How Redpanda makes use of code generation to improve system reliability.
In this post I am going to explain how code generation and type safety are a couple of the important tools that we use at Redpanda to improve the reliability of the software we write. Specifically, I'll be discussing Redpanda, a drop-in Kafka replacement for mission critical workloads. If you're new around here, check out our recent video discussing the technical architecture of Redpanda.
It has been amazing to see Redpanda grow and change over the last 16 months that I've been here, but one thing that hasn't changed is our product focus of being a drop-in Kafka replacement for mission critical workloads. This goal drives much of what we choose to work on, and from an engineering perspective, it has very real-world implications. For instance, when we talk being a drop-in replacement, what we mean is that we maintain compatibility with all existing Kafka clients: if your favorite client connects to Kafka but fails to communicate with Redpanda, that is handled by our engineering team as a critical software bug.
And what about the more amorphous goal of being mission critical? While the phrase describes a wide range of production use cases, they all tend to have in common the engineering requirements of performance and correctness. But as we'll see, these high-level goals---compatibility, performance, and correctness---can often be at odds with one another. Part historical code review, part technology evangelism, in the remainder of this post we'll take a short look at how Redpanda uses code generation to automatically construct detailed, low-level network protocol parsers based on existing specifications, freeing engineers to focus on performance optimizations.
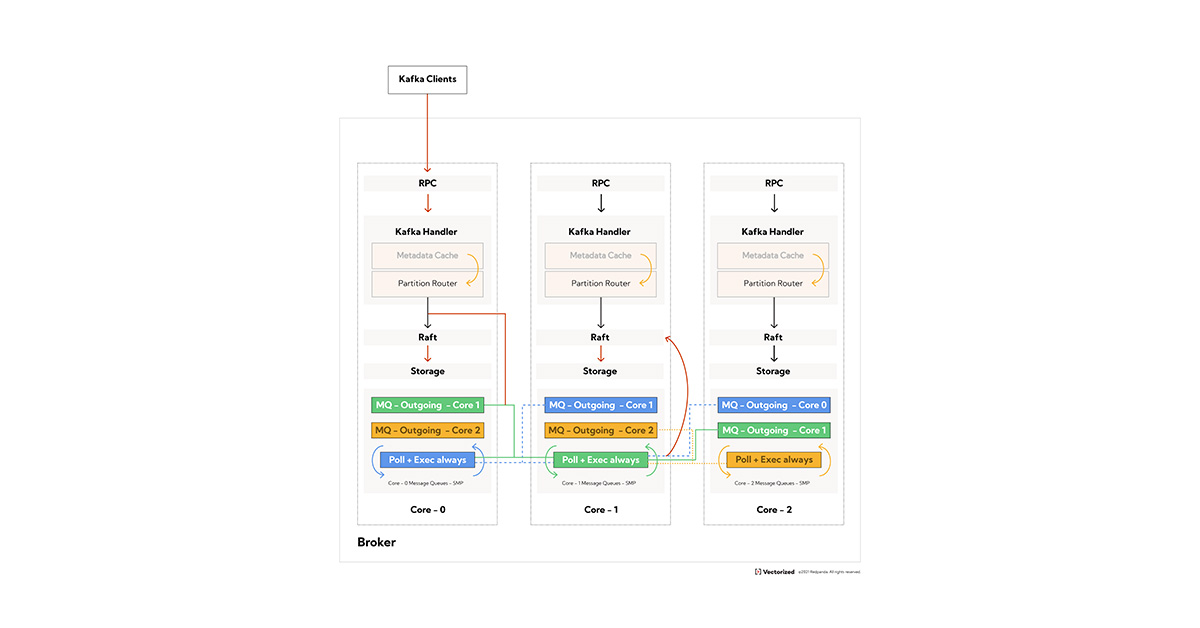
Redpanda request handling
While the whole of Redpanda is complex, at a high level it consists of a Kafka wire protocol parser that translates requests from Kafka clients onto a custom storage engine. This Kafka compatibility layer is what every request flows through, so it needs to be fast and it needs to be complete.

Early on in the development of Redpanda, we focused heavily on understanding
how to extract the most performance out of the hardware, which
often meant experimentation with low-level design patterns and system features.
But because we were simultaneously learning about the complexities of the Kafka
wire protocol and behavioral differences between existing Kafka clients, the
code we wrote was often ad hoc, as we discovered what worked well for us while
meeting our target performance requirements. Here is a snippet of old code
used to deserialize a find coordinator request from a Kafka client. First, a
signed short is read off the wire, followed by a string representing a key.
Finally, if the version is sufficient, the key type is read.
void find_coordinator_request::decode(request_context& ctx) { const int16_t version = ctx.header().version; key = ctx.reader().read_string(); if (version >= 1) { key_type = coordinator_type(ctx.reader().read_int8()); } }
To be honest, if there were only a few deserialization functions like this that needed to be written in order to support the Kafka protocol, then I wouldn't be writing this post. We'd code them by hand, audit the implementation, subject them to a battery of tests and fuzzing, and call it a day. But the Kafka protocol is quite large, consisting of 50 distinct endpoints at the time of writing.
While it is arguable that 50 endpoints is still manageable, overtime the protocol has evolved and expanded to cover multiple versions of each endpoint. For example, the fetch request that clients use to read records from a broker is today defined across 12 versions. Since a primary goal of Redpanda is to support unmodified clients, the system needs to be able to support the full spectrum of possible messages types and versions.
This unfortunately has a direct result on the size and complexity of the
implementation of the Kafka compatibility layer in Redpanda. Here is a snippet
for a hand coded decoder for the fetch request type. There is a lot happening
here in support of reading and decoding requests, from handling endian conversions to
interacting with low-level network buffers, but the take away is that this code can
become fragile as a protocol morphs over time.
void fetch_request::decode(request_context& ctx) { auto& reader = ctx.reader(); auto version = ctx.header().version; replica_id = model::node_id(reader.read_int32()); max_wait_time = std::chrono::milliseconds(reader.read_int32()); min_bytes = reader.read_int32(); if (version >= api_version(3)) { max_bytes = reader.read_int32(); } if (version >= api_version(4)) { isolation_level = reader.read_int8(); } if (version >= api_version(7)) { session_id = reader.read_int32(); session_epoch = reader.read_int32(); } topics = reader.read_array([version](request_reader& reader) { return topic{ .name = model::topic(reader.read_string()), .partitions = reader.read_array([version](request_reader& reader) { partition p; p.id = model::partition_id(reader.read_int32()); if (version >= api_version(9)) { p.current_leader_epoch = reader.read_int32(); } p.fetch_offset = model::offset(reader.read_int64()); if (version >= api_version(5)) { p.log_start_offset = model::offset(reader.read_int64()); } p.partition_max_bytes = reader.read_int32(); return p; }), }; }); if (version >= api_version(7)) { forgotten_topics = reader.read_array([](request_reader& reader) { return forgotten_topic{ .name = model::topic(reader.read_string()), .partitions = reader.read_array( [](request_reader& reader) { return reader.read_int32(); }), }; }); } }
Currently our support is approaching a couple hundred endpoint-version pairings. This means that for each endpoint we need to build both a decoder for requests and an encoder for responses , each of which must handle a range of versions. In practice, this is all doubled because we also maintain a high performance C++ client in addition to the broker.
While we have spent a lot of time optimizing code like that shown above, this type of parsing is detailed, prone to human error, and rather difficult to test properly. And you can believe me---I spent more than a few nights looking for misplaced bytes after listening to existing Kafka clients complain about corrupt batches.
Code generation
Luckily, this type of code is highly mechanical and repetitive. And as it turns
out, a precise definition in machine readable format has been published that
describes the Kafka wire protocol. So let's go ahead and code-gen these
routines, and never look back. Here is the published
schema
for the offset fetch request type. This small snippet of JSON is enough to generate
a full decoder and encoder.
{ "apiKey": 9, "type": "request", "name": "OffsetFetchRequest", "validVersions": "0-6", "fields": [ { "name": "GroupId", "type": "string", "versions": "0+", "entityType": "groupId", "about": "The group to fetch offsets for." }, { "name": "Topics", "type": "[]OffsetFetchRequestTopic", "versions": "0+", "nullableVersions": "2+", "about": "Each topic we would like to fetch offsets for, or null to fetch offsets for all topics.", "fields": [ { "name": "Name", "type": "string", "versions": "0+", "entityType": "topicName", "about": "The topic name."}, { "name": "PartitionIndexes", "type": "[]int32", "versions": "0+", "about": "The partition indexes we would like to fetch offsets for." } ]} ] }
The code generation tool we wrote takes as input these schema specification files and produces optimized encoders and decoders that are then compiled directly into the rest of the project.

We also use code generation as an opportunity to generate supporting functionality like printable forms of the request types that are often forgotten and not updated as data structures change.
std::ostream& operator<<(std::ostream& o, const offset_fetch_request_topic& v) { fmt::print( o, "{{name={} partition_indexes={}}}", v.name, v.partition_indexes); return o; }
Here is the generated header file that is produced. I've omitted the code generated for the actual encoder and decoder, because it is effectively identical to the hand coded version shown above. The difference is that human error has largely been eliminated from the process of writing this code.
/* * The offset_fetch_request_topic message. * * name: The topic name. Supported versions: [0, +inf) * partition_indexes: The partition indexes we would like to fetch offsets for. * Supported versions: [0, +inf) */ struct offset_fetch_request_topic { model::topic name{}; std::vector<model::partition_id> partition_indexes{}; friend std::ostream& operator<<(std::ostream&, const offset_fetch_request_topic&); }; /* * The offset_fetch_request_data message. * * group_id: The group to fetch offsets for. Supported versions: [0, +inf) * topics: Each topic we would like to fetch offsets for, or null to fetch * offsets for all topics. Supported versions: [0, +inf) */ struct offset_fetch_request_data { kafka::group_id group_id{}; std::optional<std::vector<offset_fetch_request_topic>> topics{}; void encode(response_writer&, api_version); void decode(request_reader&, api_version); friend std::ostream& operator<<(std::ostream&, const offset_fetch_request_data&); };
While code generation eliminates a large category of bugs that can be difficult to track down, the results of parsing data off the wire must still be integrated into the rest of the system, and that brings with it a new set of reliability challenges.
Type safety
Consider the following line of code, which reads the session epoch off the wire in preparation of handling a fetch request. This is nothing more than wire protocol decoding wrapped up in a nice interface, which hides complexities like endian decoding and interacting with network buffers. In any case, the result is a bare integer with a name.
int32_t session_epoch = reader.read_int32();
The problems start to occur when a downstream callee receives this int32_t
session epoch parameter because C++ does virtually nothing to ensure that the
semantically correct parameters are being passed at a call site like this:
... handle_session(session_epoch, session_id, ...); ...
Taking a closer look at the fetch request, the decoding process produces many
such int32_t values. Swapping the parameters at a call site or changing the
definition could have disastrous results, and the compiler will happily accept
your mistake. This is another instance where human error is easily
avoidable---in this case by using the type system.
Once you start digging into the Redpanda source you'll discover that we make prolific use of a strong type pattern in C++ to address this category of bugs. For instance in Redpanda topic names and partition ids are defined by the types:
namespace model { ... using topic = named_type<ss::sstring, struct model_topic_type>; using partition_id = named_type<int32_t, struct model_partition_id_type>; ... }
The zero-cost abstraction of named_type let's us write function definitions like this:
auto read(topic t, partition p);
which will not even compile if a bare string or integer (or other strong types
with the same base type) are passed to read accidentally. It's difficult to
measure how much more reliable this type of utility makes software, but if you
have ever had to track down issues related to such a mistake, then you may
appreciate how much more confidence this can give you in your implementation
and on your ability to focus on other low-level aspects of your system like
performance optimizations.
Type safety and code generation
When developing our code generator we wanted to add native support for our extensive use of strong types. After all, the Kafka protocol is largely defined in terms of primitive types which we've seen can lead to some easily avoidable problems.
To do this, we developed several methods for expressing type overlays. Here
below is one such overlay that adds our strong types for various parts of the
describe groups response type. The overrides are defined as terminal values
on a given path within the unmodified Kafka JSON schema.
"DescribeGroupsResponseData": { "Groups": { "ProtocolType": ("kafka::protocol_type", "string"), "Members": { "MemberId": ("kafka::member_id", "string"), "GroupInstanceId": ("kafka::group_instance_id", "string"), }, }, },
When combined, code generation and strong types provide us the confidence we need to explore low-level performance optimizations without worrying about many common types of errors that may pop up as a result of hand optimization.
What's next?
Watch this space for lots more content on the technical details of Redpanda, including additional coverage of code generation, as well fuzzing, performance optimization, and other techniques for building reliable software in C++.

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



