Analyze cryptocurrency price trends in real-time with Redpanda and store for further investigation in QuestDB.

Introduction
While Apache KafkaⓇ is a battle-tested streaming platform, as an engineer, I know too well how difficult it is to maintain and optimize Kafka (and ZookeeperⓇ). To simplify the development workflow for Kafka applications, and to reduce ongoing operational overhead, I’ve started using Redpanda. In addition to the benefits listed above, it’s also much faster than Kafka.
For a personal project, I’ve realized that open source Kafka may not be a great fit and decided to look for alternatives for an even simpler setup. Redpanda is an open-source, Kafka-compatible streaming platform that uses C++ and Raft to replace Java and Zookeeper. To see if Redpanda is truly compatible and easier to set up than Kafka, I decided to revisit my Kafka crypto project, which uses Python to send real-time crypto metrics into Kafka topics, store these records in QuestDB and perform moving average calculations with Pandas. This time, I will use Redpanda instead.
Project setup
At a high level, this project polls the public Coinbase API for the prices of various cryptocurrencies. This information is then published onto individual topics and sent to a time-series database (QuestDB) via Kafka ConnectⓇ. The only difference is that Redpanda will be used in place of Kafka and Zookeeper.

Fork the new repo on GitHub and follow along to replace Kafka with Redpanda.
Prerequisites
- Docker (with at least 4GB memory): if using Docker Desktop, go to Settings -> Resources -> Memory and increase the default limit from 2GB to 4GB
- Python 3.7+
Note: the Kafka Connect image is compiled for AMD64 architecture. While Docker may utilize Rosetta 2 to run AMD64 images on ARM64 architectures (e.g. Mac M1), it may have degraded performance.
Replacing Kafka with Redpanda
Clone the GitHub repo:
git clone https://github.com/Yitaek/redpanda-crypto-questdb
Inside of docker-compose.yml, replace the Kafka and Zookeeper sections with a one-node Redpanda cluster. We will leave the Kafka Connect with PostgreSQL JDBC driver and QuestDB sections intact, other than to update the broker hostname anddepends_on sections. The full snippet is shown below:
version: '3.7' services: redpanda: command: - redpanda - start - --smp 1 - --overprovisioned - --node-id 0 - --kafka-addr PLAINTEXT://0.0.0.0:29092,OUTSIDE://0.0.0.0:9092 - --advertise-kafka-addr PLAINTEXT://redpanda:29092,OUTSIDE://localhost:9092 image: docker.vectorized.io/vectorized/redpanda:v21.11.15 container_name: redpanda hostname: redpanda ports: - "9092:9092" - "29092:29092" kafka-connect: image: yitaekhwang/cp-kafka-connect-postgres:6.1.0 hostname: connect container_name: connect depends_on: - redpanda ports: - "8083:8083" environment: CONNECT_BOOTSTRAP_SERVERS: 'redpanda:29092' CONNECT_REST_ADVERTISED_HOST_NAME: connect CONNECT_REST_PORT: 8083 CONNECT_GROUP_ID: compose-connect-group CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1 CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000 CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1 CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1 CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter questdb: image: questdb/questdb:latest hostname: questdb container_name: questdb ports: - "9000:9000" - "8812:8812"
Note that the CONNECT_BOOTSTRAP_SERVERS now points toredpanda:29092 instead of broker:29092 and the depends_on section now just listsredpanda instead ofbroker (kafka) and zookeeper.
Run docker-compose up -dfrom inside of the docker-compose directory in the repo that you cloned from GitHub.
While waiting for the Kafka cluster to come up, watch the logs in the connect container until you see the following messages:
[2022-05-01 17:43:16,456] INFO [Worker clientId=connect-1, groupId=compose-connect-group] Starting connectors and tasks using config offset -1 (org.apache.kafka.connect.runtime.distributed.DistributedHerder) [2022-05-01 17:43:16,456] INFO [Worker clientId=connect-1, groupId=compose-connect-group] Finished starting connectors and tasks (org.apache.kafka.connect.runtime.distributed.DistributedHerder) [2022-05-01 17:43:16,572] INFO [Worker clientId=connect-1, groupId=compose-connect-group] Session key updated (org.apache.kafka.connect.runtime.distributed.DistributedHerder)
Configuring Postgres sink
At this point, we have a healthy Redpanda cluster and a running instance of QuestDB, but we need to configure Kafka Connect to stream Kafka/Redpanda messages to QuestDB. Since QuestDB supports the Kafka Connect JDBC driver, we can leverage the PostgreSQL sink to populate our database automatically. Post this connector definition to our Kafka Connect container:
# Make sure you're inside the docker-compose directory $ curl -X POST -H "Accept:application/json" -H "Content-Type:application/json" --data @postgres-sink-btc.json http://localhost:8083/connectors
The filepostgres-sink-btc.json holds the following configuration details:
{ "name": "postgres-sink-btc", "config": { "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "tasks.max":"1", "topics": "topic_BTC", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "connection.url": "jdbc:postgresql://questdb:8812/qdb?useSSL=false", "connection.user": "admin", "connection.password": "quest", "key.converter.schemas.enable": "false", "value.converter.schemas.enable": "true", "auto.create": "true", "insert.mode": "insert", "pk.mode": "none" } }
Some important fields to note:
- topics: Redpanda topic to consume and convert into Postgres format
- connection: Using default credentials for QuestDB (admin/quest) on port 8812
- value.converter: This example uses JSON with schema, but you can also use Avro or raw JSON. If you would like to override the default configuration, you can refer to Kafka Sink Connector Guide from MongoDB.
Note that this step is exactly the same as before. Since Redpanda is Kafka-compatible, we expect Kafka Connect to behave the same way.
You can check to ensure the connector is running successfully by issuing the following statement:
curl http://localhost:8083/connectors/postgres-sink-btc/status
Polling Coinbase for the latest crypto prices
To test if Redpanda works as advertised, let’s start our Python program to poll Coinbase. The Python code requires NumPy , kafka-python, and pandas to run. Using pip, install those packages and run the getData.py script (inside the root of the github directory):
$ pip install -r requirements.txt $ python getData.py
It will now print out debug message with pricing information as well as the schema we’re using to populate QuestDB:
Initializing Kafka producer at 2022-05-01 17:46:16.132079 Initialized Kafka producer at 2022-05-01 17:46:16.253645 API request at time 2022-05-01 17:46:16.331338 Record: {'schema': {'type': 'struct', 'fields': [{'type': 'string', 'optional': False, 'field': 'currency'}, {'type': 'float', 'optional': False, 'field': 'amount'}, {'type': 'string', 'optional': False, 'field': 'timestamp'}], 'optional': False, 'name': 'coinbase'}, 'payload': {'timestamp': datetime.datetime(2022, 5, 1, 17, 46, 16, 331331), 'currency': 'BTC', 'amount': 38458.25}} API request at time 2022-05-01 17:46:16.400579 Record: {'schema': {'type': 'struct', 'fields': [{'type': 'string', 'optional': False, 'field': 'currency'}, {'type': 'float', 'optional': False, 'field': 'amount'}, {'type': 'string', 'optional': False, 'field': 'timestamp'}], 'optional': False, 'name': 'coinbase'}, 'payload': {'timestamp': datetime.datetime(2022, 5, 1, 17, 46, 16, 400572), 'currency': 'ETH', 'amount': 2811.49}} API request at time 2022-05-01 17:46:16.540519 Record: {'schema': {'type': 'struct', 'fields': [{'type': 'string', 'optional': False, 'field': 'currency'}, {'type': 'float', 'optional': False, 'field': 'amount'}, {'type': 'string', 'optional': False, 'field': 'timestamp'}], 'optional': False, 'name': 'coinbase'}, 'payload': {'timestamp': datetime.datetime(2022, 5, 1, 17, 46, 16, 540512), 'currency': 'LINK', 'amount': 11.39}} API request at time 2022-05-01 17:46:21.321279 Record: {'schema': {'type': 'struct', 'fields': [{'type': 'string', 'optional': False, 'field': 'currency'}, {'type': 'float', 'optional': False, 'field': 'amount'}, {'type': 'string', 'optional': False, 'field': 'timestamp'}], 'optional': False, 'name': 'coinbase'}, 'payload': {'timestamp': datetime.datetime(2022, 5, 1, 17, 46, 21, 321272), 'currency': 'BTC', 'amount': 38458.25}} ...
Query data on QuestDB
QuestDB is a fast, open-source, time-series database with SQL support. This makes it a great candidate to store financial market data for further historical trend analysis and generating trade signals. By default, QuestDB ships with a console UI exposed on port 9000. Navigate to localhost:9000 and query Bitcoin tracking topictopic_BTC to see price data stream in:
select * from topic_BTC
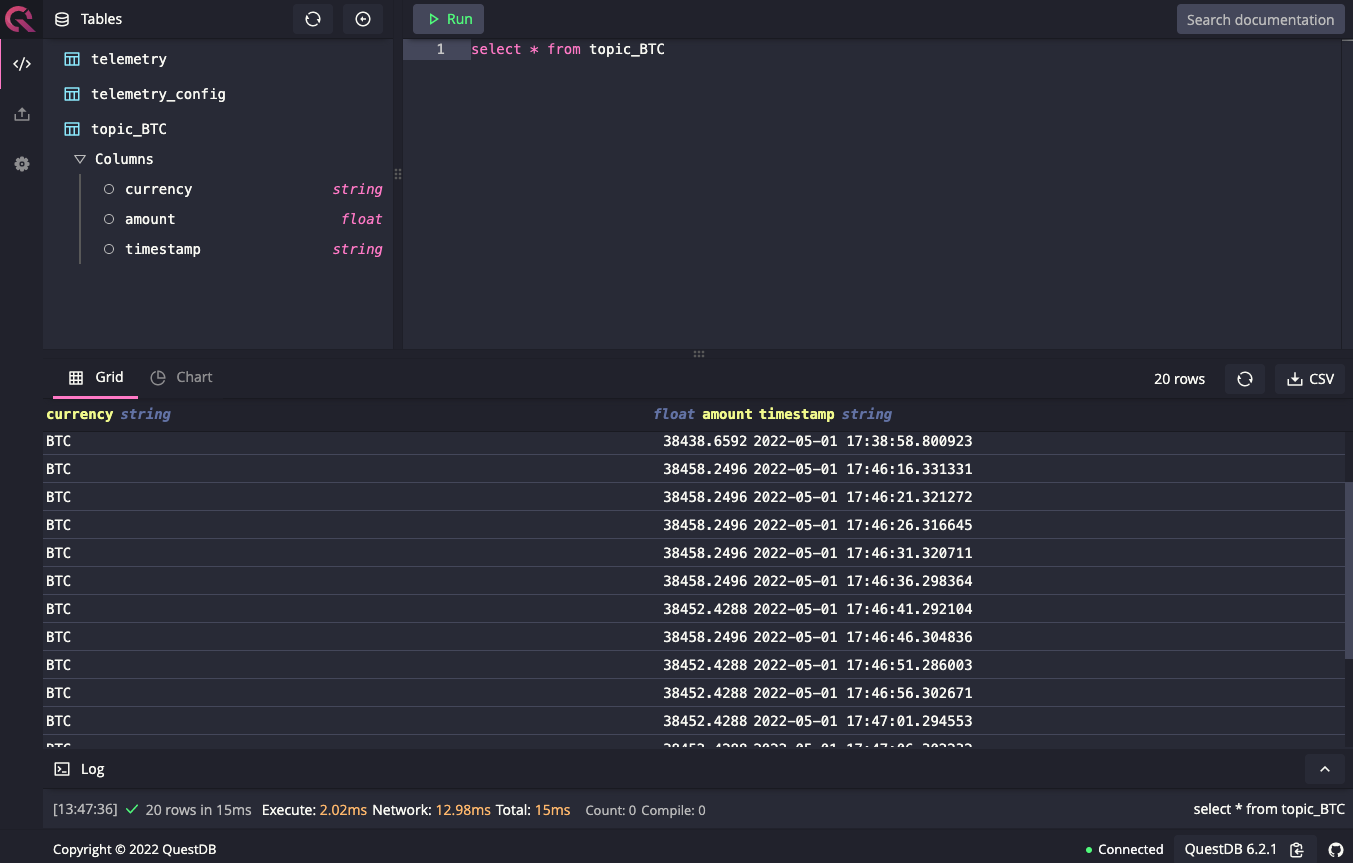
As expected, we see Bitcoin price data and timestamps published to QuestDB as we did before with Kafka. By configuring other topics, we can repeat this process for other cryptocurrencies like Ethereum or Cardano.
Also, to calculate a quick-moving average, we can still run the movingAverage.py script as well:
$ python movingAverage.py
This will print out the moving average of 25 data points and post it totopic_<crypto>_ma_25 (in our casetopic_BTC_ma_25):
Starting Apache Kafka consumers and producer Initializing Kafka producer at 2022-05-09 18:08:30.621925 Initialized Kafka producer at 2022-05-09 18:08:30.746186 Consume record from topic 'topic_BTC' at time 2022-05-09 18:08:31.968730 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.973713 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.975963 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.977655 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.979674 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.981067 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.982637 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.984000 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.985257 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.986333 Produce record to topic 'topic_BTC_ma_25' at time 2022-05-09 18:08:31.987514
To add these data points into QuestDB, we need to modify the code inside movingAverage.py to convert the format of the moving average data into one Kafka Connect can parse:
new_data = { "schema": { "type": "struct", "fields": [ { "type": "string", "optional": False, "field": "currency" }, { "type": "float", "optional": False, "field": "amount" }, { "type": "string", "optional": False, "field": "timestamp" } ], "optional": False, "name": "coinbase" }, "payload": { "timestamp": r['payload']['timestamp'], "currency": config['topic_4'], "amount": float(data_1['value'].tail(n=params['ma']).mean()) } } produceRecord(new_data, producer, config['topic_4'])
Then we need another connector postgres-sink-btc-ma.json:
{ "name": "postgres-sink-btc-ma", "config": { "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "tasks.max":"1", "topics": "topic_BTC_ma_25", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "connection.url": "jdbc:postgresql://questdb:8812/qdb?useSSL=false", "connection.user": "admin", "connection.password": "quest", "key.converter.schemas.enable": "false", "value.converter.schemas.enable": "true", "auto.create": "true", "insert.mode": "insert", "pk.mode": "none" } }
Attach to Kafka Connect via:
$ curl -X POST -H "Accept:application/json" -H "Content-Type:application/json" --data @postgres-sink-btc-ma.json http://localhost:8083/connectors
Finally, we should seetopic_BTC_ma_25 on QuestDB and can query accordingly:
select * from 'topic_BTC_ma_25';
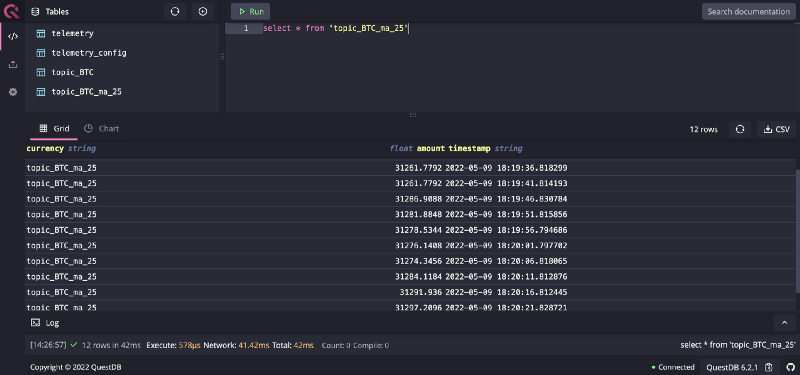
Initial impressions and alternative options
Redpanda’s blog has detailed information about the benefits of Redpanda over Apache Kafka, and my experience while writing this article was that spinning up Redpanda was faster than waiting for Zookeeper + Kafka. Redpanda’s compatibility with the Kafka API makes it easy to use Redpanda as a drop-in replacement for Kafka when developers don’t want to configure JVM environments or manage Kafka or Zookeeper.
There are many more real-time applications you can create with QuestDB and Redpanda. If you have questions about using these tools together, please ask in Redpanda’s Slack community. You can also contribute to Redpanda’s GitHub repo here.

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



