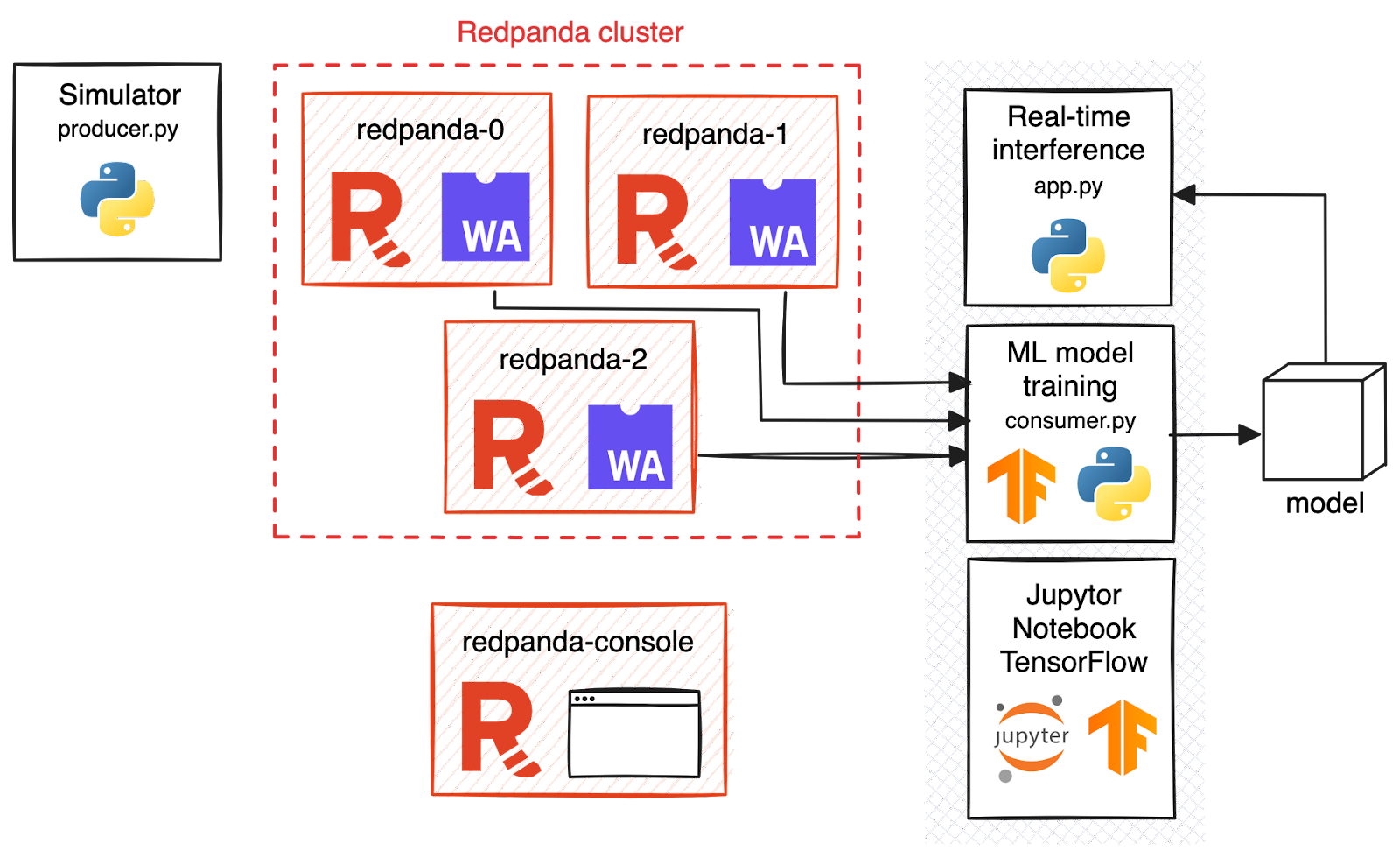
1. Simulate data streams
We use a Python script to simulate the continuous flow of data, mimicking real-world scenarios of frequent order updates.
import csv
import time
from kafka import KafkaProducer
# Define Kafka producer configuration
kafka_topic = 'raw-data' # Replace with your Kafka topic name
# Create a Kafka producer instance
producer = KafkaProducer(bootstrap_servers=['localhost:19092','localhost:29092','localhost:39092'])
# Define the CSV file path
csv_file_path = 'deliverytime.txt' # Replace with your CSV file path
# Batch size for sending messages to Kafka
batch_size = 1000
# Read the CSV file and send rows to Kafka
with open(csv_file_path, 'r') as csv_file:
csv_reader = csv.reader(csv_file)
next(csv_reader) # This skips the title row
batch = []
for row in csv_reader:
# Send each row as a message to the Kafka topic
message = ','.join(row).encode('utf-8')
producer.send(kafka_topic, value=message)
# Add the row to the batch
batch.append(message)
# Check if the batch size is reached, then send the batch and clear it
if len(batch) >= batch_size:
producer.flush()
print(f'Sent {len(batch)} rows to Redpanda.')
batch = []
# Sleep for 3 seconds
time.sleep(1)
# Send any remaining rows in the last batch
if batch:
producer.flush()
print(f'Sent {len(batch)} rows to Redpanda.')
# Close the Kafka producer
producer.close()2. Configure Redpanda
A Redpanda cluster is set up to handle the data streams. This involves configuring the number of brokers and setting up Redpanda Console for monitoring.
3. Deploy Data Transforms
The Golang script for data transformation is deployed using Redpanda's rpk transform deploy command. This ensures that the data transformation logic is applied uniformly across all broker nodes.
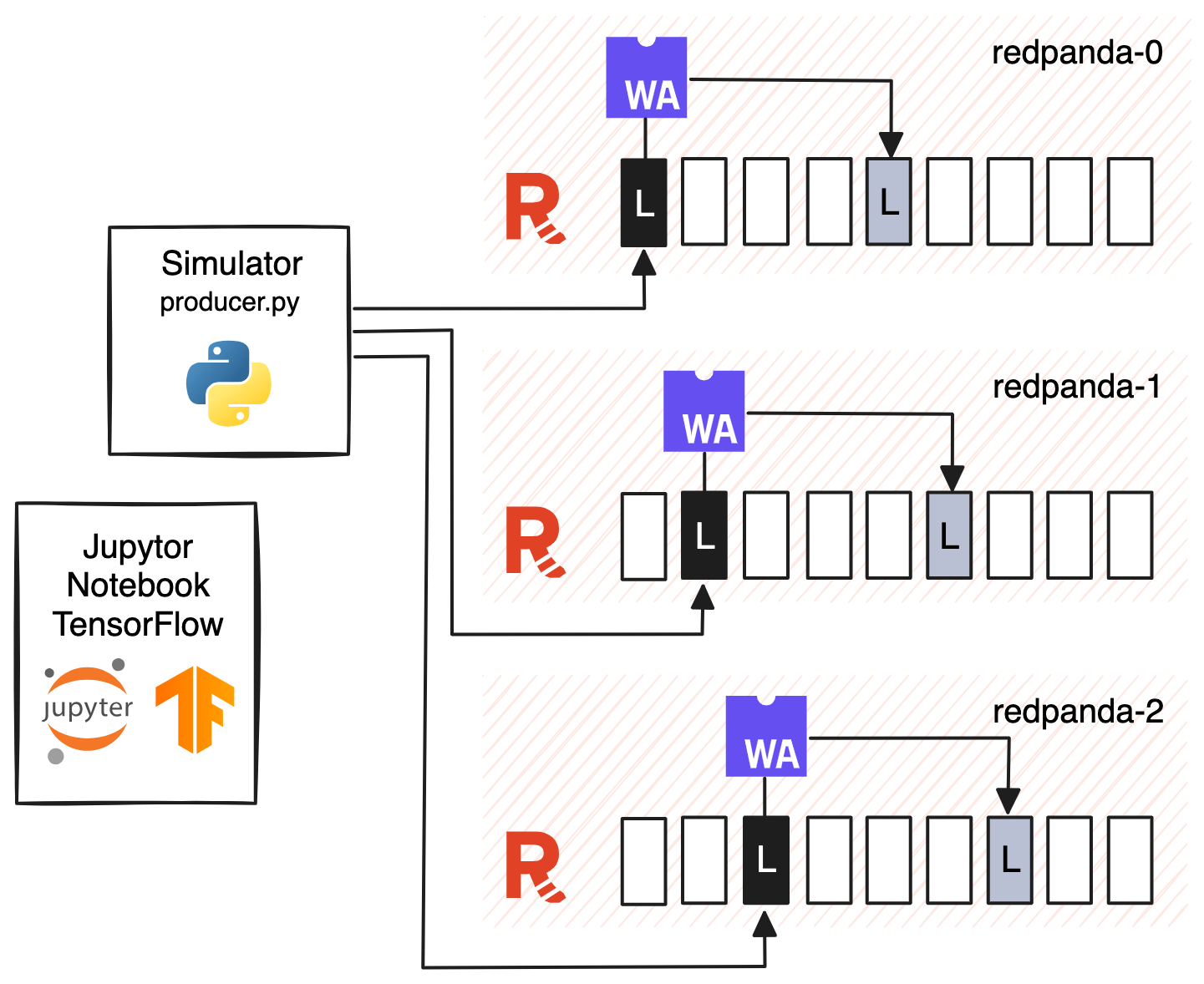
Initiate the Redpanda Data Transforms project:
rpk transform init superfast-pandapackage main
import (
"encoding/csv"
"fmt"
"github.com/redpanda-data/redpanda/src/transform-sdk/go/transform"
"math"
"strconv"
"strings"
)
// radius of the earth in kilometers
const R = 6371.0
// doTransform is where you read the record that was written, and then you can
// return new records that will be written to the output topic
func doTransform(e transform.WriteEvent) ([]transform.Record, error) {
// Skip empty records.
if e.Record().Value == nil || len(e.Record().Value) == 0 {
return []transform.Record{}, nil
}
data := string(e.Record().Value)
// Parse the CSV data
csvReader := csv.NewReader(strings.NewReader(data))
record, err := csvReader.Read()
if err != nil {
fmt.Println("Error:", err)
return nil, err
}
// Extract values from the CSV record
restaurantLatitude := parseFloat(record[4])
restaurantLongitude := parseFloat(record[5])
deliveryLocationLatitude := parseFloat(record[6])
deliveryLocationLongitude := parseFloat(record[7])
// Calculate the distance between the two points
distance := distCalculate(restaurantLatitude, restaurantLongitude, deliveryLocationLatitude, deliveryLocationLongitude)
// Create a new CSV record with the calculated distance
resultRecord := []string{
record[2], // Keep the Age
record[3], // Keep the Rating
fmt.Sprintf("%.2f", distance), // Add the calculated distance
}
// Convert the result record to a CSV string
resultCSV := strings.Join(resultRecord, ",")
// Convert the resultCSV string to []byte
resultBytes := []byte(resultCSV)
fmt.Println("resultCSV:{0} Time:{1}",resultCSV, record[10])
keyBytes := []byte(record[10])
// Create a new transform.Record
newRecord := transform.Record{
Key: keyBytes,
Value: resultBytes,
}
return []transform.Record{newRecord}, nil
}
// parseFloat parses a float64 from a string and handles errors
func parseFloat(s string) float64 {
val, err := strconv.ParseFloat(s, 64)
if err != nil {
return 0.0
}
return val
}
// Function to convert degrees to radians
func degToRad(degrees float64) float64 {
return degrees * (math.Pi / 180)
}
// Function to calculate the distance between two points using the haversine formula
func distCalculate(lat1, lon1, lat2, lon2 float64) float64 {
dLat := degToRad(lat2 - lat1)
dLon := degToRad(lon2 - lon1)
a := math.Sin(dLat/2)*math.Sin(dLat/2) + math.Cos(degToRad(lat1))*math.Cos(degToRad(lat2))*math.Sin(dLon/2)*math.Sin(dLon/2)
c := 2 * math.Atan2(math.Sqrt(a), math.Sqrt(1-a))
return R * c
}
func main() {
transform.OnRecordWritten(doTransform)
}
Build the transform into a WebAssembly (Wasm) module and deploy it to the Redpanda cluster for execution:
rpk transform buildDeploy the module to the Redpanda cluster. Redpanda ensures that the deployed module is distributed across all brokers in the cluster. This distribution is vital for load balancing and fault tolerance. Regardless of which broker is managing a particular partition or topic, the transform logic will be available to process the data to reduce latency and increase efficiency, since there's no need to move data across the network for processing.
rpk transform deploy --input-topic=raw-data --output-topic=model-data4. Train the TensorFlow model
The TensorFlow IO model is trained using both historical batch data and real-time data streams. This hybrid approach ensures the model benefits from the depth of historical data while staying agile with real-time updates.
To stream data directly from Redpanda topics into a TensorFlow data set, configure the data set to ingest data from the “model data” topic on a Redpanda cluster. The main processing loop handles data in batches: It accumulates messages, and then shuffles and decodes them before using them for training. Subsequently, the model is trained for one epoch with each batch and then saved and exported.
online_train_ds = tfio.experimental.streaming.KafkaBatchIODataset(
topics=["model-data"],
group_id="testzo",
servers="redpanda-0:9092,redpanda-1:9092,redpanda-2:9092",
stream_timeout=10000,
configuration=[
"session.timeout.ms=7000",
"max.poll.interval.ms=8000",
"auto.offset.reset=earliest"
],
)
def decode_kafka_online_item(raw_message, raw_key):
message = tf.io.decode_csv(raw_message, [[0.0] for i in range(3)])
key = tf.strings.to_number(raw_key)
return (message, key)
batch_size = 20
for single_ds in online_train_ds:
if len(single_ds) >= batch_size:
single_ds = single_ds.shuffle(buffer_size=batch_size)
single_ds = single_ds.map(decode_kafka_online_item)
single_ds = single_ds.batch(batch_size)
model.fit(single_ds, epochs=1)
tf.keras.models.save_model(model, "./time_prediction_model")
else:
print("Not enough data in the dataset. Skipping model fitting.")
The Redpanda advantage for your future applications
Integrating Redpanda in predictive modeling has several advantages:
Reduced latency: By processing data in real time, the latency between data collection and insight generation is significantly reduced.
Dynamic model updates: The continuous data flow allows the model to adapt and improve over time, leading to more accurate predictions.
Streamlined architecture: Performing data transformations within the broker reduces the need for additional data-processing layers, simplifying the overall architecture.
This approach, while demonstrated through the example of food delivery time prediction, has far-reaching implications. It can be applied to various sectors where real-time data analysis is crucial, such as financial markets, healthcare monitoring, and smart city management.
In conclusion, Redpanda is not just transforming how we handle data — it's reshaping the future of real-time ML applications. As we continue to explore and innovate, the possibilities are as vast and exciting as the data streams we seek to harness.
To start making accurate predictions on the fly for your ML apps, try Redpanda for free! If you have questions, introduce yourself in the Redpanda Community on Slack and chat with our engineers.
Originally published on The New Stack

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



