Learn how to optimize data ingestion, network, and storage when streaming data on Google Cloud Platform

Streaming data plays a pivotal role in applications and industries where real-time information powers monitoring and analysis in high-stakes industries like finance, healthcare, manufacturing, e-commerce, and other data-driven businesses. Cloud platforms, especially Google Cloud Platform (GCP), excel at processing and analyzing vast, fast-growing data.
GCP's scalability, cost-effectiveness, managed services, global reach, integration capabilities, security, and user-friendly interface make it a preferred choice for businesses of all sizes.
This post explores architectural considerations for managing high-volume streaming data on GCP. We'll explain deployment options — like Google Kubernetes Engine (GKE) and Google Compute Engine (GCE) — as well as storage solutions like Google Cloud Storage (GCS) and Local SSD.
To wrap it all up, we'll end with GCP's seamless integration with Redpanda and addresses data ingestion, network optimization, and storage strategies for high-volume streaming data.
What is high-volume streaming data?
High-volume streaming data refers to an ongoing flow of information generated at an intense pace from various sources, such as sensors, devices, applications, and social media platforms. It's distinguished by its high rate of data ingestion, high resource requirements, and difficulty in scaling.
These characteristics create unique challenges and opportunities in terms of data processing and analysis. For example, you may need to analyze user behavior on websites and applications that get millions of visits in a month in real time.
Here are the key characteristics of high-volume streaming data:
- High volume: Streaming data can reach a scale of petabytes in volumes daily. In such an environment, you must implement specialized infrastructure and processing techniques to efficiently handle the influx.
- High velocity: Streaming data often arrives quickly, in real time or near-real time. Processing and analyzing the data as it comes in, which requires low-latency processing capabilities, allows you to quickly gain insights and make timely decisions.
- Continuous stream: Unlike batch processing, which processes data in discrete chunks, streaming data flows continuously and requires continuous analysis to keep pace.
- Variety: Streaming data comes in many formats, such as structured, semi-structured, and unstructured information. You need flexible processing pipelines to effectively handle the differences among data types.
- Uncertainty: Streaming data may present unpredictable variance in volume, velocity, and data quality. This means you'll have to use adaptive processing techniques to keep up with changing characteristics in real time.
Optimizing high-volume streaming data ingestion
Optimizing high-volume streaming data ingestion involves making smart architectural choices, selecting an effective technology stack, and undertaking regular monitoring and maintenance activities. To get optimal results from streaming data ingestion, you also need to ensure that these strategies fit with your specific use case and data volume for maximum efficiency.
When developing an architecture for high-volume streaming data ingestion, you need to consider the following:
- Scalability: Your architecture should accommodate growing data volumes without incurring significant disruptions, and you should be able to add additional resources or nodes to handle additional data. GCP offers a comprehensive suite of scalability features and services that enable organizations to build and manage scalable, high-volume streaming data pipelines effectively.
- Throughput: For optimal data processing and timely completion of tasks, your architecture needs to have the capacity for rapid data ingestion. If your current architecture cannot process data fast enough, then an alternative architecture solution must be deployed as quickly as possible. GCP offers various services and features, such as BigQuery and Dataflow, that can address various aspects of throughput optimization, from data ingestion to processing and storage.
- Data source integration: The architecture should have seamless integration with multiple data sources, such as IoT devices, web applications, and external APIs. Furthermore, your system should allow different formats and protocols frequently found when streaming information, such as JSON data, HTTP Live Streaming (HLS) data, and so on.
- Data ingestion layer: You need to design an efficient data ingestion layer capable of collecting and processing incoming streams quickly and use tools for efficient information collection. Redpanda and Apache Kafka® are both open-source distributed streaming data platforms that can collect, process, and deliver real-time data streams.
- Real-time processing engines: Real-time processing engines such as Apache Flink, Kafka Streams, and Spark Streaming enable real-time data processing and analysis. These engines allow data to be processed as it arrives for quicker insights.
- Security: You should use security measures such as encryption, access controls, and authentication to protect data during ingestion, both in transit and at rest.
- Cost: It's important for architecture to be cost-effective, which means using resources efficiently while limiting unnecessary overhead expenses. GCP offers various cost optimization strategies and tools, such as tiered storage and data compression, to help organizations manage their high-volume streaming data costs effectively.
- Reliability: For maximum performance and uptime, architectures should be robust enough to handle unexpected increases in data volume or any disruptions that arise.
Given these considerations, Redpanda on GCP is an efficient platform for high-volume data ingestion that offers scalability, reliability, and availability. Google manages the Redpanda cluster, which means you can focus on app development.
The platform easily scales horizontally to accommodate increasing data volumes and ensures data integrity through replication and failover technology during node failures. Redpanda also maintains constant data availability through its distributed architecture to guarantee uninterrupted data ingestion and quick recovery.
The best part? Redpanda can seamlessly integrate with GCP tools like Cloud Functions, BigQuery, and Dataflow. For example, you can use HTTP to trigger Cloud Functions and directly stream and batch data into BigQuery tables.
GCP deployment and usage options
GCP offers different deployment options that can be used in various ways for high-volume streaming data. Google Kubernetes Engine (GKE) and Google Compute Engine (GCE) are two of the most popular options.
Google Kubernetes Engine (GKE)
GKE is a managed Kubernetes service that lets you deploy and manage containerized applications at scale using Google's infrastructure. You can easily scale your deployment by adding nodes or pods as necessary, and horizontal scaling ensures you can handle high data volumes. High availability is provided across multiple nodes and zones, so if one node or zone goes offline, Kubernetes automatically reschedules pods to maintain service continuity.
Google Compute Engine (GCE)
Google Compute Engine is a component of GCP that provides virtual machines (VMs) for running applications on Google's infrastructure. GCE gives you fine-grained control over cluster scalability by letting you manually add or remove VM instances as necessary. Users can choose from a variety of predefined machine types or customize their VMs based on specific requirements, such as CPU, memory, and storage.
High-volume streaming system storage solutions on GCP
GCP offers numerous storage solutions designed specifically to handle high-volume streaming systems efficiently in terms of data ingestion, storage, and processing.
Google Cloud Storage (GCS)
GCS is a scalable object storage service that accommodates large volumes of unstructured data, including log files, images, videos, and backups. It's a reliable and highly available storage option, which is ideal for streaming systems that need to store raw data ingested via their APIs.
Local SSD
Local SSDs are temporary block storage volumes attached to Compute Engine virtual machines that offer very high performance but may only last for a short time. Local SSDs are an ideal solution for streaming data that needs to be accessed quickly but will only remain there for a short time.
Network optimization strategies for high-volume streaming systems
As streaming data volumes continue to grow, you'll need to implement effective network optimization techniques to maintain system performance and prevent bottlenecks. The following are some effective network optimization strategies for high-volume streaming systems.
Use regional or global load balancers for proper traffic distribution
Load balancers distribute incoming traffic across multiple servers, which can help improve performance and reduce latency. For high-volume streaming systems, you should use regional or global load balancers to ensure that traffic is distributed evenly across multiple regions or data centers. This can help to prevent bottlenecks and ensure that users have a good experience regardless of their location.
Compress data at the source before sending it over the network
Compressing data can significantly reduce the amount of bandwidth required to transmit it over the network. This can be especially important for high-volume streaming systems. There are a variety of different compression algorithms, like gzip, that you could use for this purpose.
Implement a CDN to cache and distribute static content closer to end users
A content delivery network (CDN) is a network of servers that are distributed around the world. When a user requests a static file, such as an image or a video, the CDN will try to serve it from a server that is as close to the user as possible. This can help reduce latency and improve the user experience.
Use a network monitoring tool to identify and troubleshoot network problems
Network monitoring tools can identify and troubleshoot network problems, such as congestion and packet loss. This can prevent outages and ensure that your high-volume streaming system is performing at its best.
Establish VPC peering connections
Virtual private cloud (VPC) peering allows direct communication between different VPCs within the same or different regions.
For high-volume streaming systems with distributed components across multiple VPCs, establishing VPC peering connections facilitates efficient and secure data exchange. This strategy streamlines communication, reduces latency, and enhances the overall connectivity and collaboration between different segments of the infrastructure.
VPC for high-volume streaming data
VPC is a critical component of network optimization strategies for high-volume streaming data. It provides a secure and isolated environment for deploying and managing high-volume streaming data applications and infrastructure.
By using VPC features, organizations can achieve enhanced security, customizable network configuration, scalability, and more. VPC and shared VPC are networking options within GCP that allow you to set up and control isolated network environments for your resources.
VPC provides network isolation, which enables you to establish a dedicated environment for high-volume streaming data systems. Furthermore, with VPC, you have complete control over network architecture, such as IP address ranges, routing rules, and firewall rules. However, configuring and managing VPC is complex.
A shared VPC allows multiple projects to share a common VPC network — simplifying network management as resources and networking settings can be centralized. Furthermore, a shared VPC allows for consistent network policies and firewall rules across projects to provide uniform security configurations. Heads up: setting up a shared VPC can be complicated, and configuration mistakes or providing unintended resource access can result in mismanagement.
Strategies for storing historical streaming data
Storing historical streaming data requires specialized solutions for handling high volume, velocity, and timeliness while ensuring low latency access and cost-effectiveness. Strategies include the following:
- Structured data: For structured historical data, traditional databases or data warehousing solutions like Google BigQuery offer suitable structures with well-defined schemas.
- Time series databases: Dedicated databases like Google Cloud Bigtable, InfluxDB, or TimescaleDB can efficiently store and query timestamped data.
- Raw data storage: You can create a data lake on Google Cloud Storage for storing historical files directly and organize data into partitions or buckets based on a time range for efficient retrieval.
- Archiving: You can archive rarely accessed historical data to cost-efficient storage tiers from Google Cloud Storage, like Coldline or Nearline.
Redpanda's Tiered Storage also provides a practical and cost-effective solution for storing historical streaming data. It can seamlessly integrate with Google Cloud Storage and offers the following ways to optimize historical streaming data storage:
- Hot and cold tiers: Redpanda's Tiered Storage feature classifies data into two tiers: hot and cold. Hot data is stored locally within the Redpanda cluster, while cold data is moved to an external, cost-effective storage solution like GCS.
- Seamless integration with GCS: Redpanda tiered storage integrates seamlessly with GCS using connectors.
- Cost-effective long-term storage: Historical streaming data is automatically moved to GCS as it ages and becomes less frequently accessed. GCS offers cost-effective long-term storage options like Coldline and Nearline that reduce storage costs.
High-volume streaming data with Redpanda and GCP
Integrating Redpanda and GCP supports many of the strategies outlined above. To get an idea of how it works, here's a diagram that illustrates high-volume streaming data with Redpanda and GCP technologies:
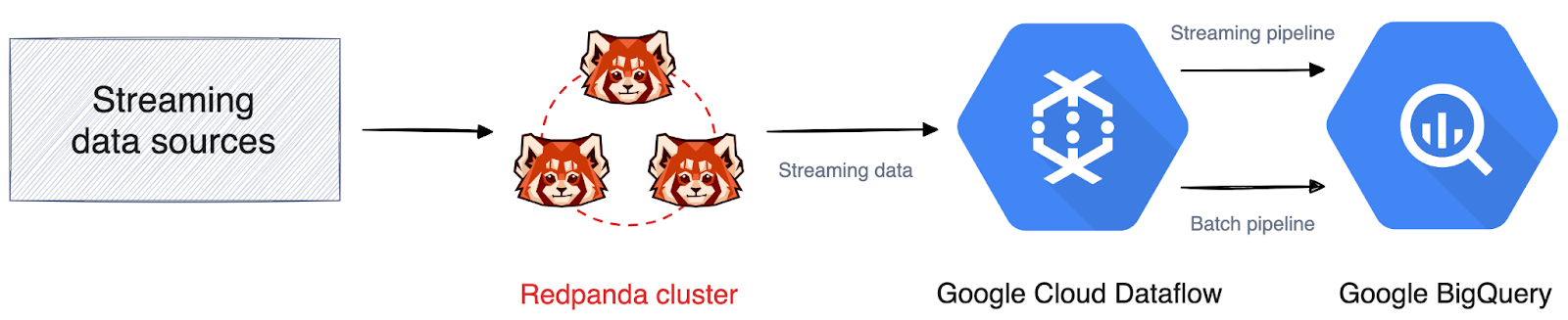
Architecture diagram for high-volume streaming data with Redpanda and GCP technologies
Redpanda handles the data ingestion and receives all the streaming data that needs to be processed. It then sends the data to Google Cloud Dataflow where it's processed and transformed in real time. The processed and transformed data is then loaded into Google BigQuery for storage and analysis.
This architecture ensures scalable and reliable streaming data ingestion, real-time processing, and storage in Google Cloud. If you're curious, we wrote a tutorial on how to stream data from Redpanda to BigQuery for advanced analytics.
Conclusion
Handling high-volume streaming data on GCP requires careful architectural consideration to ensure scalability, reliability, and real-time data processing. GCP offers many services and tools to meet this demand, but selecting the appropriate combination is crucial. In this context, Redpanda is a powerful high-throughput, low-latency stream processing platform that can seamlessly integrate with GCP.
To learn more about running Redpanda on GCP, browse our documentation and check out our Google BigQuery sink connector. Questions? Ask the Redpanda Community on Slack!

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.


