A promising experiment showing how Redpanda could power large-scale data streaming without breaking a sweat
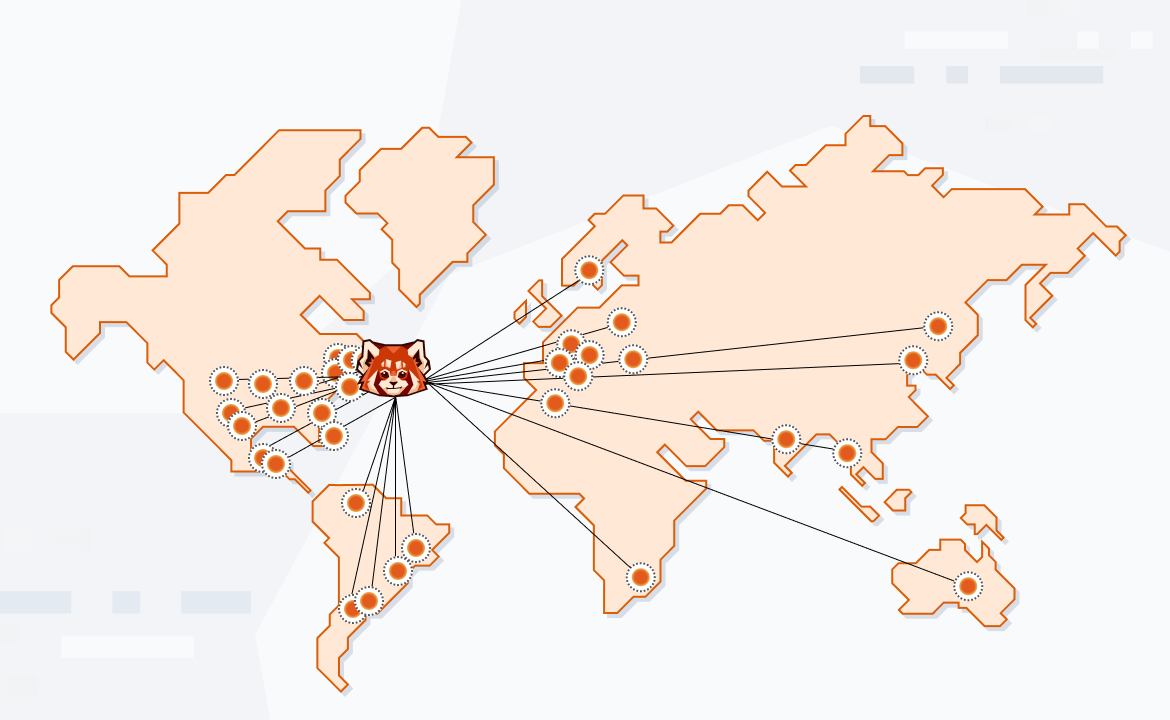
What kind of database do you use to serve records at extremely low latency, anywhere in the world, at the most absurd scale?
Say you are a DNS provider serving DNS records, a web host looking up routing configuration, fetching user feature flags, or an SSL termination gateway—you’ll want to have a reliable database.
In this post, I pair FireScroll with Redpanda for a multi-region performance experiment that showcases how it’s possible to reach massive scale and still maintain impressively low latencies. The entire project is in this GitHub repository. Before diving into the implementation, let’s get up to speed on the technologies and terminology involved.
The technologies
FireScroll
FireScroll is a highly available multi-region config database for massive read scalability with a focus on low latency and high concurrency. It allows you to have replicas in any number of regions without impacting write or read performance of other nodes—and without the headaches of traditional solutions such as complex multi-region networking and cold first-reads.
This makes it an ideal data store for configuration workloads that can tolerate sub-second cache behavior, such as:
DNS providers serving DNS records
Webhost routing (e.g. Vercel mapping your URLs to your deployment)
Feature flagging and A/B testing
SSL certificate serving
CDN mappings
Machine learning model features
Redpanda
For the uninitiated, Redpanda is the streaming data platform for developers. It’s API-compatible with Apache Kafka®—except 10x faster, 6x more cost-effective, and a whole lot easier to use. It’s built in C++, deploys as a single binary, and is essentially a drop-in replacement for Kafka. No ZooKeeper. No JVM. No code changes needed.
FireScroll relies on the Kafka protocol to decouple write operations, manage partition mappings to FireScroll nodes, and guarantee in-order processing of data mutations. I chose Redpanda over Kafka for its battle-tested performance and ease of use. It also makes it extremely quick and simple to set up a FireScroll cluster that spans regions around the world.
Badger
BadgerDB is an embeddable, persistent, and fast key-value (KV) database written in Go. It’s the underlying database for Dgraph, and designed as a performant alternative to non-Go-based key-value stores like RocksDB.
There are many KV options in the Go space, but Badger represents the ideal intersection between performance and developer experience. It provides the ability for serializable transactions and simple backup and restore processes while keeping an extremely high performance metric both for latency and concurrency.
FireScroll was initially built on SQLite, but its performance was less than Badger, and backup management was more difficult to control from within FireScroll.
The setup
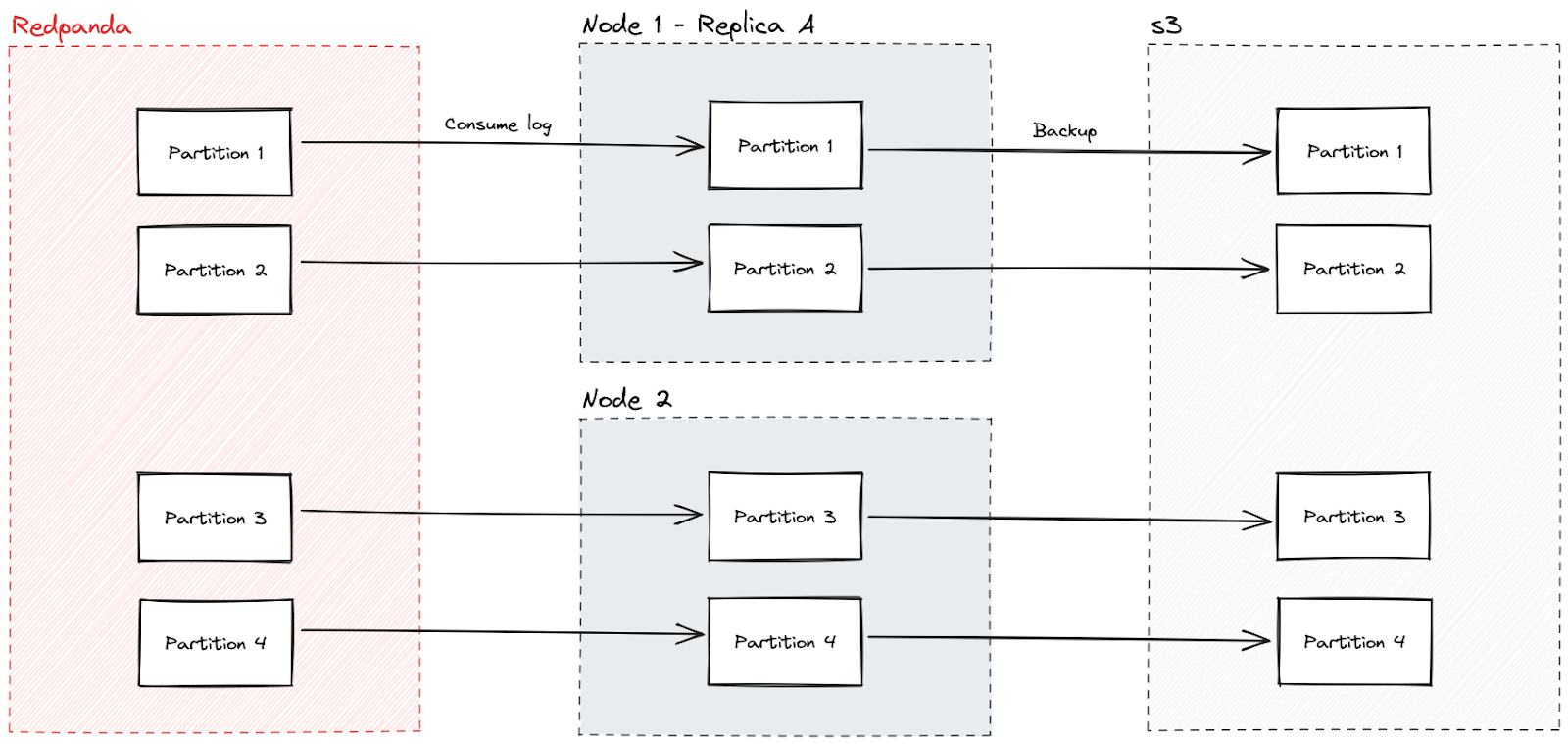
Essentially, Redpanda connects to Badger, where each topic partition is a distinct Badger DB that backs up to Amazon S3 and can be moved around different nodes.
Rather than having multiple nodes with each their own WAL, I used a single shared distributed WAL (which all nodes consume from) truncating to disk and backing up that snapshot to S3. This is so they can be restored on other nodes (rebalance and replication events) without needing to consume the entire WAL history, which is especially important to have a really short retention period on the WAL.
Components and terminology
To get the big picture, It’s a good idea to understand its individual components. Here’s what you need to know.
Namespace
A logical namespace of data that contains all the nodes and the Redpanda topic that’s used for mutations. Each node can belong to a single namespace.
Node
An instance of FireScroll that contains one or more partitions and consumes from Redpanda. Nodes run many micro-services internally such as the API server, the internal server, the log consumer, the partition manager, the partitions themselves, and the gossip manager.
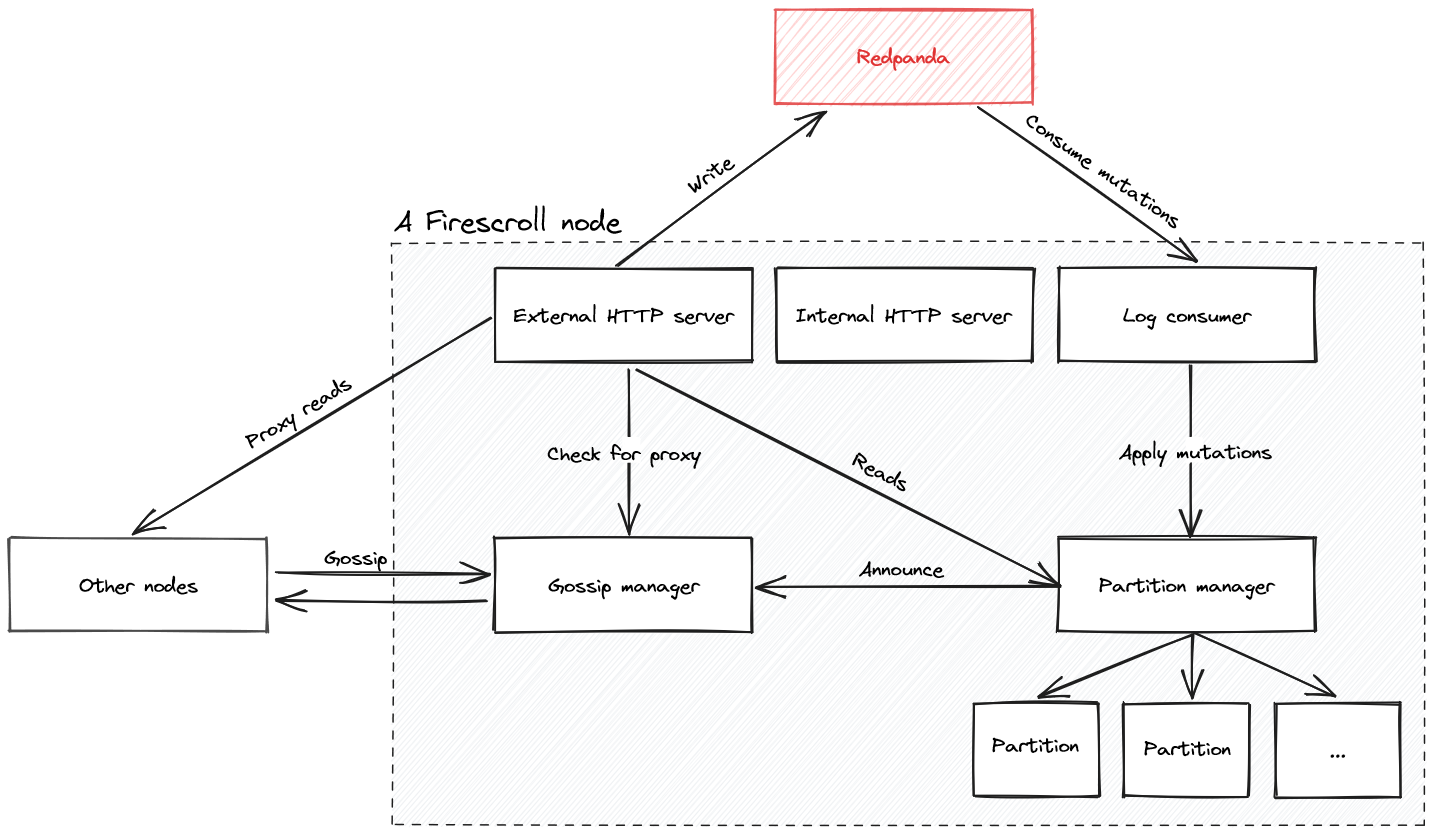
Nodes use the gossip protocol to communicate within the same region, which enables them to learn about each other and what partitions they manage. FireScroll uses this info to transparently proxy requests to the correct node as needed.
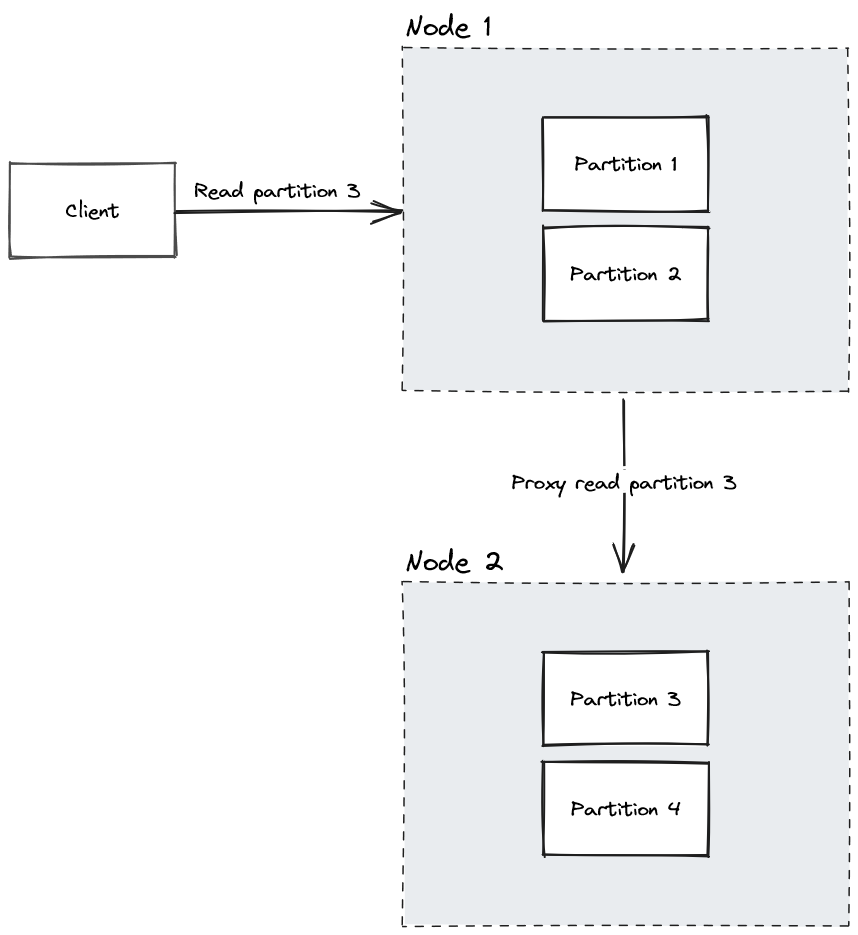
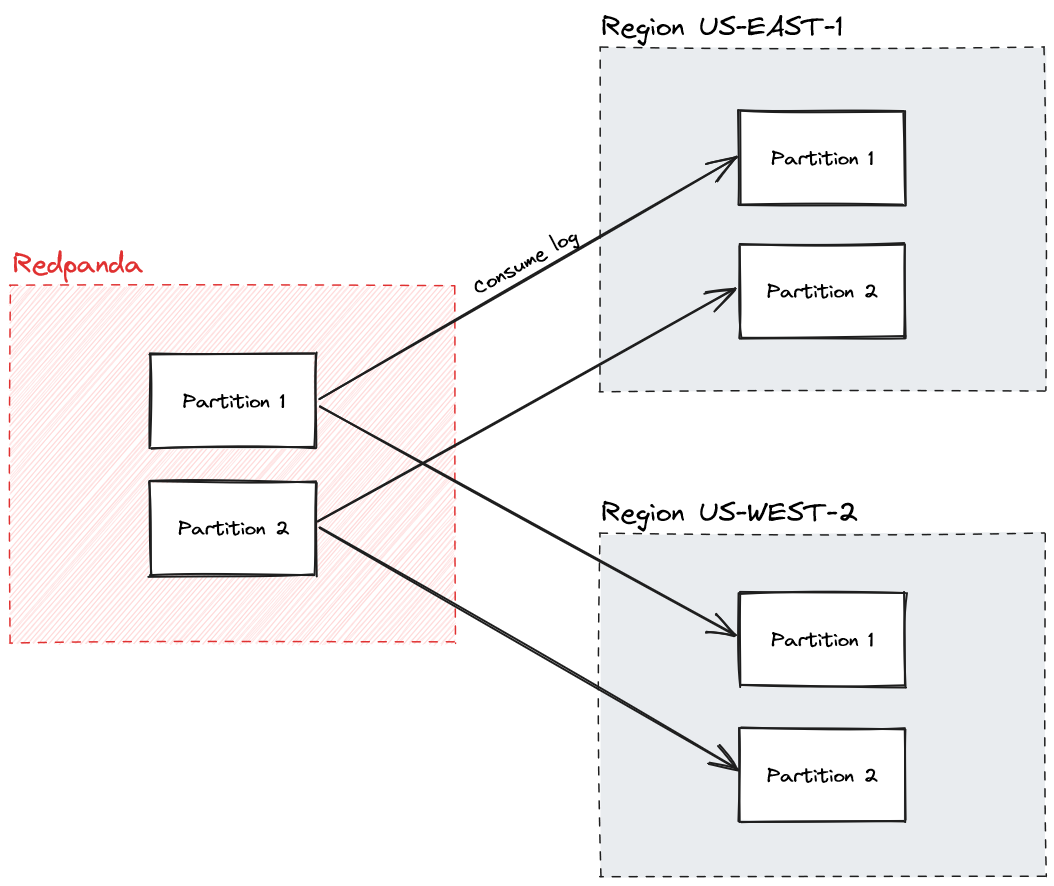
Replica group
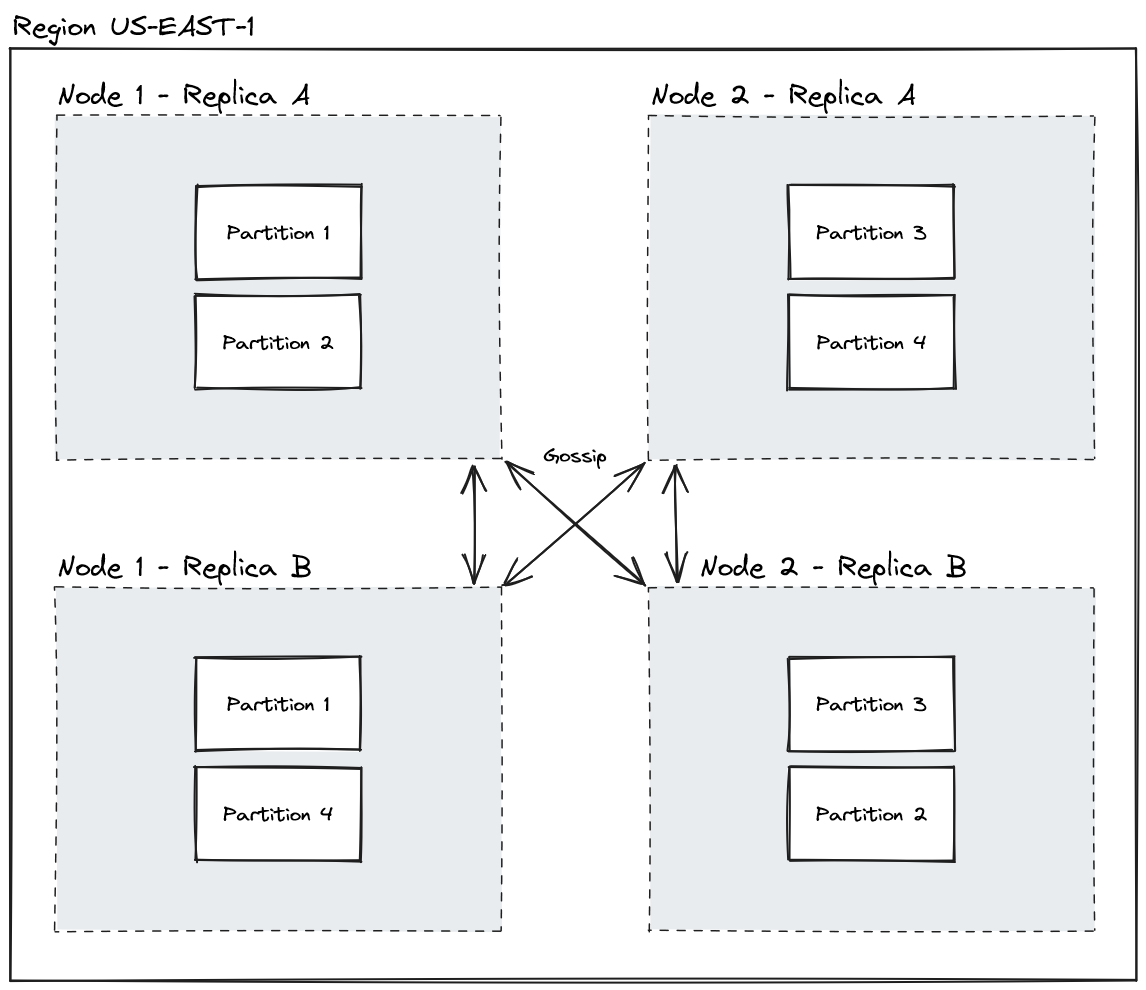
A node maps to a single replica group, which is just a Redpanda consumer group. Within a consumer group, Redpanda maps partitions out to a single consumer in the group. By having more of these in a local region, you get replicas of the data to increase both availability and throughput, since any replica of a partition can serve a read.
No need for N/2 + 1. You can have as many replicas as you want, since other than proxying “get requests” for remote partitions, they don’t have anything to do with each other. Any node can serve any mutation to Redpanda.
Partition
The smallest unit within FireScroll. A single mapping between a Redpanda topic partition and a Badger database. These can move from node to node, and all data is stored and backed up at a partition level.
Partition key
This is the key that determines what partition the record is placed in. For example, a domain name or a user ID.
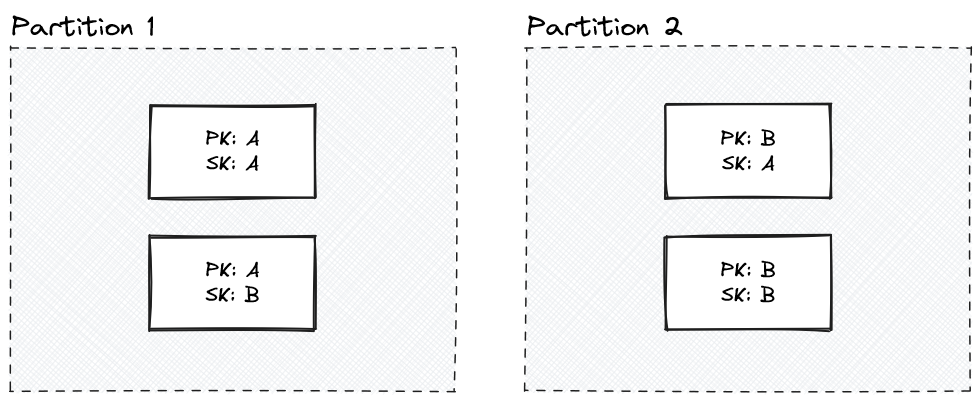
Sorting key
A secondary component of the primary key. This key determines how the record is sorted within the partition. Keys use the same semantics as DynamoDB or Cassandra/ScyllaDB.
Redpanda (the WAL)
The distributed WAL that nodes write to in order to quickly make mutations durable (put, delete). The beauty of this system is that we can get mutation-durable super fast while letting the downstream nodes read at their own pace.
That means that local nodes can get updates in ~15ms, while nodes on the other side of the world update in ~350ms, all without any additional strain on the system since no write coordinators are worried about timeouts and retries. Redpanda also manages the balancing of partitions among nodes for me! And since each partition is linearizable, it guarantees that all mutations to a partition are in the order it was submitted.
Region
A logical region where multiple nodes are hosted. This could be a cloud AZ or full region depending on your semantics. While FireScroll is not particularly aware of a region, it’s important that a region has its own set of replica groups.
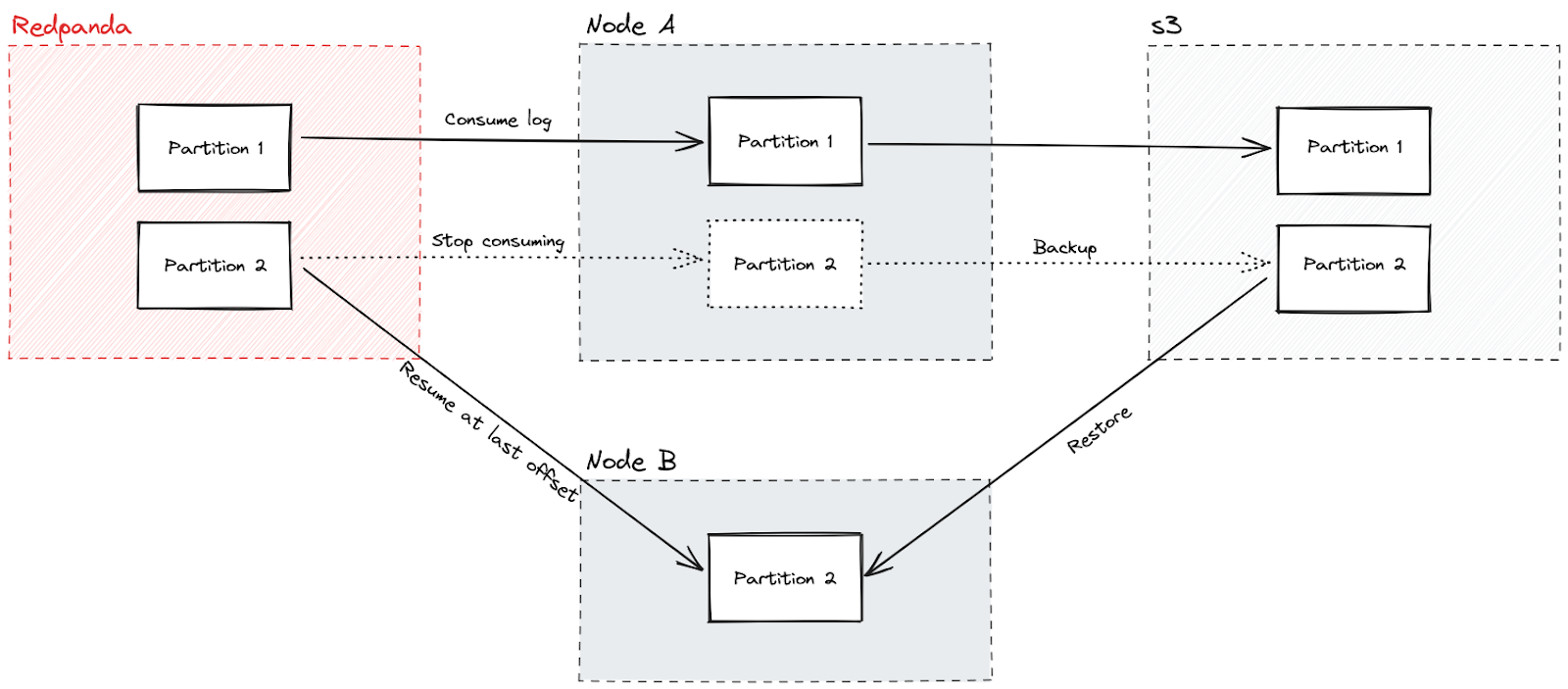
Backups and restoring
Nodes can optionally be marked to create and consume from backups. You specify an S3 bucket, whether you want to create backups, and whether you want to restore from backups.
This gives plenty of flexibility. For one, all regions have a single replica group backup to a regional S3 bucket for redundancy and low-latency restores. Plus, a single replica group in a single region does backups, and all other regions read from that, trading redundancy and speed for reduced storage costs and resource requirements.
When nodes restore a backup, they resume consuming from the last mutation included in the backup. Similar to how a traditional database will join the snapshot and the WAL to answer a query, FireScroll will use the snapshot and the Redpanda WAL to catch up to the current state quickly.
The test: promising performance across multiple regions
Now for the test. This spanned across 50 nodes in 32 regions around the world on fly.io. Each node managed three partitions, and I performed two tests:
Read three records per request, each from a different partition
Read a single record (one partition) per request
This was to test both the performance of Redpanda having so many consumer groups reading the log, as well as FireScroll being placed in distant regions.
Each node was a performance-2x (2vCPU, 4GB ram) size. Here are the results:
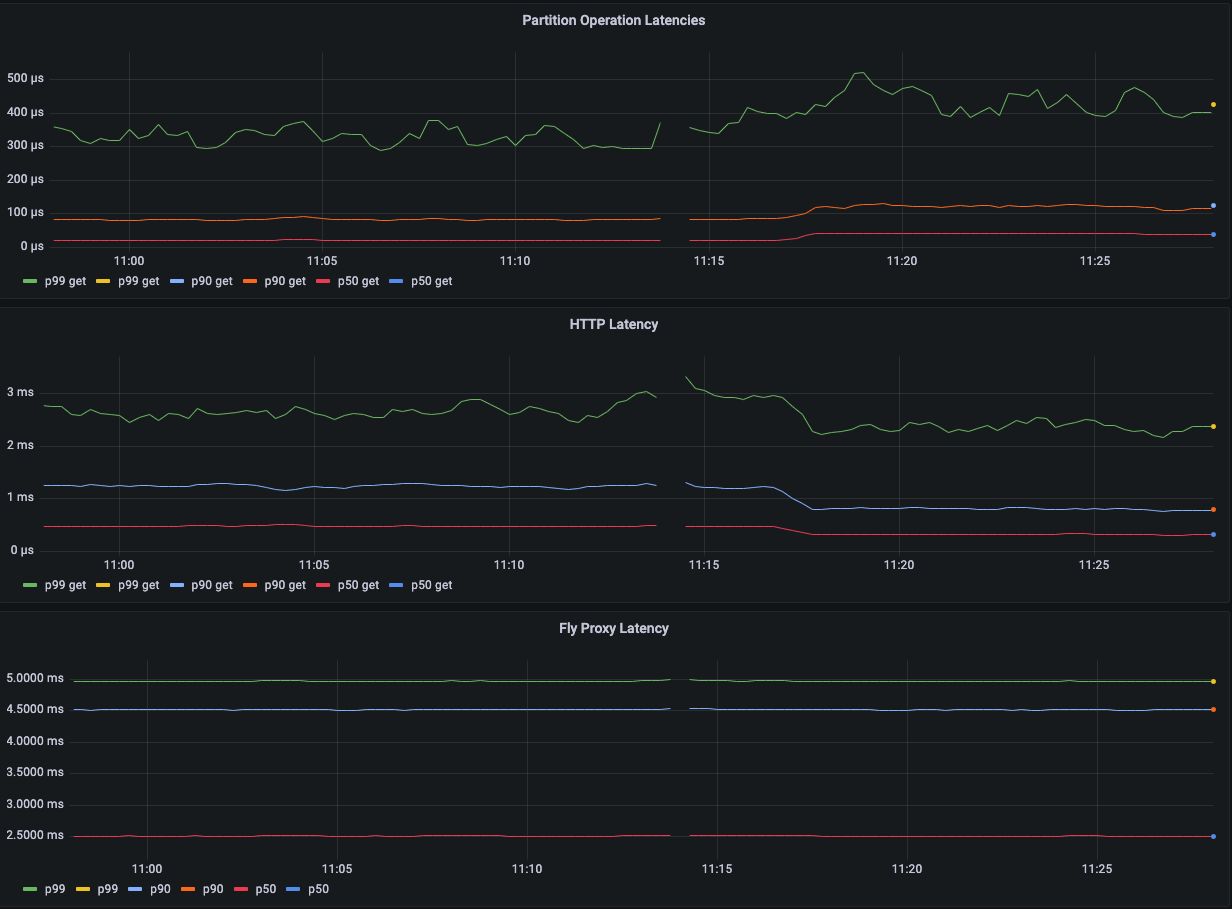
Due to account limits, I was only able to load it up to ~225 req/s per node from my laptop, as I wanted to use all nodes possible to run FireScroll and observe the behavior of high node counts.
Immediately, we can observe the following:
Fly.io disks are relatively high latency (my 2019 MBP p99 partition latencies are <75us).
Restricting the resources available increases latencies. On my 2019 MBP with 16 threads and 64 GB ram, I observed p99 get 1.2ms.
Fetching more records at once increases HTTP latency but reduces per-partition latency (this is predictable). You can see where I switched the test from fetching three records to one record. This is due to the additional work that is done per record (e.g. multiple deserialization operations, larger response body serialization).
Performance is still very good even when virtualized, with no memory caching, and fewer resources.
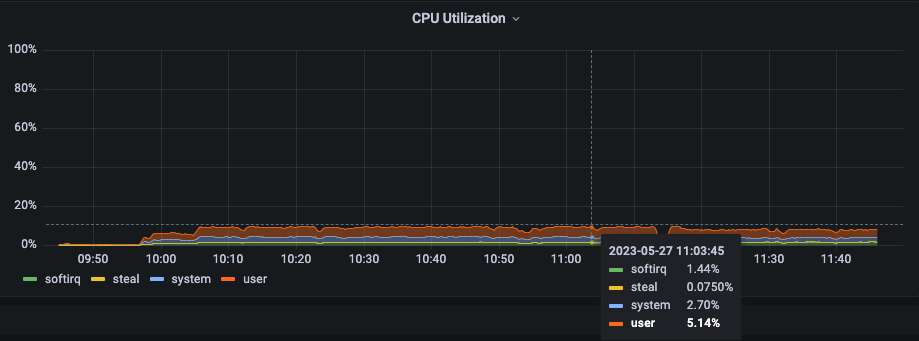
CPU usage remained low despite the significant load.
Redpanda was unbothered by this number of nodes, never exceeding 4% CPU usage on a single 4vCPU 16 GB node despite having nearly 100 connections.
Conclusion
In this post, I showed how pairing two high-throughput, low-latency technologies—FireScroll and Redpanda—can power seamless data streaming anywhere in the world, at any scale. This experiment basically inverted the traditional distributed database architecture. Multiple WALs usually mean you have to:
Sacrifice performance for consistency (as with CockroachDB)
Risk nodes being out of sync, sometimes permanently until repair (as with Cassandra).
Babysit the entire write lifecycle of all nodes involved, causing either performance or consistency issues.
All of the above sabotage scaling to hundreds of replicas. Instead, by sharing the same WAL, there’s no chance they get in a state of being permanently de-synced, and you don’t lose any performance for read throughput. Nodes aren’t responsible for keeping data persisted until remote replicas acknowledge a write to disk—which is complex and already handled by Redpanda.
With Cloudflare, Vercel, LaunchDarkly, or any other provider where read-after-write isn’t needed, optimizing for the 100,000,000:1 read-to-write ratio benefits from this infrastructure. No need for cascading replicas, VPC peering nightmares, or complex management solutions either—so it’s simple to scale!
What’s next?
Atomic batches - By submitting multiple “put” and “delete” operations at the same time, you can have them commit within the same partition atomically.
Incremental backups - While this isn’t a big deal with S3 retention policies, only backing up the changes since the last backup would be significantly faster.
A much larger scale test - I would like to write a test that focuses on high-node counts within a single region, with large replica groups. This is a more realistic test as regions don’t talk to each other, so we can test how requests are distributed in a high-density scenario.
If you have a question about this post, you can find me @DanGoodman in the Redpanda Community on Slack. Remember you can find this entire project in this GitHub repository. You can also check out the documentation and browse the Redpanda blog for real-world examples and tutorials.

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



