How a leading IT service company navigated the transition from Kafka to Redpanda for a low-latency, real-time alerting system

Equal Experts is a global IT services company with over 3,000 consultants who are highly experienced in bringing simple solutions to big business problems. As our mission is to create cutting-edge digital products and services, we pay close attention to what’s gaining momentum in the industry. Increasingly, our clients are looking to improve their data infrastructure to support more demanding real-time and event-driven applications.
For example, a recent client of ours in the FinTech space was building a flexible, low-latency market data alerting system. And, they needed our help to architect a system that would meet their stringent latency requirement—an average end-to-end latency of 10s of ms.
Ultimately, we architected a solution that met the client’s requirements using Redpanda, a Kafka-compatible streaming data platform that emphasizes simplicity, performance, and efficiency. Since the industry is continually shifting to event-driven applications, this post shares our experience choosing the best streaming data platform for the job, the key ingredients to successfully migrating from Kafka to Redpanda, and what you should consider before your own transition.
The challenge: balancing partitioning and performance
Originally, we proposed a real-time technology stack that included Apache Kafka®, Kafka Connect, Apache Flink®, KsqlDB, and Eclipse Vert.x. Part of the challenge was finding the right balance between topic partitioning and fine-tuning infrastructure. Having too few partitions in Flink meant that they couldn’t take advantage of data sharding; too many, and they created overhead with their Kafka metadata in Apache ZooKeeper™, resulting in performance loss.
The first streaming data solution we evaluated was a managed Kafka service, but we couldn’t hit our latency targets and quickly hit cost limitations from throttling due to KsqlDB transactions. When this solution failed, our client’s architect suggested Redpanda as a Kafka-compatible alternative with a smaller deployment footprint, no dependencies, and a C++ architecture designed to maximize the performance of your hardware.
Benchmarking Redpanda and comparing deployment models
Naturally, we benchmarked Redpanda against our baselines with Kafka, and we liked what we saw:
Redpanda achieved the low latencies that are usually only possible when running Kafka with no replication (a risky design choice for production workloads)
Redpanda’s lean design—a single binary that includes brokers, HTTP proxy, schema registry, and Raft replication—reduced the cognitive load on the operator maintaining the cluster.
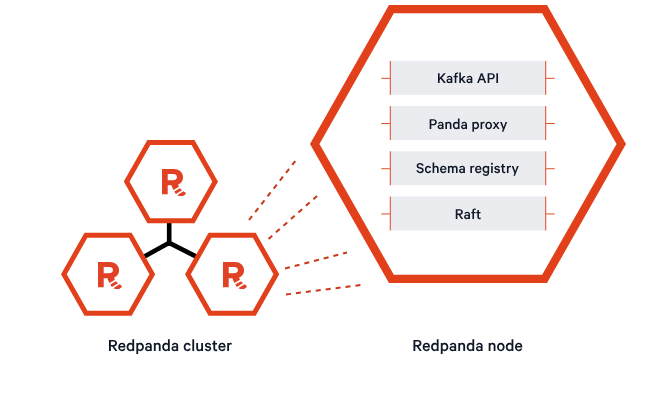
The conclusion was obvious, so we landed on using Redpanda as our streaming data platform. Next, it was time to choose the right deployment model. We initially considered Redpanda Cloud, a fully managed service, but we ended up choosing a self-hosted Redpanda Platform deployment so that we could have the most granular control over instance types and infrastructure.
For example, we wanted to run on EC2 versus Kubernetes so that we could leverage the ARM-based Graviton instances in AWS. Doing so would give us a 20% performance boost—plus a notably lower cost versus standard EC2 instances.
Migrating from Kafka to Redpanda
Redpanda is fully Kafka API compliant, which makes migrating from Kafka fairly simple. We were actually able to use the same versions of Java client libraries that we were using with Kafka.
It also helped that we had designed the overall system using loosely coupled microservices, so that future market data feeds could be added without changing the whole system. This modularity helped reduce the blast radius of changing a single component—in our case, the streaming data platform.
Inevitably, we did run into some learning curves. Namely with Redpanda’s SASL authentication mechanism, the Terraform and Ansible scripts for self-hosted nodes, the monitoring and metrics through Prometheus, and configuring the schema registry for disaster recovery. But these were all resolved with input from their engineers, who are always quick to help.
“At the end of the day, migrating to Redpanda was a quick win and we could now achieve the p99 topic hop latency the client needed for their real-time alerting use case.”
Planning to switch? Here’s what you need to know
We learned some valuable lessons during our successful migration from Kafka to Redpanda. If you’re planning to move from Kafka to another compatible system like Redpanda, here are some things to keep in mind:
Make sure to baseline the latency and throughput of the system you are migrating out of, to ensure you are improving performance with the target system
Load test the target streaming solution using different compute instance types and record the latency and throughput latency
Tweak the Kafka client configs to match your latency targets
Find the instance type that delivers the right cost and performance ratio
As the streaming data ecosystem continues to evolve, it’s more essential than ever to consider all available tools and find the best-of-breed option to support your specific project requirements. For us, that was Redpanda.
If you’re looking to transition or just want to see what the process entails, you can download this Apache Kafka to Redpanda migration report. If you have specific questions for the Redpanda team, you can ask them directly in the Redpanda Community on Slack.
About Eric Laguer, Principal Cloud Architect
Eric Laguer has over 15 years of experience building event-driven and service-oriented architectures primarily for financial services domains. Eric’s interests are in Kubernetes, Serverless architectures, embedded electronics, and computer-aided design. In his spare time, he enjoys playing hoops and tackling DIY projects.

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.



