Flexible write caching, role-based access control, and the GA of Data Transforms powered by WebAssembly

The 24.1 release of Redpanda's streaming engine is arriving fast and furious, adding a write caching option for even better performance. It also brings the general availability of Data Transforms to users of Redpanda Community Edition and Redpanda Enterprise. Plus, Enterprise users get simplified permissions management with Role-Based Access Control (RBAC) for all cluster resources.
Buckle up. We're going on a grand tour of what’s new in Redpanda 24.1!
Need for speed: Write caching
From the start at Redpanda, we've been committed to getting the best performance out of modern hardware while emphasizing data durability. Some workloads, however, still need to go fast but must run on a wider variety of existing hardware, or involve high volumes of ephemeral data where cost-optimization is key.
With write caching, the 24.1 release relaxes durability requirements in exchange for higher performance across a wider range of instance types and storage infrastructure. Write caching makes more efficient use of the IOPS available in storage devices, reflecting in the performance of applications that use it. Our internal benchmarks show 19% to 98% improvements in latency, though the degree of benefit will vary by workload and hardware.
You can now use Redpanda in a similar way to the default configuration of Apache Kafka — where nodes can acknowledge writes before they are flushed to disk via the Linux fsync system call — but without relying on external metadata storage. The tradeoff to this approach is that it prioritizes high performance over data safety. Previously, the only option in Redpanda was to acknowledge writes once they were fsynced on a majority of nodes after Raft replication, guaranteeing data safety and reliability.
Additional benefits from enabling write caching include:
The ability to fine-tune hardware price performance, by mixing and matching smaller instance types and higher-latency networked storage devices
Support for workloads to absorb high rates of requests per second in scenarios where producer batching is small or not possible
The flexibility to tune data safety guarantees on a per-topic basis, providing the best of both worlds to clusters running a mix of workloads
An important note on the new write caching settings:
For clusters in development mode, write caching is enabled for all topics by default
For clusters in production mode, write caching must be explicitly enabled per topic
Check out our benchmark where we demonstrate how write caching turbocharges performance by up to 90%!
RBAC puts simplified permissions in the driver's seat
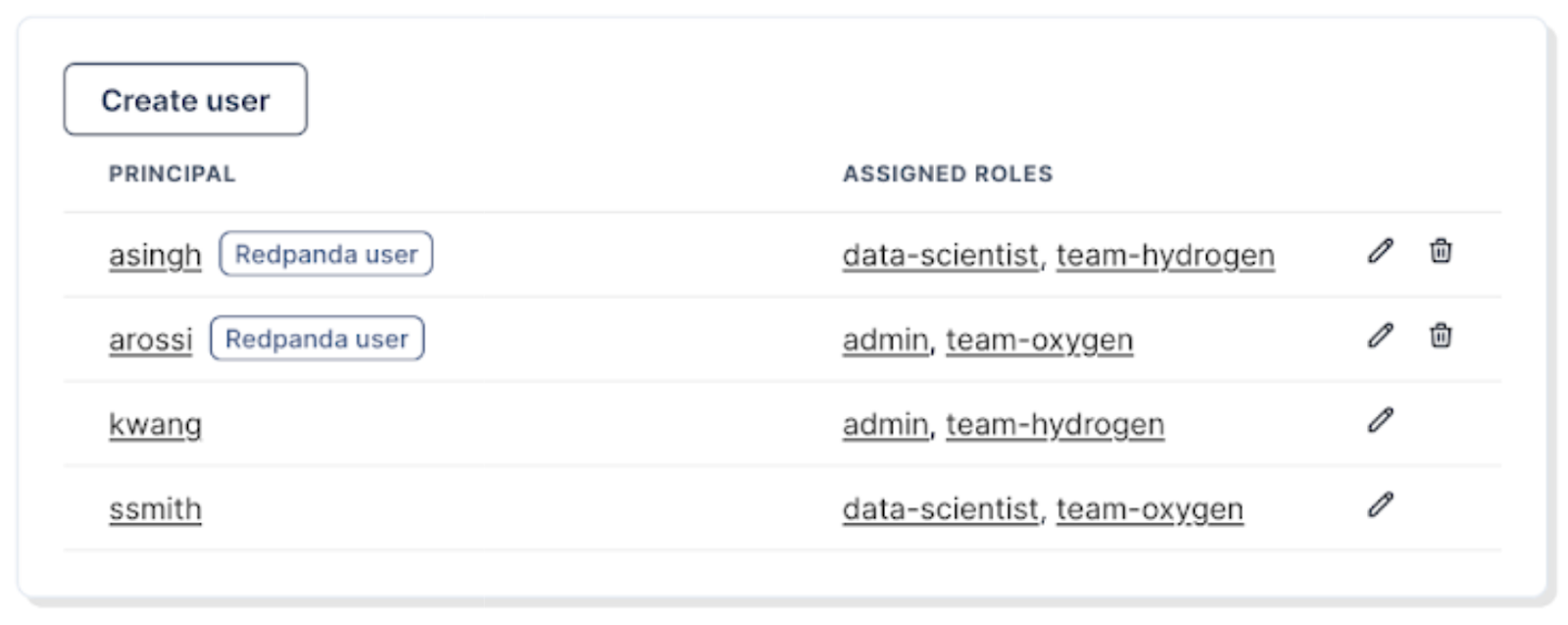
Access management in Redpanda Enterprise just got easier with the introduction of role-based access control (RBAC) — especially useful for admins managing large Redpanda deployments, working in larger organizations or in regulated industries.
RBAC provides an easy and efficient way to onboard new employees, adapt to changing usage patterns and compliance needs, and audit particular users' privileges. It allows admins to abstract multiple security policies into a minimal set of roles that mirror organizational hierarchies or specific job functions. You can then assign and modify roles for multiple users simultaneously.
Apache Kafka®, in contrast, only provides access control lists (ACLs), which define permissions on a per-user basis. Manually maintaining and verifying ACLs quickly becomes burdensome as a user base expands into the dozens and beyond.
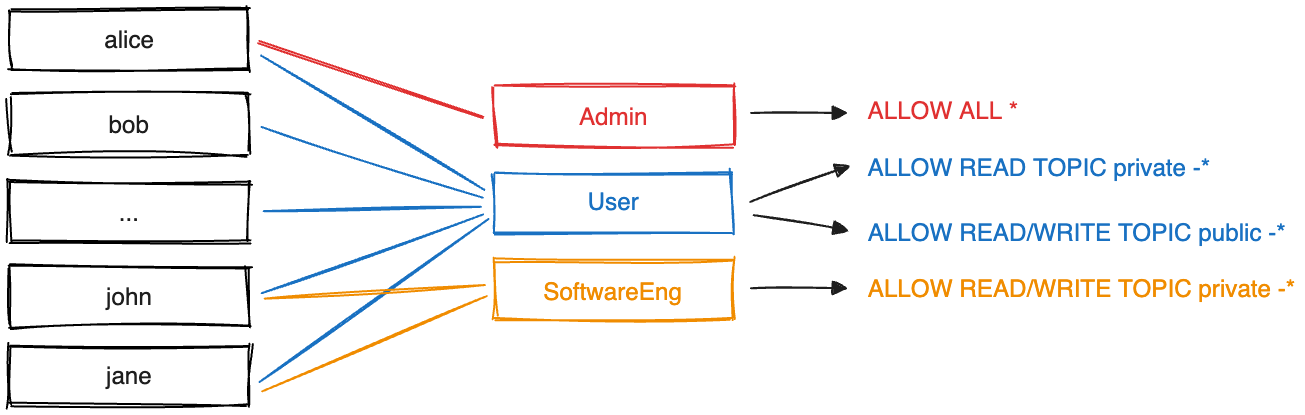
Redpanda Enterprise 24.1+ clusters now feature support for RBAC, enhancing security without sacrificing convenience or compatibility with the Kafka API. Existing ACLs for individual users will remain operational, ensuring no disruption to current configurations.
Moreover, roles created within Redpanda seamlessly translate to ACLs through the Kafka API, facilitating straightforward integration. Creating and managing roles is effortless using rpk or via the new Access Control tab in Redpanda Console.
Data Transforms shift into GA
Redpanda Data Transforms is a stateless inline data processing framework built into Redpanda's simple, single-binary deployment model. It's built on WebAssembly (Wasm), allowing developers to write arbitrary code in multiple languages, processing messages as they pass through brokers and leveraging an extremely lightweight virtual machine as the execution layer. This approach of pushing transformations into the streaming data engine pairs perfectly with Redpanda’s thread-per-core execution model, delivering game-changing cost efficiencies for running simple data processing pipelines between streams.
Redpanda Data Transforms are now generally available for all Redpanda Enterprise and Community Edition users! Since launching the public beta in 23.3, we've expanded the use cases for Data Transforms and added features to make them production-ready. New features include the ability to fan out messages to multiple topics, expanded language support, and an improved logging experience.
Rust SDK
In addition to making Data Transforms accessible to a broader set of developer communities, the lean and mean architecture of WebAssembly shines with the addition of our compute-efficient Rust language support and SDK, which complements the existing Golang support but runs even faster!
Write to multiple output topics
Developers can now apply more sophisticated logic for pre-processing data before it leaves the broker. Data Transforms now support the ability to take one input topic and create transforms that fan out writes to multiple output topics.
Using Data Transforms to write to multiple topics can simplify common streaming patterns. For example: Data Transforms can validate message payloads earlier in a pipeline, sending valid messages to an output topic and invalid messages to a dead letter queue.
This idea can be further extended, routing various message types from a busy single input topic to various downstream topics whose consumers may require only pieces of the original messages or require it encoded in a particular format. See our docs for examples and limitations.
Logs
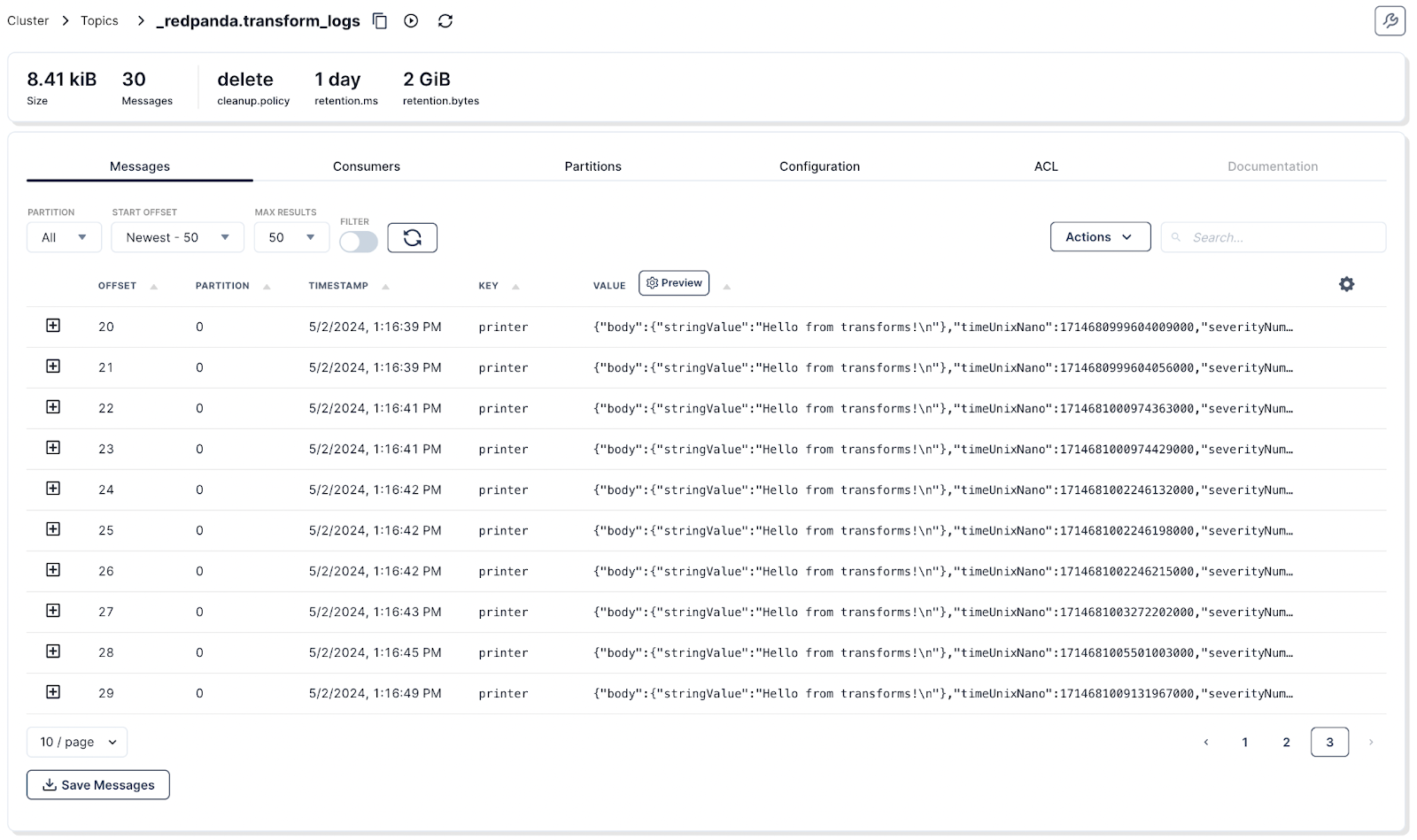
We're making Data Transforms easier to debug by writing runtime logs into an internal topic and making them easily accessible through rpk. Quickly view transform logs using the CLI via the rpk transform logs <transform_name> command, and check out usage examples here. Transform logs are also accessible in Redpanda Console by visiting your cluster's Topics section and ticking the Show internal topics checkbox to reveal _redpanda.transform_logs.
License and registration: Managed Identities for Azure
Redpanda Enterprise 24.1 adds an additional layer of security to self-hosted deployments on Microsoft Azure, while laying the foundation for future Redpanda Cloud support on Azure.
Similar to Redpanda's existing support for IAM roles for self-hosted deployments on AWS and GCP, Redpanda Enterprise now supports managed identities for Tiered Storage on Azure, providing a safer alternative to static credentials like access keys.
Managed identities allow Redpanda clusters deployed on Azure Virtual Machines (VMs) and on Azure Kubernetes Service (AKS) to access Azure Blob Storage (ABS) and other Azure services using a unique service principal, making it easier to limit Redpanda’s access to precise Azure resources, and without storing credentials in the cluster configuration.
Keep it moving: Topic-aware partition balancing
We're introducing an improved algorithm for partition placement and balancing, delivering more predictable and reliable performance. Redpanda now prioritizes balancing a topic’s partition replica count on each broker while balancing the cluster’s overall partition count. Since different topics in a cluster can have vastly different load profiles, this better distributes the workload of heavily used topics evenly across brokers.
Topic-aware partition placement and balancing are enabled by default in 24.1. All new topic additions and rebalance operations will inherit this behavior.
Ready. Set. Stream!
That wraps up our tour of Redpanda 24.1. Keep your eyes on the road ahead for an updated TCO analysis and performance benchmark featuring write caching.
Raring to go? Start fast and scale to zero with a free trial of Redpanda Serverless, or contact us to try Redpanda Enterprise. You can also grab the free Community Edition from GitHub. If you have questions about the latest updates or just want to chat with our team, join our Redpanda Community on Slack.

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



