
Introduction
Real-time analytics and streaming data infrastructure are transforming the digital business landscape. But these “real-time superpowers” have been too expensive and complicated to develop for most enterprises.(1)(2)
In this blog, we will demonstrate how Timeplus and Redpanda enable a streaming-first approach to help solve many of developers core issues they face deploying real-time analytics capabilities. Specifically, Redpanda can provide a fast, scalable, reliable, and simple streaming platform to collect and manage streaming data. Timeplus can provide a fast, powerful and intuitive streaming analytics platform to turn streaming data into real-time actions.
What is Timeplus?
Timeplus is a purpose-built streaming analytics platform that solves enterprises' need for easy-to-implement real-time analytics. Timeplus provides a dynamic schema for real-time analytics, bringing flexibility to data querying and processing. This empowers enterprises to extract substantial value from data before it goes obsolete. Timeplus enables users to make real-time analytics:
Fast: Timeplus can achieve 4 millisecond end-to-end latency, and 10 million + EPS benchmark even in a single commodity machine.
Powerful: Users can quickly analyze real-time streaming data, while simultaneously connecting to historical data assets, all from one SQL query.
Intuitive: Users get speed, ease-of-use, and advanced analytics functions, both in the cloud or at the edge, and can quickly act on data simultaneously as it arrives.
Streaming analytics with Redpanda and Timeplus
Redpanda is a developer-friendly streaming data platform that combines operational simplicity, speed and reliability within unified access to real-time and historical data. Thanks to its Apache Kafka® API-compatibility, Redpanda works seamlessly with Timeplus to provide a platform to quickly turn streaming data into real-time actionable insights. Specifically,
-
Redpanda can act as upstream source to Timeplus, responsible for central streaming data hub to manage all streaming data
-
Redpanda can act as downstream sink, responsible for another data hub to manage all streaming analytic results
-
Timeplus can also directly query the topics in Redpanda as the raw streaming data store
Pairing Redpanda with Timeplus is easy! Timeplus can be configured to use Redpanda with a single command.
CREATE EXTERNAL STREAM car_demo (src String) SETTINGS type='Redpanda', brokers='redpanda:9099', topic='car_live_data'
Achieving low latency streaming analytics
Apache Kafka is a popular streaming platform and using Apache Kafka as a platform to ingest upstream data or deliver data downstream, seems like an easy decision to make. To help us better identify the more performant choice for developers, the Timeplus team ran a test to measure the end-to-end analytics latency and throughput on top of Apache Kafka and Redpanda.
Test deployment
Timeplus dataloader is the performance test tool we used to make such a performance test.
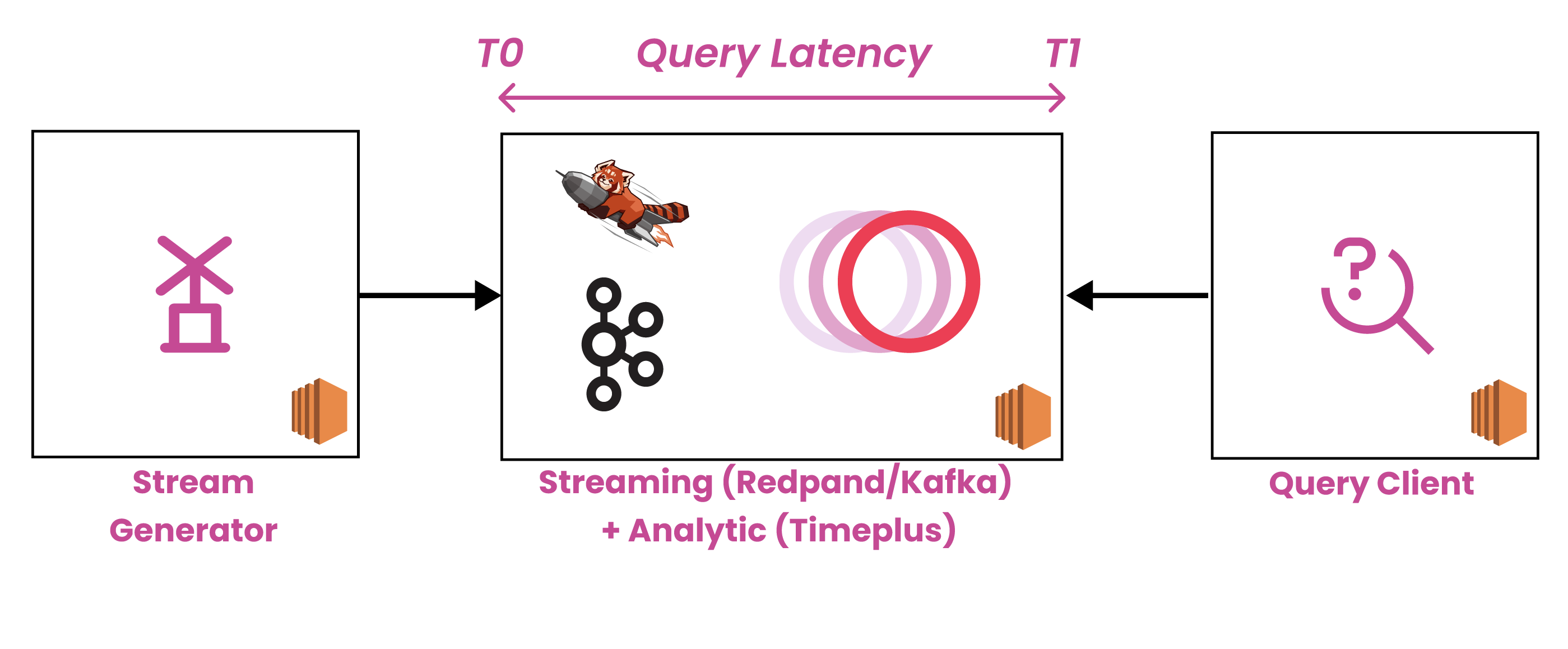
Above diagram shows the test deployment:
- A data generator is running on a separate machine to generate streaming data. The data schema is as following:
CREATE STREAM device_utils ( `device` String, `region` String, `city` String, `version` String, `lon` Float, `lat` Float, `battery` Float, `humidity` Int, `temperature` Int, `hydraulic_pressure` Float, `atmospheric_pressure` Float, `timestamp` DateTime, )
- Streaming data is sent to Apache Kafka or Redpanda, which simulates the real case where the user needs an event hub to store real-time streaming data. Timeplus subscribes to the streaming data from Apache Kafka or Redpanda, and runs the queries. Redpanda/ Apache Kafka and Timeplus are deployed into one dedicated machine to simplify deployment.
- One dedicated machine is used to run the query client
Measurements
The key test objective is to measure end-to-end query event latency, which is defined as t1-t0 (refer to the deployment diagram), where t0 is the time when the streaming event enters Redpanda or Kafka, and t1 is the time when Timeplus emits the query result. Timeplus has an internal metric service that stores all t0/t1 during the test and provides the final statistical result. Latency is an important metric to evaluate a real-time system, it shows how fast the newly generated data gets processed by the query engine instead of how fast the query is itself. It means when a user gets an analysis result, this analysis is based on the most recent data.
The query statement is a live event query with the filtering condition like this:
SELECT * from device_utils WHERE temperature > 30
Configuration
Here is the hardware configuration of these test machines:
| Deploy Type | EC2 Type | CPU | Memory |
|---|---|---|---|
| Stream Generator | C5a.12xlarge | 48 vCPU | 96GB |
| Stream + Analytic | C5a.12xlarge 3000 IOPS | 48 vCPU | 96GB |
| Query Client | T3.2xlarge | 8 vCPU | 32GB |
The software versions in this test are:
-
Redpanda: v21.11.9
-
Apache Kafka: 3.1.0-8
-
Timeplus Cloud: prestage-2022-03-10T13-00-52Z
Redpanda vs Apache Kafka performance comparison
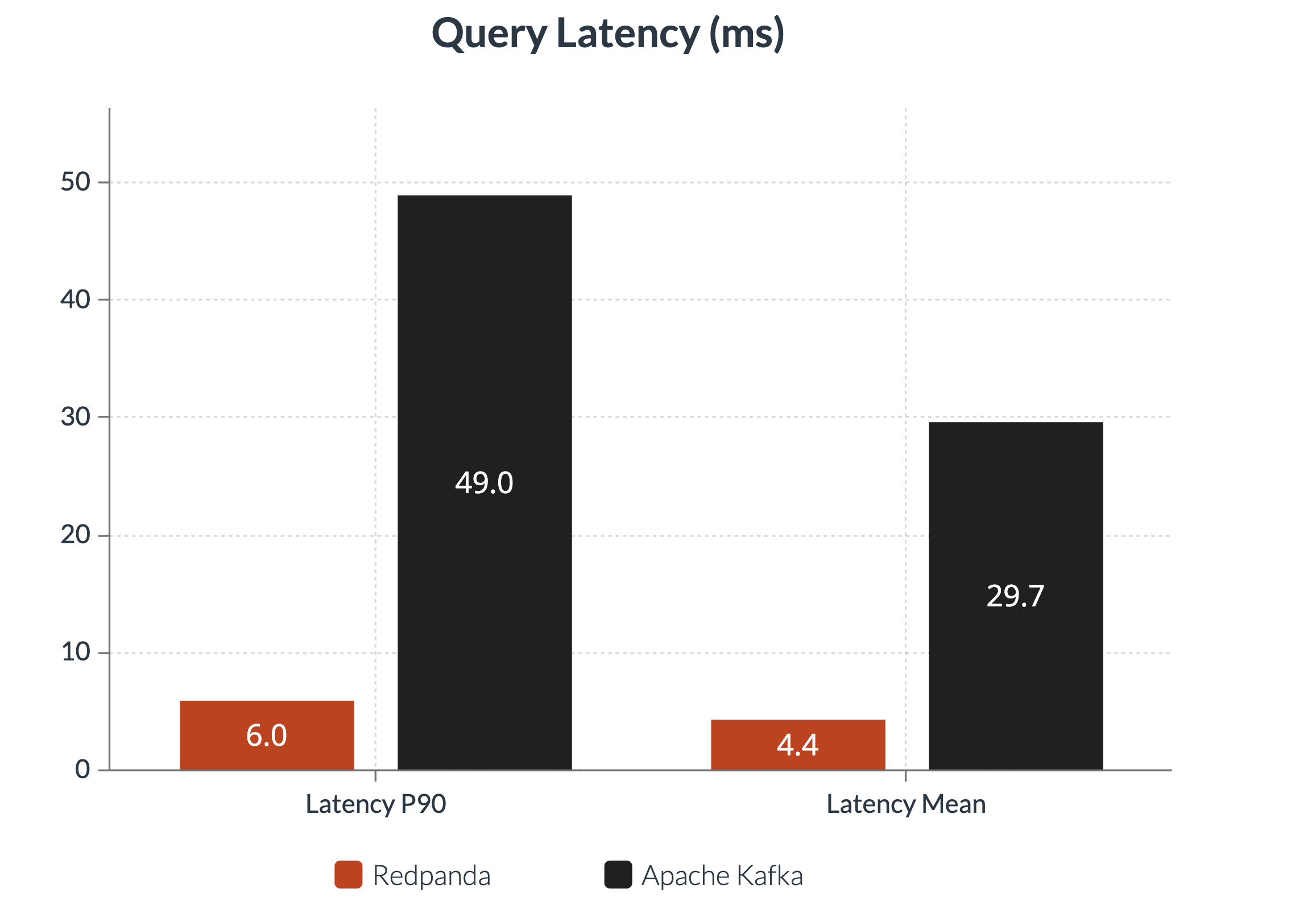
The following chart shows the output of our tests for query latency.
The test result shows that Redpanda + Timeplus achieves 6ms end-to-end query latency (P90) with 2.4 million EPS, which is 8 times faster than Apache Kafka + Timeplus combination.
We also note that Redpanda performs even better when handling large batches of data. When increasing the data batch in the test, with over 3 million EPS, Apache Kafka has increasing back pressure, the latency observed is increasing fast, which means the consumption is not fast enough compared to data generation, while Redpanda continues to work well in the same conditions. (We believe that the whole Apache Kafka deployment was unstable in this situation and so we did not record the latency result.) Below are 6 testing throughput scenarios and testing results.
| Throughput (million eps) | T+ RP: query latency (ms) - P90 | T+ RP: query latency (ms) - Mean | T+ Kafka: query latency (ms) - P90 | T+ Kafka: query latency (ms) - Mean |
|---|---|---|---|---|
| 2.43 | 6 | 4.39 | 49 | 29.7 |
| 3.37 | 8 | 5.21 | / | / |
| 3.99 | 8 | 5.00 | / | / |
| 4.45 | 8 | 5.21 | / | / |
| 4.84 | 11 | 6.39 | / | / |
| 5.03 | 12 | 7.06 | / | / |
Building applications with Timeplus and Redpanda
Below is a short video, which demonstrates how easily and powerfully Redpanda and Timeplus can be combined to analyze real-time streaming data.
Check out this short video demonstrating how easily and powerfully Redpanda and Timeplus can be combined to analyze data in real-time. The demo is a car-sharing scenario. For more details, please see the use cases.
In this demo, the topic car_live_data in Redpanda is a JSON stream, which contains the live status of each car including car id, speed, longitude, latitude, etc.
Here is a sample of the raw stream event:
{ "cid": "c00009", "gas_percent": 70.08985916343958, "in_use": true, "latitude": -19.121572876441853, "locked": false, "longitude": -0.956986111935774, "speed_kmh": 79, "time": "2022-03-17 05:09:36.905", "total_km": 96.77250639410936 }
There are two parts of this demo, in the first part, Timeplus ingests data from Redpanda, conducts data analysis and then delivers the analysis results to Redpanda. In the second part, Timeplus directly analyzes raw streaming data in the Redpanda topics without persisting them.
Part 1: Persist data in Timeplus
Timeplus ingests the streaming data from Redpanda as upstream source, makes a powerful streaming query and sends the results to Redpanda as downstream sink:
-
Creating an upstream source and collecting streaming data from Redpanda to Timeplus instantly
-
Using a powerful streaming SQL query in Timeplus to make real-time analytics easy
-
Creating a downstream sink and sending the streaming analytic result to Redpanda
In this scenario, a tumble window base query is used to analyze the average gas percentage and average speed for each car in a 10 second window.
SELECT window_start,cid, avg(gas_percent) AS avg_gas_percent, avg(speed_kmh) AS avg_speed FROM tumble(car_live_data, 10s) GROUP BY window_start,cid
Part 2 : Don’t persist data in Timeplus
The second part of the demo shows that Timeplus can also support a powerful federation search on top of Redpanda without any persistence. Furthermore the data schema can be dynamically built via a streaming view with schema extraction from the raw payload in Redpanda.
In this scenario, we first use following query to create an external stream:
CREATE EXTERNAL STREAM car_demo (src String) SETTINGS type='Redpanda', brokers='redpanda:9099', topic='car_live_data'
And then, creating a view to extract car id and speed from the raw json payload in the redpanda topic.
CREATE VIEW car_demo_view AS SELECT json_extract_string(src, 'cid') AS cid , json_extract_float (src, 'speed_kmh') AS speed FROM car_demo
Conclusion
Redpanda and Timeplus work seamlessly and demonstrate an end-to-end latency in single digit milliseconds that is up to 8 times faster in our testing scenarios. Together, the combination can unlock new use cases in manufacturing (IIOT), financial services, observability, and e-commerce to deliver faster, more powerful, and more cost-effective real-time capabilities.
To get started, check out Timeplus, or join Redpanda's Slack community to ask questions about integrating Redpanda with Timeplus or any other ecosystem tool. The era of real-time platforms is now!

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



