Going beyond Jepsen and our journey to a scalable, linearizable Raft implementation.

Redpanda is a Kafka replacement for mission critical systems. We designed the system to be safe, but the vagaries of the real world will bring every system to its knees if you let it. Typos, errors, misunderstandings, and vagueness is what makes engineering human, and vulnerable. Ultimately, the difference between a specification and a working system is rigorous testing - the empirical proof of correctness. Without it, the implementation of these algorithms is simply aspirational.
Testing is necessary and always has been. Half a century ago, F. Brooks wrote in his legendary "The Mythical Man-Month" book:
The project manager's best friend is his daily adversary, the independent product-testing organization. This group checks machines and programs against specifications and serves as a devil's advocate, pinpointing every conceivable defect and discrepancy. Every development organization needs such an independent technical auditing group to keep it honest.

Modern CPUs and the rise of distributed systems has only increased the probability of contemporary systems to misbehave. For example:
- threads running on different cores have different world views (cache coherence problems)
- nodes have different local time (clock synchronization issues)
- a distributed system may be partially available (some nodes are down while others are up)
- a system may be unintentionally split into several systems (network partitioning)
In this post, we’ll talk about how we face all of these potential issues, going beyond Jepsen (a popular consistency validation suite) to build an in-house solution to validate longer histories of operations. Let’s start from the beginning, though, with the biggest gun in our arsenal: chaos testing.
Chaos testing
Chaos testing (chaos engineering) is a variant of system testing where we validate functional requirements (e.g. a system returns correct answers) and non-functional requirements (e.g. a system is always available) in the presence of injected faults like network partitioning, process termination (kill -9) or other faults.
The first time I heard about chaos engineering was during my days at Yandex. I was a fresh graduate doing my first design review when a senior member of my team asked me what precautions I took to make sure my service survived the military exercise. It caught me off guard because I wasn't aware of any joint operations between the army and the company. My colleague noticed my confusion and explained that the "military exercise" is a codename and that since 2007, every Thursday Yandex had been shutting down one of its data centers to test the resilience of its services. It was a lesson I still remember - always design things with failure in mind - actually test it.
With time, chaos engineering was popularized by Netflix and a lot of new chaos-testing tools emerged. The most popular is Jepsen. A lot of databases and data systems including MongoDB, CockroachDB, Etcd, Cassandra and Kafka have been using it to check if consistency holds under intensive chaos testing. Most of them have found violations[1] of various levels of severity.
Under the hood, Redpanda uses consensus, the same protocol the distributed databases use, so it was a natural choice to apply the same strategy for chaos testing and developed a testing suite similar to Jepsen to test linearizability.
Linea-riza-what
Linearizability is a correctness property of multi-threaded and distributed systems. It guarantees that execution of the concurrent operations is equivalent to executing them in sequence. By definition it excludes all the anomalies associated with the concurrent execution such as lost updates or stale reads.
Linearizability is very similar to serializability (transaction processing in the database world) but a bit stronger. Unlike serializability, it has real-time restrictions. Linearizability requires an operation to take effect between its start and end time.
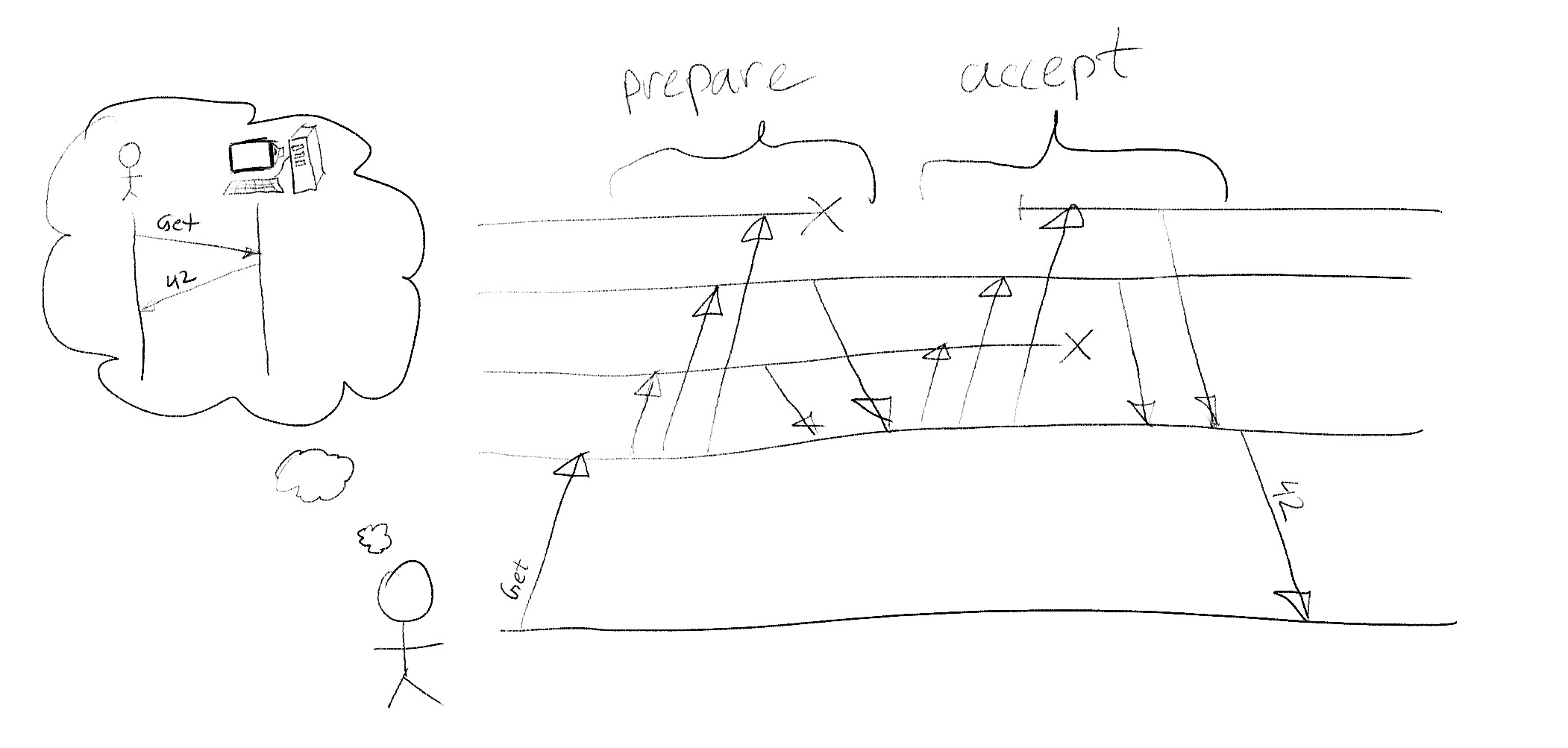
A good mental model for a linearizable system is a remote single threaded service: all operations are ordered, happen after a request starts but before it ends, and, because of the network delays the order of the requests start and end times doesn't imply the order of when they were applied.
Validation
Usually, to test linearizability one executes a set of concurrent operations, collects a history logging start time, end time, and the result of the operations and then checks if it's possible to order the operations with respect to the start and end times in a way that a sequential execution of the operations gives the same results.
In general the validation problem is NP-complete and becomes unbearably expensive once the history is long enough.
"Jepsen’s linearizability checker, Knossos, is not fast enough to reliably verify long histories". CockroachDB analysis[2]
"Because checking long histories for linearizability is expensive, we’ll break up our test into operations on different documents, and check each one independently—only working with a given document for ~60 seconds". RethinkDB analysis[3]
In a nutshell if the supported operations are add and get then checking consistency of a history with single get and multiple add all starting and ending at the same time is equivalent to the subset sum problem[4] which is known to be NP-complete.
NIH or why we developed an in-house consistency checking tool
We decided not to depend on battle-tested Jepsen or Porcupine for testing and to develop Gobekli, an in-house consistency checking tool. Why?
The existing tools are universal and testing linearizability of a system with arbitrary operations is a compute-intensive task. However if we restrict the operations to reads and conditional writes the complexity of the problem jumps into the O(n) class (where n is the length of a history). Moreover it allows to validate linearizability in a streaming fashion with constant memory consumption, meaning we can check consistency of the operations as fast as they happen and keep running tests for days or even weeks.
This idea not only unlocks the ability to test consistency during long running maintenance operations like cluster reconfiguration, repartitioning and compaction but also gives a repl-like mode to explore consistency before writing a test. We just run the validation process in the background and then manually inject faults or perform operations potentially affecting consistency. Since we check linearizability on the fly, it gives instant feedback and allows us to correlate a violation with a recently performed operation.
Testing shared memories
The idea behind Gobekli comes from the "Testing shared memories"[5] paper by Phillip B. Gibbons and Ephraim Korach. It investigates how different restrictions affect complexity of testing linearizability and sequential consistency.
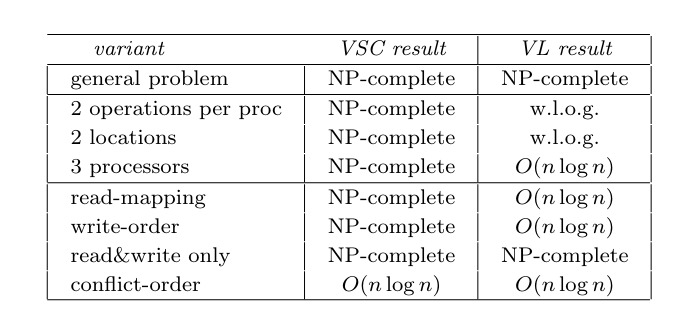
VSC stands for validation of sequential consistency and VL means validation of linearizability. Like we discussed above, the general problem is NP complete. But with read-mapping, write-order or conflict-order restrictions the problem jumps into the O(n log n) class.
We found that implementation-wise it's easier to follow the "conflict-order" path. Conflict-order restriction is a combination of read-mapping and write-order restrictions. While the authors of "Testing shared memories" describe read-mapping as:
for each read operation, it is known precisely which write was responsible for the value read
and write-order as:
for each shared-memory location, a total order on the write operations to the location is known
From a storage API perspective, this means that every write operation has a unique ID. We use that ID to map read data to an operation which wrote it. We also guarantee write-order by performing only conditional writes using previously written ID as an argument to compare-and-set.
This gives us O(n log n). The next step is to reduce it to be linear and make it online. The exact description of the algorithm is a topic for another post, but the intuition is simple.
The O(n log n) complexity comes from sorting the log by time. Once it's sorted, we use it to reconstruct a dependency graph and check if it has cycles. The latter operations have amortized linear complexity. Since we log operations as they happen, the history is already sorted. This just leaves us with amortized linear complexity, which can be optimised further into a streaming algorithm.
Rolling your own consistency validation sounds like rolling your own crypto, but validation of the consistency validation is straightforward. When it's a negative instance, you get a clarification why linearization is impossible. When it's a positive, you get a schedule of an equivalent sequential execution with a linearization point for each operation. So, in both cases you get an audit trail.
The obvious limitation of the scheme is that it can only validate conditional writes. Our belief is that safety-wise, only conditional writes are essential in distributed systems: when there is more than one client accessing the same resource, we should use locks, and locks in distributed systems require fencing[6] a.k.a. conditional writes. (Yes, it's possible to use Lamport's bakery algorithm[7] to do locking a distributed environment without CAS but it's a marginal use case there because a failure of a lock holding client stalls everybody else).
Testing Redpanda
If we oversimplify, Redpanda is a durable append-only list, but the VL problem is expressed in terms of read and conditional write API which leads us to a question: how do we marry these two things together?
At the core, Redpanda uses the Raft protocol, so the first iteration of the linearizability validation was to build a key/value storage with the right API on top of Redpanda's Raft and to validate that the foundation of Redpanda is correct.
When the linearizability tests passed, it increased confidence in our Raft implementation, but did not exclude a possibility of an error in the Kafka API compatibility layer affecting linearizability. To test this part, we built a key/value storage using Redpanda as a transaction log similar to
def read(key): offset = redpanda.append(Noop()) storage = catch_up(offset) return storage[key] def write(key, prev_id, id, value): offset = redpanda.append(Write( key = key, prev_id = prev_id, id = id, value = value )) storage = catch_up(offset) return storage[key] def catch_up(offset): storage = dict() for cmd in redpanda.read(0, offset): if cmd.is_write: if storage[cmd.key].id == cmd.prev_id: storage[cmd.key].id = cmd.id storage[cmd.key].value = cmd.value return storage
Faults
Being able to validate histories is a part of the job. Another part is to inject faults and observe how they affect consistency and other characteristics of a system. Which faults should we introduce?
There are endless things that can go wrong in real life, so to limit the search space we looked around the industry and came up with the following list of faults:
- network partitioning (with iptables)
- sudden termination of a service (kill -9)
- freezes (kill -STOP)
- disk delays (via FUSE)
- disk failures (via FUSE)
- rapid host clock jumps
Results
Long story short I wasn't able to find any consistency violations. It's awesome but a bit boring. In order to get something actionable I visualized data to see if there are availability or latency anomalies caused by fault injections.
For the start there is a baseline without injections.
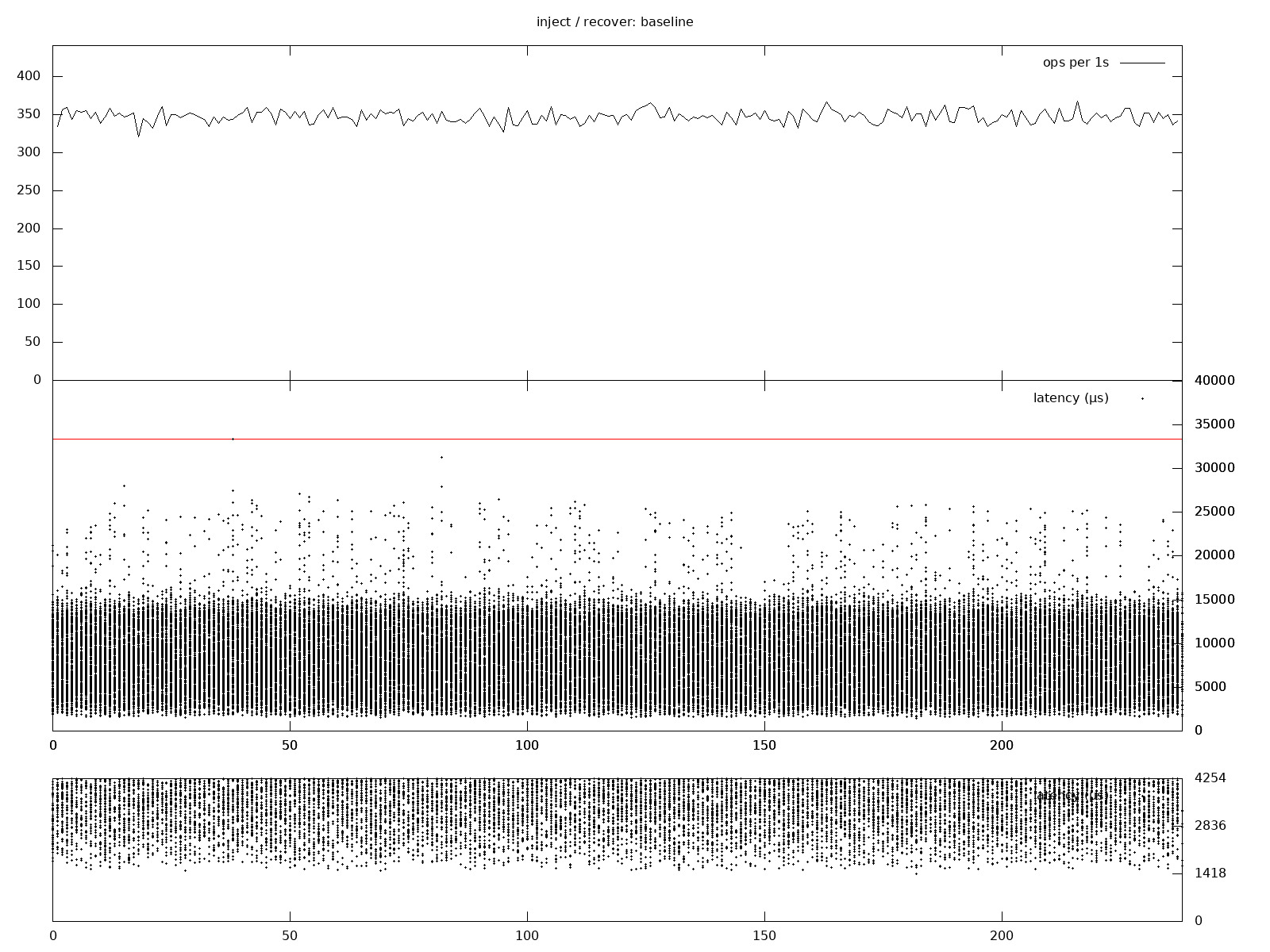
For 12 clients there are around 350 operations per second and most of the latency is distributed between 1.5 ms and 15 ms. I didn't optimize for performance, so please don't treat these numbers as the best of Redpanda. With a larger number of clients it achieves way better throughput and when tuned and not on FUSE, it yields better latency.
Now let's take a look at a case where I isolated a follower, waited a minute and rejoined it. My expectations were to observe the same kind of behaviour as the baseline.
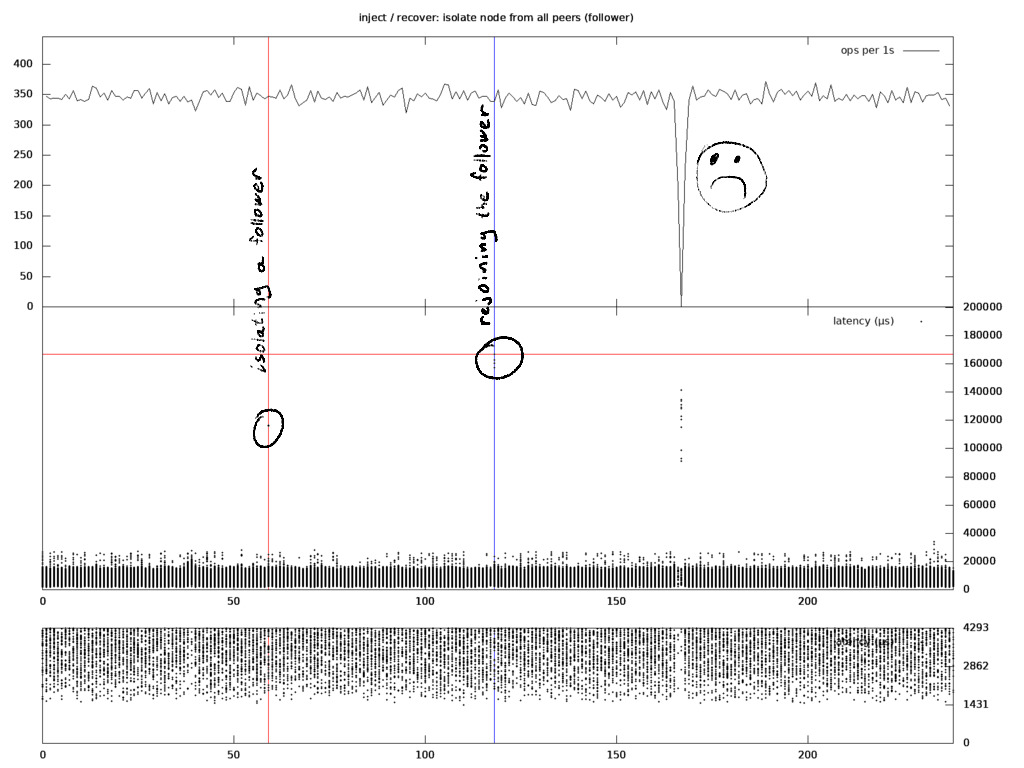
As you can see on the diagram, there are minor latency spikes up to 160 ms at the moment of fault injection / recovery, and a one-second long unavailability window happened one minute after the follower was reconnected with the peers. My colleague Michal found that the latter is an expected Raft behavior described in the Raft thesis:
One downside of Raft’s leader election algorithm is that a server that has been partitioned from the cluster is likely to cause a disruption when it regains connectivity
Luckily, for this particular issue, there’s a known solution, but testing is never done. The complexities of feature interaction, distributed systems failures, vagueness in specification and the unruly nature of the real world drove us to extend and in-house a solution for longer history evaluations - and this is just the beginning of consistency validation at Redpanda.
As a developer who has worked on on-call rotations, I know from bitter, middle-of-the-night experience that the systemic pressure of simulation testing with faults and catastrophic failures is the only way to support a mission critical system - doubly so for one that is pushing the boundaries of what is possible today.
We know how it feels to support a system with fluffy claims, without consistency testing. We waited 18 months before we released Redpanda to the public because we care about your data and understand that we have one shot to earn your trust.
We encourage you to try the product for free today and join our community slack to see what the system is capable of!
[1] Jepsen Analyses - https://jepsen.io/analyses
[2] CockroachDB analysis - https://jepsen.io/analyses/cockroachdb-beta-20160829
[3] RethinkDB analysis - https://jepsen.io/analyses/rethinkdb-2-2-3-reconfiguration
[4] Subset sum problem - https://en.wikipedia.org/wiki/Subset_sum_problem
[5] "Testing shared memories" - http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.107.3013
[6] "How to do distributed locking" - https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
[7] Lamport's bakery algorithm - https://en.wikipedia.org/wiki/Lamport%27s_bakery_algorithm

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



