The “secret” ingredient to building faster, safer, low-cost streaming data applications at scale

Streaming data is becoming increasingly important for businesses that want to draw instant insights from real-time events and transactions. However, streaming data also poses significant challenges in terms of scalability, reliability, and cost.
Redpanda is a streaming data platform that offers a different approach: a cloud-first storage model that leverages the elasticity and efficiency of high-bandwidth object storage systems.
In this post, we take you behind the curtain to learn how Redpanda's cloud-first storage model reduces the total cost of ownership (TCO) for streaming data by simplifying deployment, improving performance, and unlocking new application use cases.
What’s Redpanda’s “cloud-first” storage model?
Redpanda’s data storage architecture has evolved from cloud-native to cloud-first. This shift enabled Redpanda clusters to scale beyond the limits of locally-attached drives by leveraging cost-efficient cloud object stores.
This cloud-first storage model relies on Redpanda’s Shadow Indexing architecture, along with newly-introduced unified retention controls, to transparently move and govern data across local disks and a cloud storage bucket.
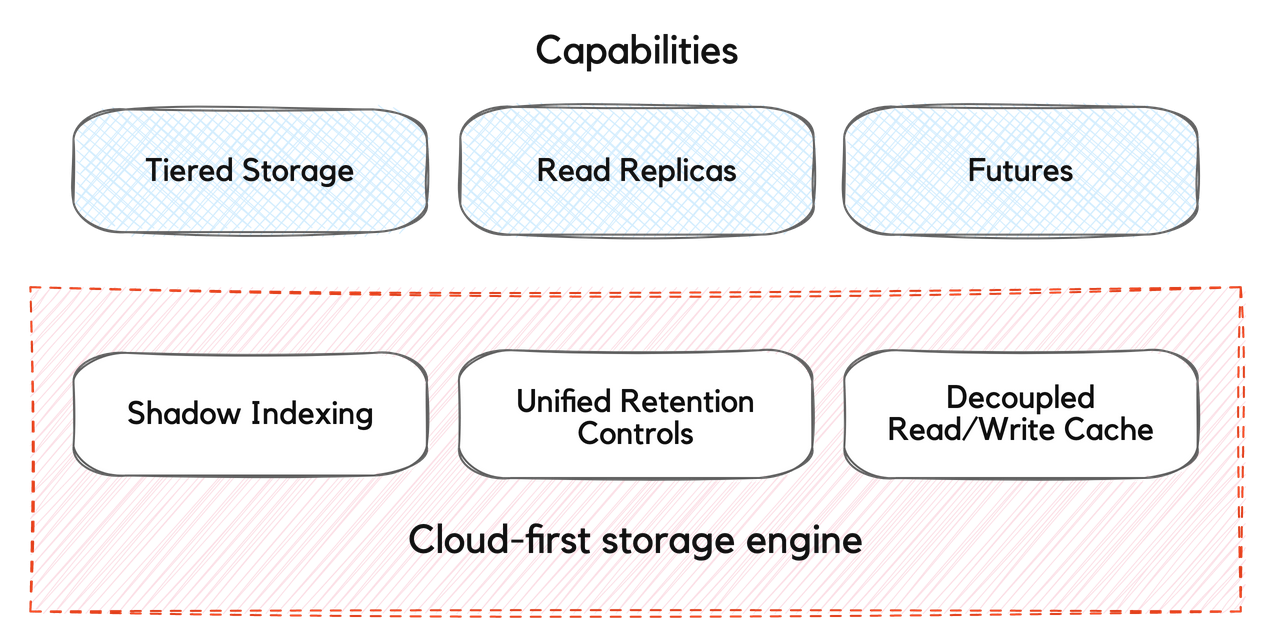
Achieving this storage model was quite the journey. Here’s a quick overview of the features we built on the way.
Archival Storage: The subsystem that uploads data to the cloud. The data in cloud storage includes topic and partition manifests that make them self-sufficient and portable. We then built topic recovery, enabling us to restore local topics from the archived data.
Shadow Indexing: We built this on top of archival storage and topic recovery, providing unified access to real-time and historical data using standard Apache Kafka®
Tiered Storage: Shadow Indexing powered the Tiered Storage feature released in v22.1, which archived topic data to cloud object storage and transparently managed data retrieval for Kafka consumers without inflating the cost of data storage. Tiered Storage treats the public cloud as the default storage platform for all streaming data. Meaning, Redpanda will first store incoming messages in a cloud storage bucket of your choice, while giving you the flexibility of retaining a portion of data locally for faster access.
Remote Read Replicas: The invention of Shadow Indexing was instrumental in rolling out Remote Read Replicas in v22.2. Remote Read Replicas are read-only topics on one cluster that mirror a topic on a different cluster. They can be used to serve any consumer without increasing the load on a primary cluster. When a user has a Redpanda topic with archival storage enabled, they can create a separate cluster for the consumer and populate its topics from the cloud storage.
With the Redpanda v22.3 release, the cloud became the default storage tier for Redpanda clusters. Administrators and application developers can apply standard Kafka data retention properties to customize the data retention behavior. Thus, existing applications can be deployed unchanged while leveraging cloud storage transparently.
What are the benefits of a cloud-first approach?
Redpanda’s cloud-first approach enables organizations to leverage the infinite capacity, high availability, and cost-effectiveness of cloud object stores to achieve new use cases, improve operational efficiencies, and reduce costs.
Let’s dive a little deeper into the benefits.
1. Cost-effective, infinite data retention on the cloud
Redpanda's Tiered Storage capability uses two storage tiers:
Fast (but expensive) locally-attached drives
Cheap cloud storage buckets
Tiered storage allows Redpanda to scale well beyond the finite capacity of your cluster. Since S3 storage is significantly cheaper than SSD/NVMe-based instances, you can use Tiered Storage to reduce cloud or infrastructure costs and the operational complexity of running a large Redpanda cluster sized simply for retention.
The built-in shadow indexer asynchronously offloads older log segments from local storage to S3-compatible object stores, such as Amazon S3, GCS, and Azure Blob Storage. Also, the data in the cloud storage buckets are fetched and served seamlessly when clients need them back. This makes tiered storage an obvious solution for data scalability in a cloud-native world, marrying fast-local access with long-term retention.
Furthermore, this storage model enables infinite storage of historical data in the cloud, opening the door to many AI/ML use cases. For example, you could use real-time data for fraud detection while using historical data for offline anomaly model training. The advantage is that Redpanda allows such consumers to consume both real-time and historical data via a unified access point, positioning itself as an engine of record.
In our Redpanda vs. Kafka TCO benchmark report, we ran Redpanda Enterprise, Commercial Kafka, Redpanda Community Edition, and Kafka without Tiered Storage. For each workload, we evaluated the potential infrastructure cost that would be incurred at one, two, and three days' worth of retention, with the relative comparison to running Redpanda Enterprise with Tiered Storage enabled.
The table below summarizes the results across all of the workloads.
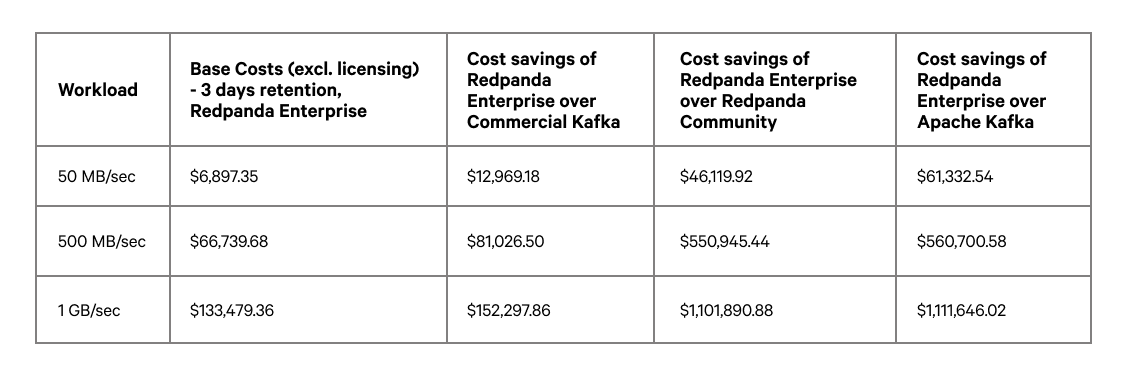
We can see that the cost savings of an Enterprise subscription can range from $70K up to $1.2M or higher for bigger workloads or retention requirements.
2. Build a global content delivery network (CDN) for data with Remote Read Replicas
In short, Remote Read Replicas act as a “CDN” for your streaming data without needing to invest in a global data replication mechanism. This reduces infrastructure and administrative costs.
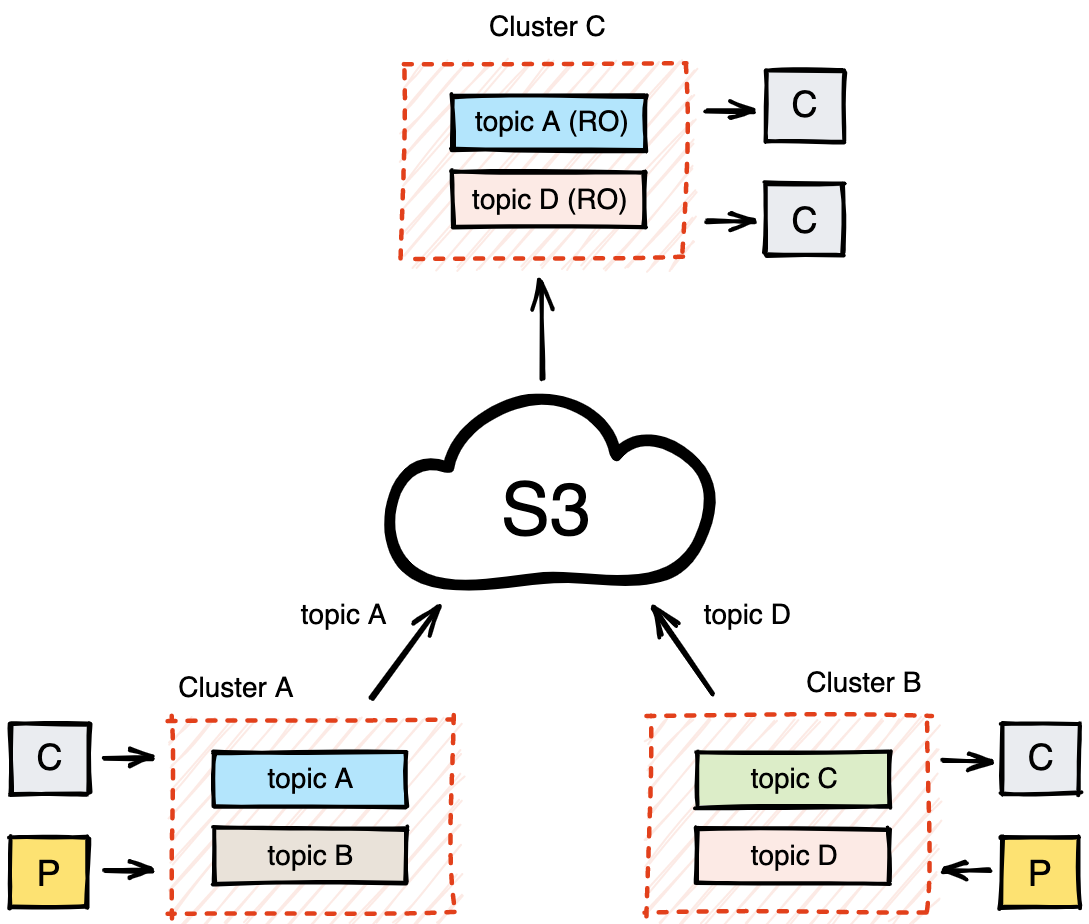
The longer explanation is that Redpanda’s cloud-first storage engine makes the data residing in a topic portable and self-contained. Each log segment offloaded to the cloud storage, including the unsealed segments, contains metadata and indexing structures to identify themselves. Later, another cluster can rebuild the state of the original cluster by re-ingesting (rehydrating) the log segments in the S3 bucket, regardless of whether the original cluster is still running.
Remote Read Replicas leverage this fast rehydration capability for mirroring selected topics of an original cluster into a cluster deployed at a remote location. For example, if you have a multi-region S3 bucket, data archived to S3 in one region will replicate to other regions, while Remote Read Replicas make it available to consumers from a Redpanda cluster that’s close by.
Moreover, if you have a multi-AZ or multi-regional use case where the data needs to be placed closer to your consumers, you can easily spin up Read-only Replicas at remote locations while the original cluster remains in the primary region. This reduces latency, eliminates operational complexity, and lowers the cost of having an always-on replication infrastructure.
3. Lower infrastructure costs for disaster recovery
The ability of fast rehydration of self-contained data in the cloud uncovers additional use cases, such as on-demand provisioning of active-passive disaster recovery (DR) clusters.
The fast rehydration implementation can quickly catch up with the original cluster’s offloaded state without downloading the entire data set from the cloud. Also, the new cluster will preserve the metadata and consumer offset coordinates from the origin cluster. These two features enable you to quickly spin up a DR cluster in a different region and have a smooth failover for existing consumers.
Additionally, on-demand DR clusters eliminate the need for maintaining a continuous data replication mechanism, such as MirrorMaker2.
4. Reduced administrative costs with automated data management
Manual administrative tasks for data management always depend on human labor, resulting in higher operational costs over time. Redpanda’s cloud-first storage model enlists several strategies to automate these tedious tasks as much as possible.
The data’s lifecycle in the early Tiered Storage implementation had to be managed separately from that of the data stored locally in a cluster’s storage volumes. For example, if you deleted a topic locally, its data had to be manually purged from the S3 bucket. Today, the Unified Retention Controls feature lets you enforce retention policies to local data as well as data in cloud storage buckets, enabling a unified data lifecycle management across the board.
Moreover, Redpanda’s Continuous Data Balancing constantly monitors cluster nodes, rack availability, and disk usage. This enables self-healing clusters that dynamically balance partitions to ensure locally stored data is evenly distributed across the cluster. That way, you can get the maximum return on investment (ROI) from your storage hardware. Collectively, the above features eliminate the need for cluster administrators manually attending to data management tasks—saving operational costs in the long term.
How does cloud-first storage reduce the TCO of streaming data?
The total cost of ownership (TCO) is a financial metric that measures the total costs associated with acquiring, operating, and maintaining a streaming data storage solution over its entire lifespan. TCO is the blended cost of deploying, configuring, securing, productizing, and operating the software over its expected lifetime, including all infrastructure, personnel, training, and subscription costs.
By calculating the TCO of different streaming data storage solutions, organizations can compare their options and make informed decisions that align with their business goals and budget constraints.
When we talk about how cloud-first storage reduces the TCO, we specifically look at three cost factors:
Data storage cost
Data transfer cost
Administrative and operational costs
In this post, we saw how Redpanda’s cloud-first approach addresses these factors through cost-effective data retention, using Remote Read Replicas as a global CDN for streaming data, lower infrastructure costs for disaster recovery, and automated data management to cut your admin costs.
What’s next? Paving the future of streaming data
Making cloud the default storage tier unlocks new streaming data use cases that were once considered out of reach. The long-term data retention capability encourages businesses to treat Redpanda as the “single source of truth” for their historical records.
However, the vision is to make the data in Tiered Storage even more portable and transactional, as well as improve its reliability by being compatible with popular table formats (like Apache Iceberg). Businesses can bring their own query engines to query the data without moving them across different systems, reducing their infrastructure footprint on analytics.
With cost-efficient storage and self-describing data in the cloud, businesses can swiftly move data around the globe to bring it closer to their customers. That also enables building global CDN for data without heavily investing in a conventional multi-regional data replication infrastructure. For example, the data produced in the North American region can be observed in a read-replica cluster in Europe, allowing real-time use cases like instant messaging and push notifications.
Conclusion
The innovative feature set associated with Redpanda’s storage model reduces the TCO in terms of data storage, transference, and data management—while also enhancing resource efficiency and fault tolerance.
The Tiered Storage capability, powered by Shadow Indexing, allows your clusters to grow beyond the limits of local disks while benefiting from cheap and more reliable cloud storage. Portable and self-sufficient log segments combined with fast rehydration open the door to many future-proof use cases, such as remote read replicas and DR clusters. Additionally, automated data management tasks eliminate the need for human intervention in cluster administration.
We have many more exciting features in the release pipeline, including multi-region clusters, to help you deploy a robust and scalable Redpanda cluster in production while reducing the storage TCO. Subscribe to the Redpanda blog to be the first to know about future releases, product updates, and tutorials on how to easily integrate with Redpanda.
Interested in testing out Redpanda for yourself? Take Redpanda for a spin! If you get stuck, have a question, or just want to chat with our engineers and fellow Redpanda users, join our Redpanda Community on Slack.

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.


